@gabrielfs2
Yes, it is possible to create Excel’s TRIMMEAN function in KNIME. I offer two possibilities below.
The TLDR:
- KNIME implementation of the node is here.
- Python implementation of the node is here.
I have included a Python implementation as there are many on the forum who are interested in developing nodes using Python and would like to see a comparison between the two approaches.
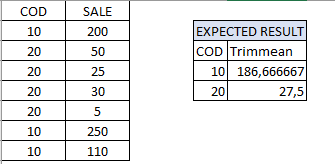
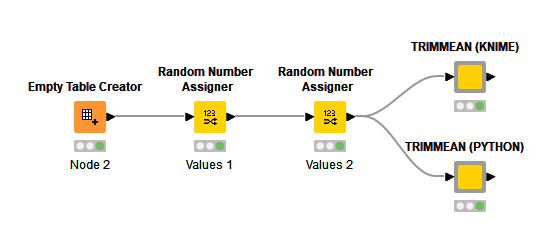
The basic test workflow, available on the hub, is shown below. An empty table is created with 3,000 rows. Then two random number assigners fill two columns with numbers between 0 and 1,000. This data is then fed to each node. The nodes have configuration to select the numeric columns for which TRIMMEAN is to be calculated and the percentage (as decimal fraction between 0. and 1.) of values to drop.
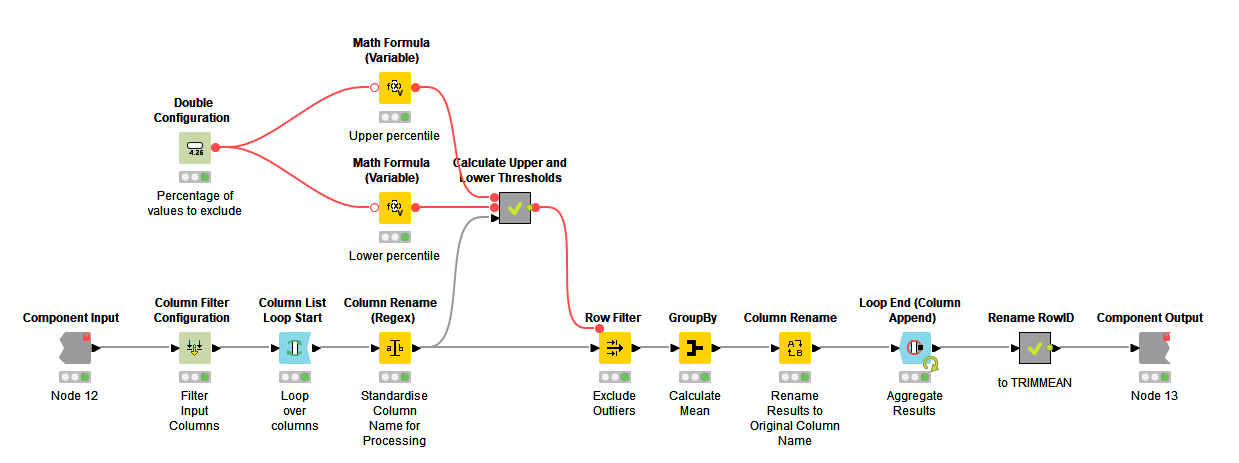
KNIME Component
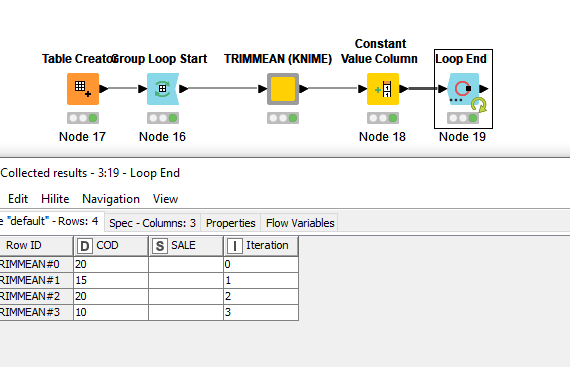
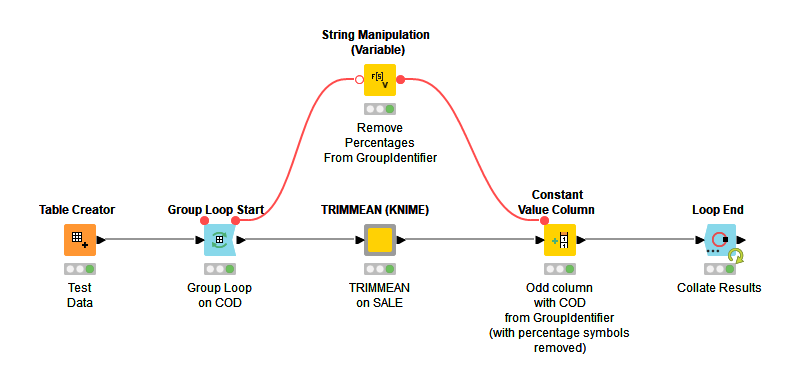
The KNIME component filters the input table and iterates over each column (blue nodes). The final metanode is to rename the RowID to TRIMMEAN.
