Hi,
I was wandering, if there is a best practice section, where one could browse some common best practices.
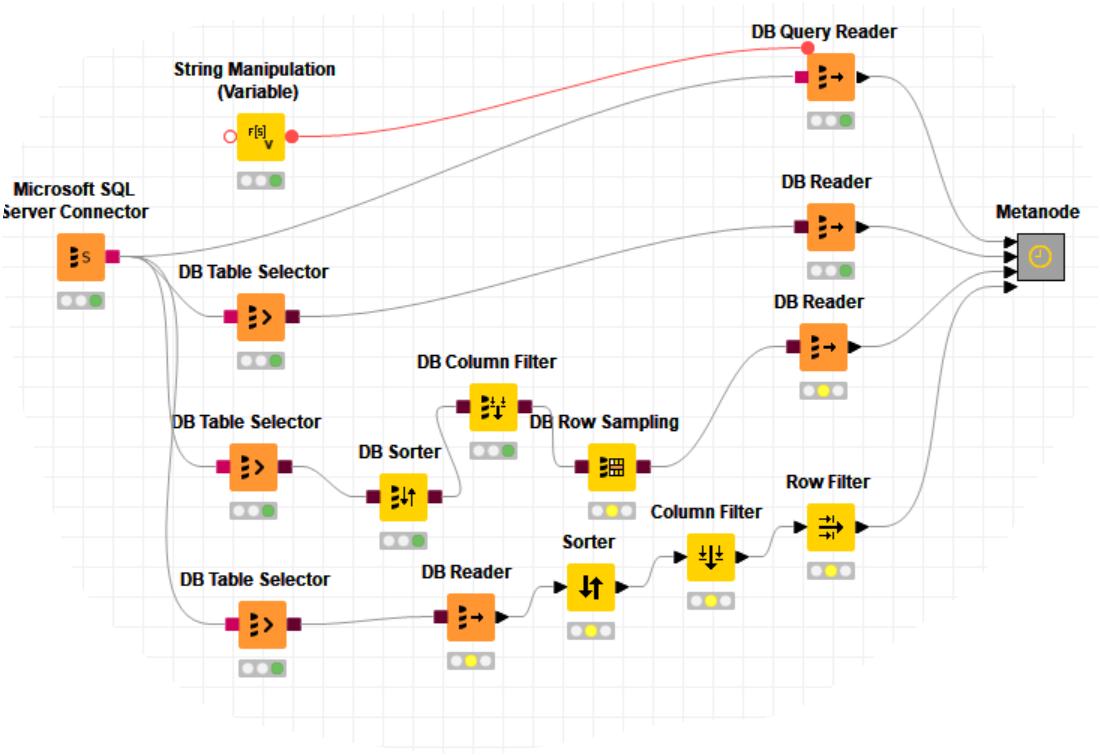
e.g. I got myself the question, how best to pull data from an SQL server. I came up quickly with four ways (for sure there are more ways).
create or pull the SQL statement from somewhere and call the statement right away via a variable.
Select a table, and within the DB table selector, make an SQL statement for filters etc. Then read the table.
None SQL solution, doing the transformations via KNIME NOTES before DB reader.
None SQL solution, doing the transformations via KNIME NOTES after DB reader.
Which way would be recommended and why?
How can I quickly test which way is faster? I guess they are not running in parallel with the constellation in this example.
@d00m I think this very much depends on what power you might get from your SQL database. If the data is very huge and you are able to use a lot of the ressources of the DB you might be better off to use that (think Big Data systems like Cloudera). If your data is small and you want to use the full power of KNIME nodes you might load the data into KNIME and process it there.
More examples about data bases can be found here:
A note about performance. The ‘brown’ connector DB nodes would create SQL-Views and they would then be executed on the SQL-DB. Now the performance very much depends on how your DB does handel such VIEWs. Spark eg. would use Lazy evaluation, some Big Data DBs might struggle to handel very complicated queries in one step while some ORACLE Db might have an integrated query optimizer that would help you. So you might have to work with intermediate data and make sure something like indices and statistics are also up to date since this might influence the performance.
It also depends on the power of your KNIME machine. If that is very powerful you might as well use that.
I also have seens combinations. You do some pre-processing in the SQL-DB (ETL) than load it into KNIME and use R to do some spcial tasks and than load the data back into a DB. Since KNIME is a platform it happily would integrate (and automate) all these tasks.
If you have further questions a good idea would be to open up new threads in this forum.
Although some general best practices could be written and maintained I find it hard to have this written more specific (e.g. how best to pull data from an SQL server) as it can be and usually is very use case/environment/Way of working/skills possessed dependent.