Hii,
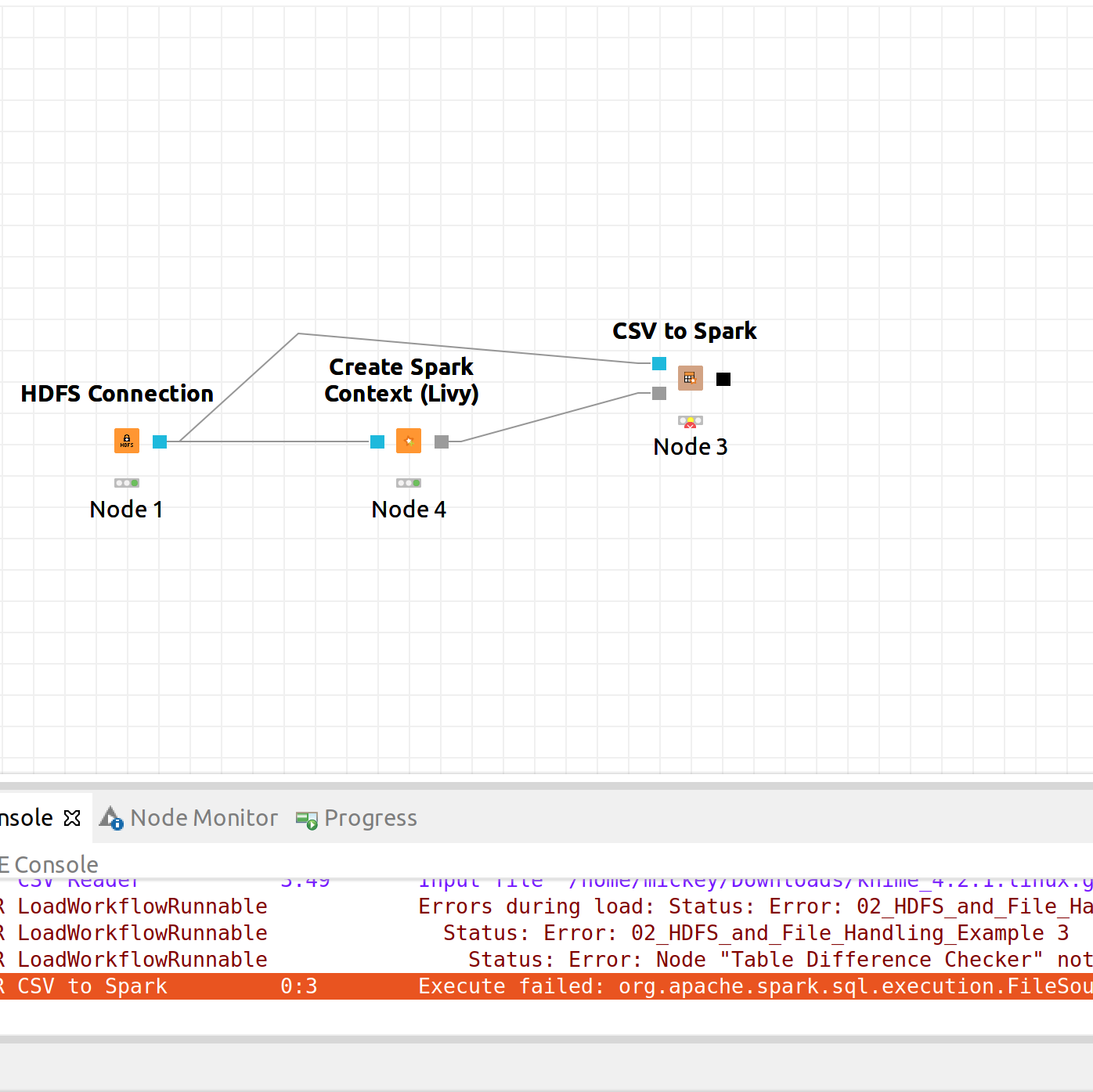
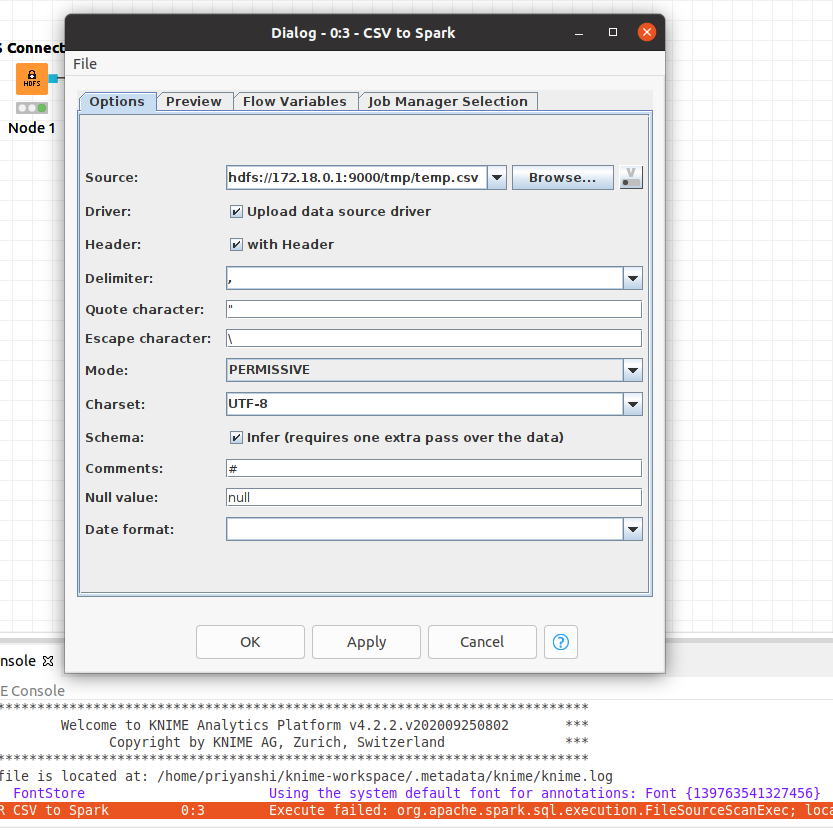
I am getting below error while executing ‘csv to spark’ node …
ERROR CSV to Spark 0:3 Execute failed: org.apache.spark.sql.execution.FileSourceScanExec; local class incompatible: stream classdesc serialVersionUID = 1920947604238219635, local class serialVersionUID = -3589590085483687218 (InvalidClassException)
Also attaching log file and workflow screenshots…knime_log.txt (19.3 KB)
I m using spark version 2.4 and livy 0.7 and knime latest version (4.2.1) , If these are not stable versions of spark & livy for knime 4.2.1 , plaese let me know the correct ones.
Could you first load the data into KNIME and see what types are there and what the Type mapping does say. Or if there are strange values with NaN(not a number).
Have you tried converting the integers to doubles (I am aware this sounds counter intuitive) and then upload the data. Maybe start with the numbers only.
And could you check into what type of variable your integers would be converted.
You could set the LOG level to DEBUG and try again. Maybe we could get an idea. It you could share a sample of the data that is failing that might also help.
Ok i ll try that too , but for now can you tell me how to connect table to spark node with ‘Hdfs connection’ node & ‘spark context’ node simultaneously which is possible with ‘csv to spark’ node as shown in my workflow…because the csv file I want to use is on hdfs .
Then you could try and tell Hive or Impala to treat it as an external table and load that into spark. You could declare the formats as string, int or bigint or double.