To test that the workflow works well, i replaced the nodes to open ai nodes before the LLM prompter note to test out the workflow and i can see that i received a response after running the workflow. Refer to video recording: KNIME Analytics Platform - 12 August 2024 | Loom
However, after i replace the ai nodes with the LocalGPT4All Chat model connector and loaded my local LLama3 model, i noted that the output is “”. Instead of what i received when my open ai nodes were connected. Refer to video recording: KNIME Analytics Platform - 12 August 2024 | Loom
I would like to ask if the issue of “” output is it due to (1)the wrong LLama3 model i downloaded? (2) or the wrong configuration settings in my LocalGPT4All Chat model connector? (3) or simply the LLama3 model 8B is simply not good enough to process this workflow?
My “LocalGPT4All Chat model connector” can be seen in the video recording.
For my Meta-Llama-3.1-8B-Instruct-Q4_K_M.gguf, i downloaded it using LM Studio.
Additionally, i like to ask is there any knime connector that allows me to call my local LLM model such as the Meta-Llama-3.1-405B stored on a centralised server via API within my network without going out to the internet. Or can i store it in a file share so everyone of my team can access this model on a shared drive (not sure if its an efficient way as the model is so big).
I would like to explore using the most advance local LLM model but stored centrally so every member running knime can call it. Looking for the best solution to this.
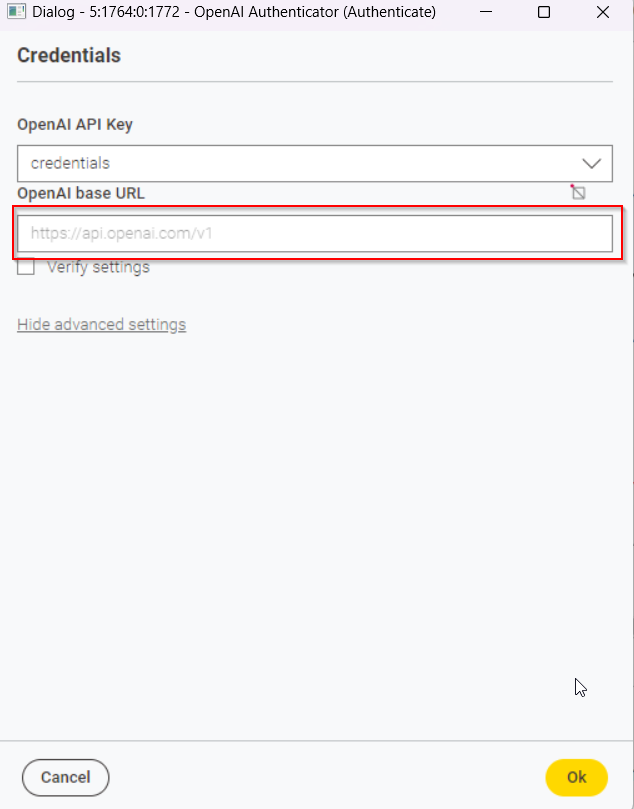
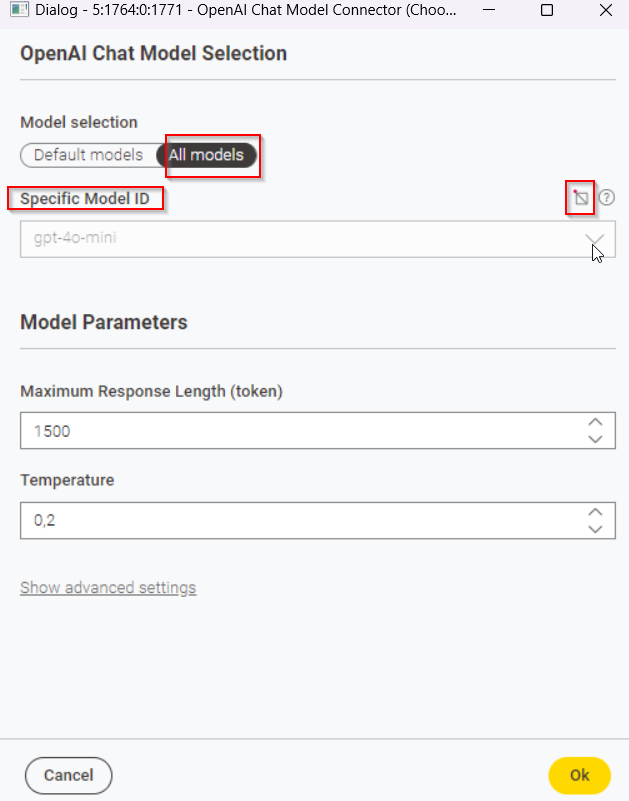
That is possible. You can change the base url in the OpenAI Authenticator node (1) to any endpoint that is compatible with the OpenAI API - e.g. instead of using GPT4All you can use LLM Studio to server your Llama3.1 locally and make it use the OpenAI API Structure. After providing the base URL in the authenticator node you then need to provide the model name in the OpenAI Chat Model Connector (2):
Cool i just downloaded ollama and llama3.1 8b model, its running so slowly its taking around 10mins based on a simple prompt which takes chatgpt4 only 1-3 second to run.
