I have a list of strings (per row around 2000 words)
Columns with words (around 300 words per column) which ones I have to compare with list of strings
Input from the user for number of hits that has to happen
What I want to do?
I want to compare each word from the list of strings with each word from the columns with words. How can I do that?
I want to optimize my search. How? Example: if word on position 133 in list of strings has a match with 53rd word from the column of words I want KNIME to check if user entered one hit has to happen or more hits are required…if just one hit is required I want that KNIME stops iterating over the rest of the list of strings. If number of hits is 2,3,4,5 or more, KNIME should continue iterating until the count of hits is the same that user entered.
How can I do that?
Example of solution for this would be amazing. Thanks in advance.
Interesting and challenging problem. Would you mind to share your data in a workflow ? It would make easier to understand the problem you need to solve and easier too to provide you with a solution.
I see what you mean now. Would it be possible to upload these two tables in a workflow here to which I will add the solution (or if you prefer in two separate xls files) please ? I believe that this can be solved without iterating over but I need the data to be sure of it and demonstrate how to do it.
Ich war zu aufgeregt, um eine Lösung vorzuschlagen, und habe meine eigenen Daten aus einer deutschen Zeitschrift generiert. Ich hoffe es ist was du erwartest
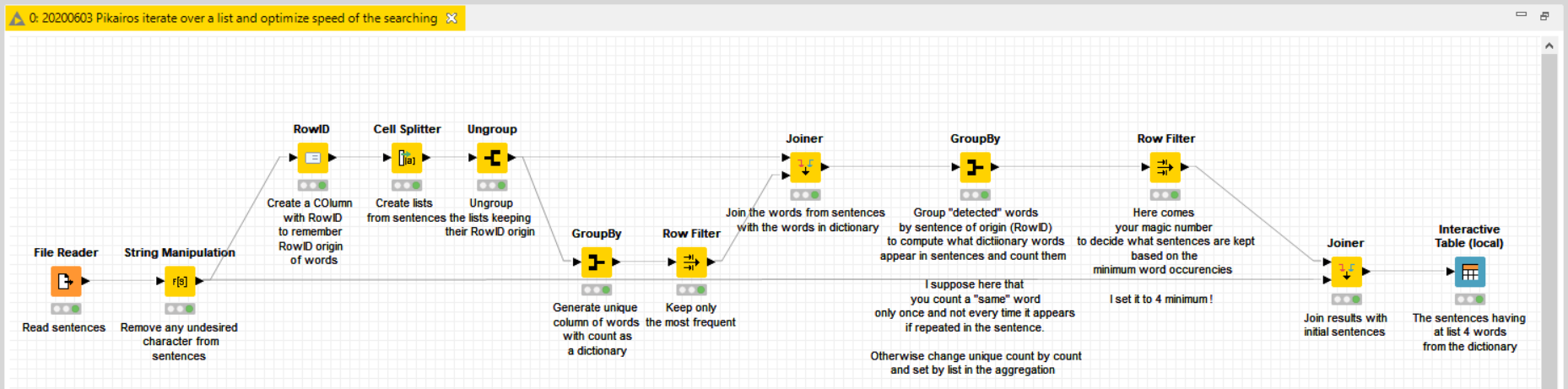
The solution (if I understood well your question, may be not ) may not need a loop, and could be implemented as follows:
I have modified the workflow to integrate your data. Unfortunately I see several problems:
The lists have been converted to strings so there is an ambiguity between the commas of your original sentences and the commas of list-to-string conversion. I have amended this to put them back to lists just to go ahead with the example. You will need to adapt this to your data.
The dictionary is not made of words but of sentences that do not match your items in the lists you provided. I have split it into words to make the example to work. This is something you need to clarify in eventually what you need to implement : Is your dictionary made of words or of sentences, and should your initial sentences be split into “sub-sentences” like in the dictionary or into single words.
Besides the previous problems, the dictionary you provided doesn’t cover enough words in your sentences so I had to set your minimum number to 1 to make the example to work successfully. This is again just for the example. You will need to adapt all this in your “real world” implementation of this solution.
Your tips and tricks are literally amazing! Vielen herzlichen Dank
I needed some time to actually understand what is happening in your test workflow but I understood everything and implemented it into my project! Your comments are very helpful!