The core of the workflow is:
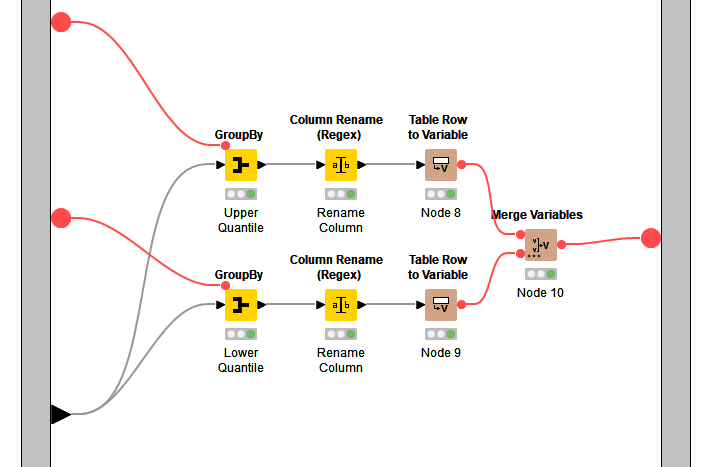
- Take the percentage of values to be removed p and calculate the upper (1 - p / 2)and lower quantiles (p / 2).
- These thresholds are then used in GroupBy nodes to calculate the threshold value for the quantiles. The manual aggregation method is
quantile and the threshold is set by a flow variable.
- Note, whilst calculating both upper and lower quartile could be done in one GroupBy node, it is very cumbersome to rename the output columns to distinguish the values.
- Second note, this workflow could be done without a loop, however, the quantile method requires parameters which cannot be passed as a set, therefore preventing programmatically selecting columns, methods and parameters at run-time (bit of a very very detailed implementation problem, so not relevant to most people).
- Once the upper and lower threshold values for the quantiles are calculated they are passed to a row filter to filter the data between these two values.
- A GroupBy node is then use to calculate the mean of the remaining values.
The column is renamed back to the original column name, and each column is then appended to the output data table.
Details of the Calculate Upper and Lower Thresholds metanode.
Python Component
The KNIME nodes in the Python version of the component are much simpler, consisting of configuration nodes and Python script node.
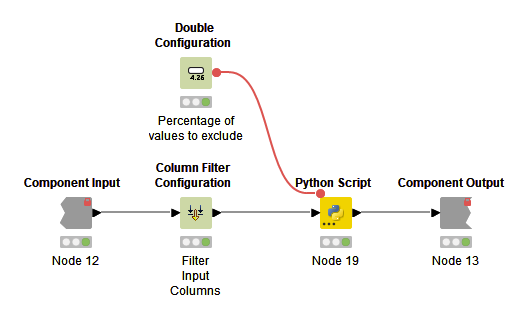
The Python script is below. The workflow is very similar to the KNIME workflow. When reading the script note the use of plurals. By convention, plural variable names are used in Python scripts to indicate multiple values (such as lists, dictionaries) whereas single values are not pluralised.
- The script imports the data into a Pandas dataFrame
df.
- It then calculates the upper and lower thresholds for each column in the dataFrame.
- It then iterates over each column creating a filter expression to filter the data.
- The mean is then calculated by taking the dataFrame
df, selecting the column in the iteration variable column, selecting the required values with filter and then calculating the mean .mean().
- The values are stored in a dictionary
trim_mean_values.
The only twist on most Python scripts implemented in Python nodes is that after converting the dictionary of TRIMMEAN values for each column the dataFrame is transposed to match the same format output as the KNIME node - if the data is not transposed then their is one TRIMMEAN column with a row for each column value.
import knime.scripting.io as knio
import pandas as pd
# Import data as a Pandas dataFrame
df = knio.input_tables[0].to_pandas()
# Calculate upper quantiles and value of upper thresholds
upper_quantiles = 1 - (knio.flow_variables['percent-to-excude'] / 2)
upper_thresholds = df.quantile(q=upper_quantiles, interpolation="linear")
# Calculate lower quantiles and value of lower thresholds
lower_quantiles = knio.flow_variables['percent-to-excude'] / 2
lower_thresholds = df.quantiles(q=lower_quantiles, interpolation="linear")
# Iterate over columns, filter data and calculate mean.
trim_mean_values = {}
for column in df.columns:
lower_threshold = lower_thresholds[column]
upper_threshold = upper_thresholds[column]
filter = (df[column] > lower_threshold) & (df[column] < upper_threshold)
trim_mean_values[column] = df[column][filter].mean()
# Create output dataFrame and transpose to match KNIME implementation
output_table = pd.DataFrame({"TRIMEMEAN" : trim_mean_values}).transpose()
# Export TRIMMEAN values on output port
knio.output_tables[0] = knio.Table.from_pandas(output_table)
Hope that helps
DiaAzul
LinkedIn | Medium | GitHub