May I ask what hardware you are using and what OS you are on (Windows / MacOS)? E.g. I’m running a RTX 4060 laptop version with 8gb of VRAM on Windows and any model up to 8bn parameters typically is having decent response times…
A model that is personally like and is producing good responses despite being “smaller” is phi3 (4b)
May I ask if the speed at which the LLM is processed in this case is based on the hardware specifications of the server hosting Ollama? For example, if Ollama is hosted locally on my own PC versus being accessed via API from a server with better specifications, will the processing speed of the LLM change?
@bluecar007 the performance of a local llm will very much depend on the performance of your hardware.
Concerning ollama I have several examples how to use that with knime. A basic version without vector store will just use a REST-API query to connect to the service running the local llm.
Then i change the details for the first 3 node connectors from to connect to Ollama (model llama3.1:latest) via api hosted on my laptop. I ran the workflow and it took close to 17mins to run.
After that i change the ai connector to use chatgpt3.5 turbo and it took less than 30 secs to run the same workflow.
I have recorded it all down on video. Ollama (model llama3.1:latest) run uptill like 18-18.30mins of the video. Chatgpt3.5 turbo is the last 30 secs of the video.
Need some advise if i am using the wrong nodes or is my settings wrong? its strange the (model llama3.1:latest) run took so long just does not make any sense.
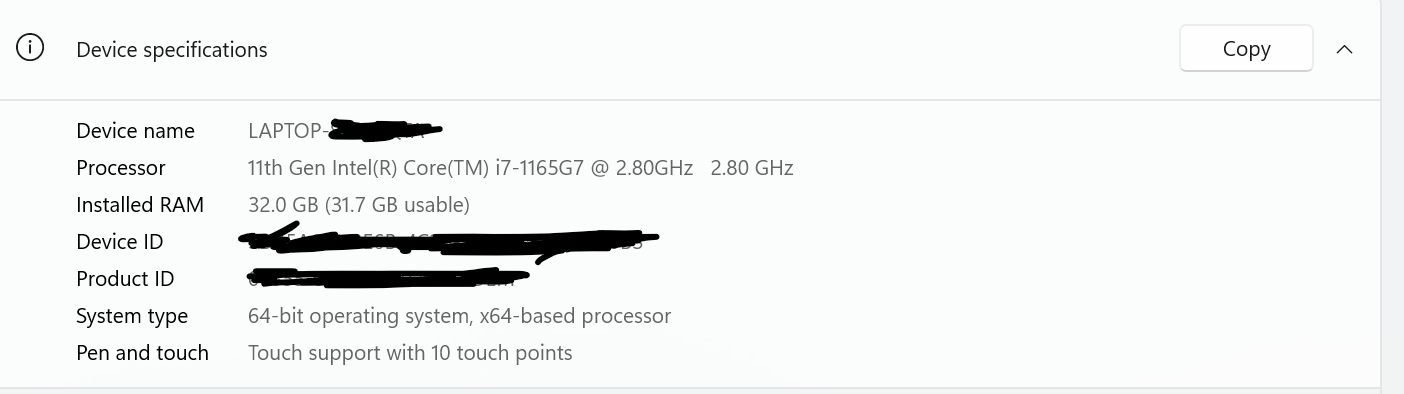
Anyway just uploaded my computer specs. I am using a Thinkpad X1
I was asking this question about hardware for two reasons:
to see if you have a GPU strong enough to run a 8b model with decent inference times
if 1) is a yes to identify potential problems Ollama may have in using that GPU
I’m afraid to say that without a NVIDIA GPU with at least 8GB VRAM it is not unheard of that it takes ages for a model running only on CPU to take ages… without GPU I don’t think you will get to acceptable response speeds when hosting locally.
Maybe check out huggingface.com if you can set up an endpoint via pay as you go to run opensource models instead…
@bluecar007 you will have to be clear about what is running on your machine and what is running on the infrastructure of OpenAI/ChatGPT - there will be massive differences. Also for the question of privacy if the data leaves your environment or not.
Also local models come in different sizes.
I have quite good local results with Apple Silicon machines, the M1-M3 processors which integrate GPU and CPU and which GPT4All can use.