One last question for you:
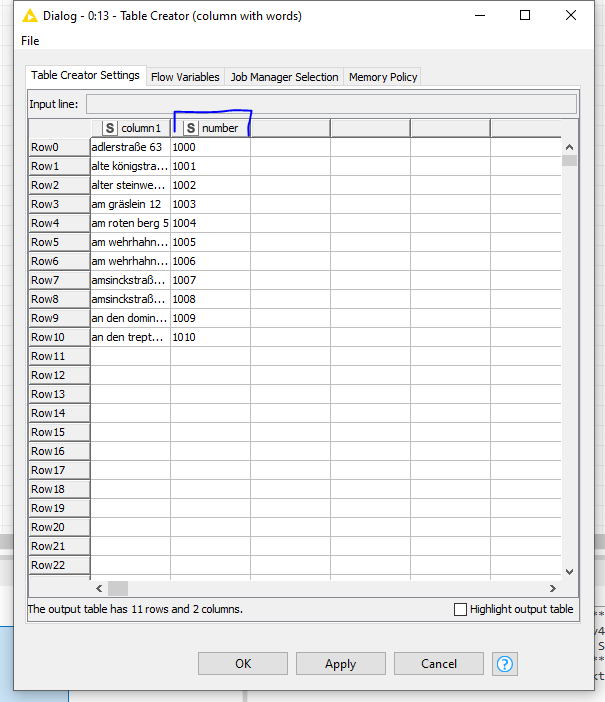
I added an extra column in Table Creator “column with words” called “number”
How would you implement this: if there is a big enough number of hits between the words that we compared (by number I still mean the same number from the user input) I have to upload the value from extra column that I added previously.
Here is test example from my workflow: test2.knwf (11.4 KB)
And to clarify one more time what is my question using the very simple example:
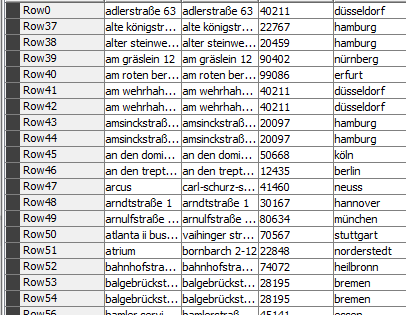
If “adlerstraße 63” can be found in first/second/third etc etc list of strings that I have and also I have enough number of hits, then value from column “number” (in this case it is value of 1000) has to be uploaded to the API. I know how to upload my data to the API, I just have problems with getting the value from column “number” and writing propper filtering for this workflow.
If you need any extra explanations, I am here to answer them as soon as possible.
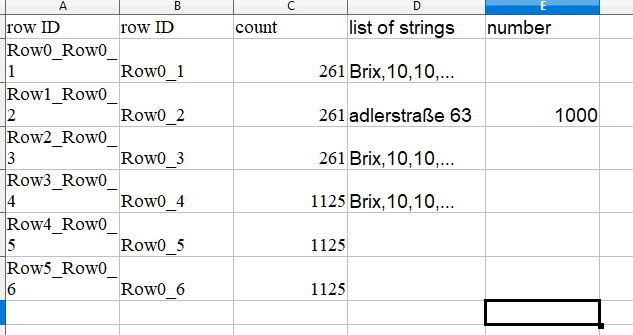
I downloaded your new file but I couldn’t see an extra column called “number” in the data. Would you mind please to check whether this is correct?
I think I didn’t understand your last question. What do you mean by “getting the value from column “number” and writing propper filtering for this workflow” ? In the solution that I uploaded, you already get in the end only the rows that fulfill your condition of “enough number of hits”. I do not understand what prevents you to upload to your API the “1000” number from this extra column. Sorry I’m lost. Could you please develop more? Thanks indvance.
Example:
for the “adlerstraße 63” column “number” has value of 1000. If I find hit for “adlerstraße 63” in my list of strings, then I want to have that “number” in my final table in the same row where “adlerstraße 63” had hit.
so the form of the last output table should be this:
However it leads me to a second question : Lets say that for a same sentence you have several dictionary words found, for instance “adlerstraße 63” and “an den domin”. Which number should be retained, 1000 (from “adlerstraße 63”) or 1009 (from “an den domin”) ? Have you though of a rule for this?





 ) may not need a loop, and could be implemented as follows:
) may not need a loop, and could be implemented as follows: