Hi there! I am a graduate student working on a final project (DUE Dec. 1, 2023) and need help troubleshooting issues I’m having with my KNIME analysis. My IC is not as responsive as I’d like, so I’m reaching out to the broader community for support. Would anyone be able to support reading my business objectives and reviewing my KNIME workflow to provide feedback? Thanks so much!
Hi @theumann
What kind of expertise do you need? That deadline is pretty tight and we don’t know from your description in which data area your project is. I would recommend to post these questions to the forum with clear guidance, example data, workflows etc.
Make a new thread per topic if necessary to avoid mixing different conversations. There are quite a lot of advanced users active on the forum with different areas of expertise so my guess would be that you are going to get help the quickest when doing this since everyone can jump in.
4 Likes
@theumann the Titanic case is one of the classic machine learning cases and discussions and solutions are out there, also it seems in knime.
Since this is an assignment and from what the descriptions imply some more advanced data preparation might be expected
You might have to tell us more about your specific task and think about how this will not just be a copy of an existing code.
One idea could be to transfer some advanced preprocessing to knime and discuss them.
You can always upload a workflow to the KNIME hub or the forum (How to Best Ask For Help on the Forum). And as @ArjenEX has said it would be best to ask specific questions.
1 Like
Here is a link to my workflow: https://hub.knime.com/-/spaces/-/~2dQmA1L5eEdH4qgJ/current-state/
For some reason, I am getting a scorer at 100% accuracy, which does not seem correct to me? This is also an attempt at creating a decision tree.
I am working with the titanic dataset trying to create a decision tree and my tree only has two branches, and the accuracy is at 100%. I am trying to troubleshoot where I could have gone wrong? Please see workflow here: https://hub.knime.com/-/spaces/-/~2dQmA1L5eEdH4qgJ/current-state/
The workflow is in a private space on the Hub. Can you make that public?
Sure, here you go: theumann/Public – KNIME Community Hub. My main questions were:
In the FINAL project node, I am getting a scorer that does not make sense to me, saying that the model is 100% accurate? Does this decision tree look correctly formatted based on trying to identify predictor variable impacts on survival rates?
Finally, is there a way to design these files where they can be combined into one final submission?
@theumann one thing is that you have a leak in your setup. You have the Target survived and you also have a string indicating the survival (the solution) in your data. This will lead to a useless model, unfortunately.
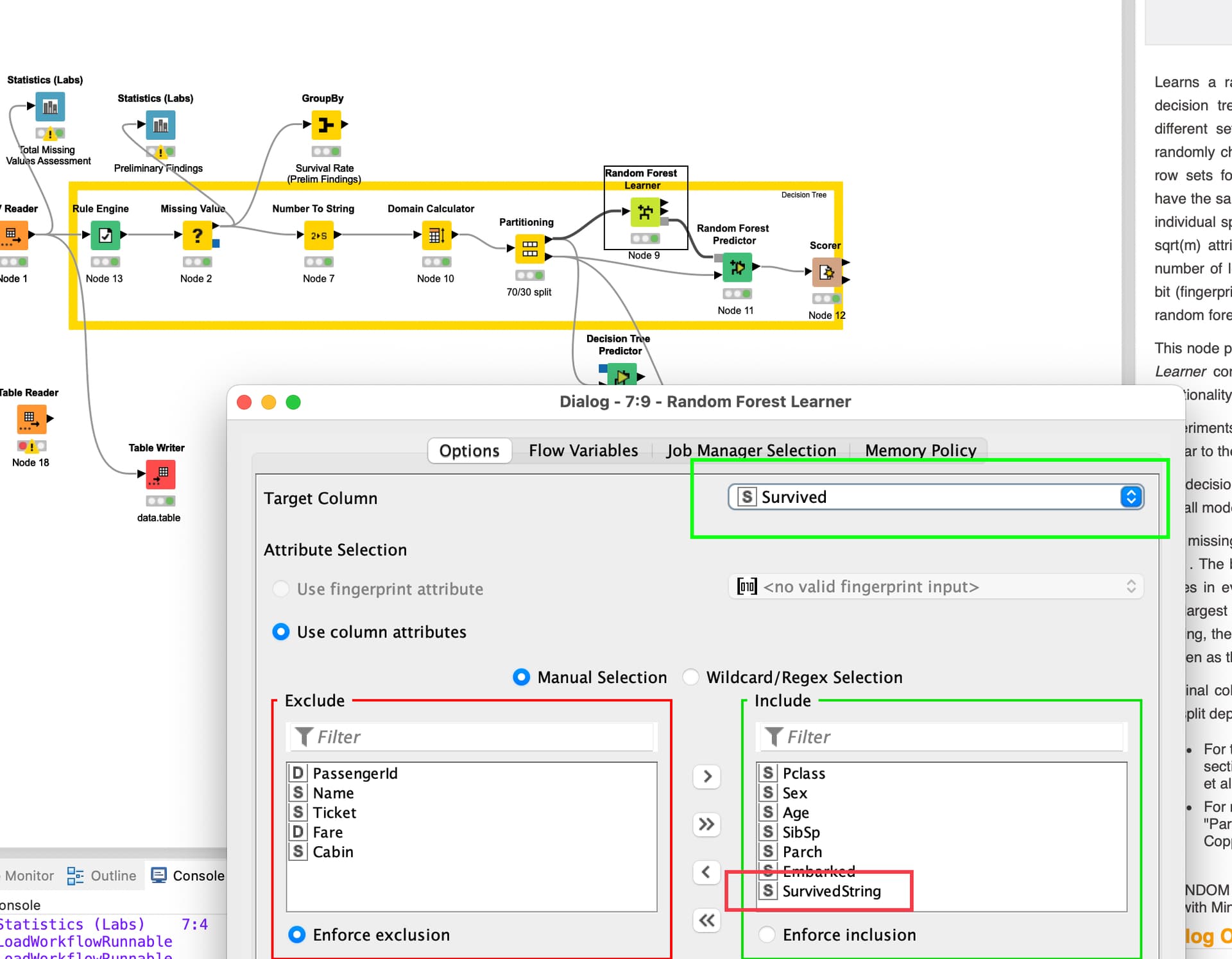
Then you seem to only have used the test dataset from the whole titanic dataset from Kaggle (Titanic - Machine Learning from Disaster | Kaggle) with 418 lines. Not sure if this is a deliberate decision.
5 Likes
I was able to work with my IC and figure this out! How do I delete this thread? I do not think others would find value in this commentary.
@theumann glad you found a solution. If you want to learn more about knime and machine learning here are some hints:
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.