Hello,
I’d like to ask for some help on Selenium.
Goal:
I want to navigate through a website (EZT-Online) that has a hierarchical table listing to extract information from the items which are at the lowest level of the hierarchy.
Steps taken:
After some initial navigation, I end up on the main page. Here I want to start navigating by expanding the first folder by clicking on the plus icon (works as intended).

Here, each main folder contains an unknown number of subfolder, which in turn also contains an unknown number of new items. In this case, there are 5 subfolders.

As such, I use FindElements to again find all element where nodeExpand=true since this indicates that there are subitems still to follow.
Based on the nodeID of the plus icons, I filter those that are new (Kap 01 - Kap 05).

Next, I want to iterate through the list and apply a click to them to get to next level in the three.
Issue:
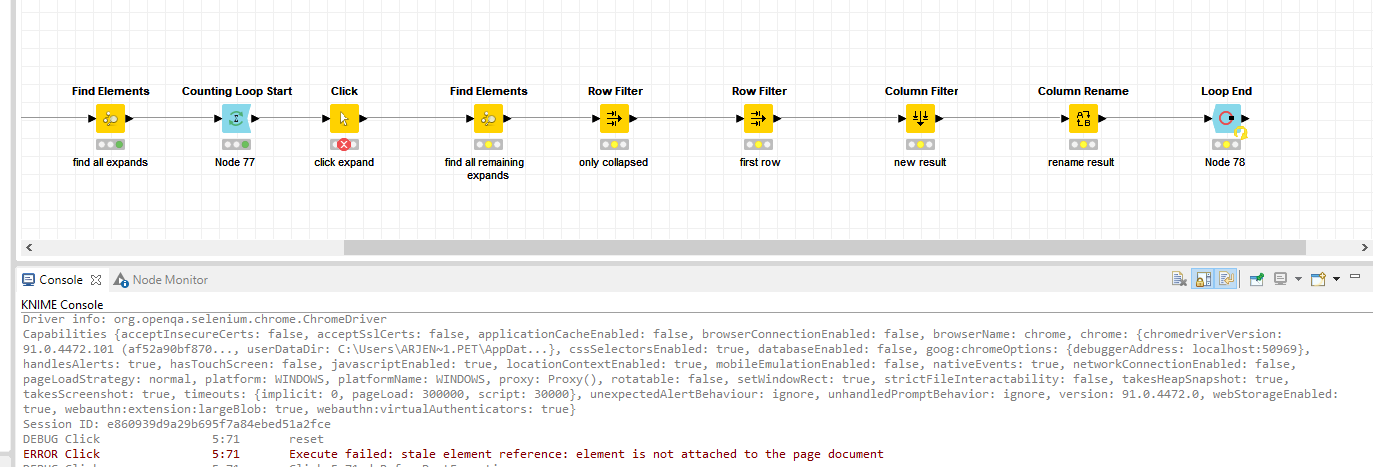
The first item in the list is clicked, but it fails afterwards due to:
Execute failed: stale element reference: element is not attached to the page document
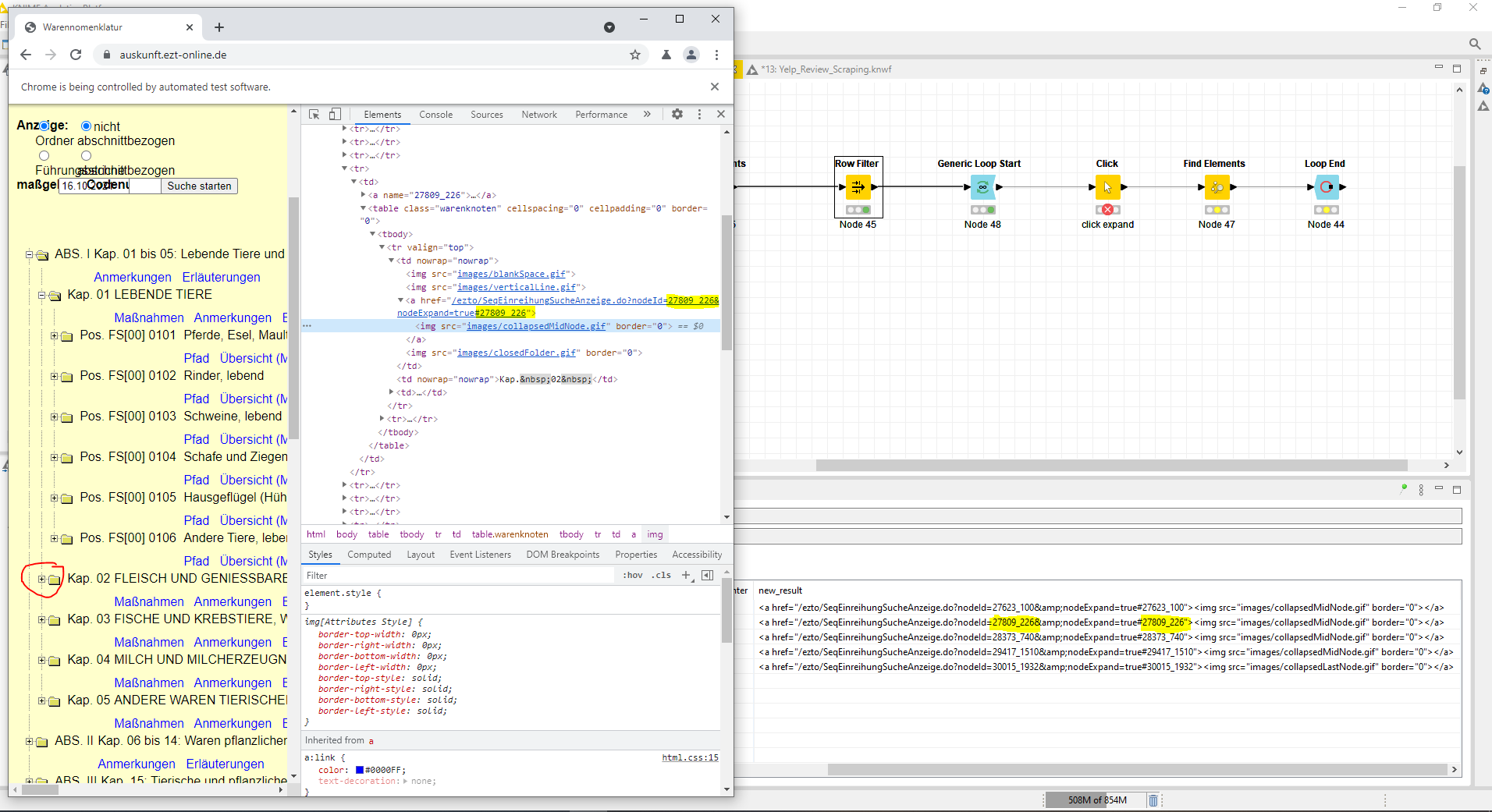
When I check the source code however after the first click, the nodeID has not changed and is still the same as was identified during the earlier FindElements.
WF: zoll_extractor_clean.knwf (39.4 KB)
I’m happy to recieve some tips and tricks on how I can approach this with Selenium, use the proper loops, position the Find Elements, iterate through them, etc.
Thanks!


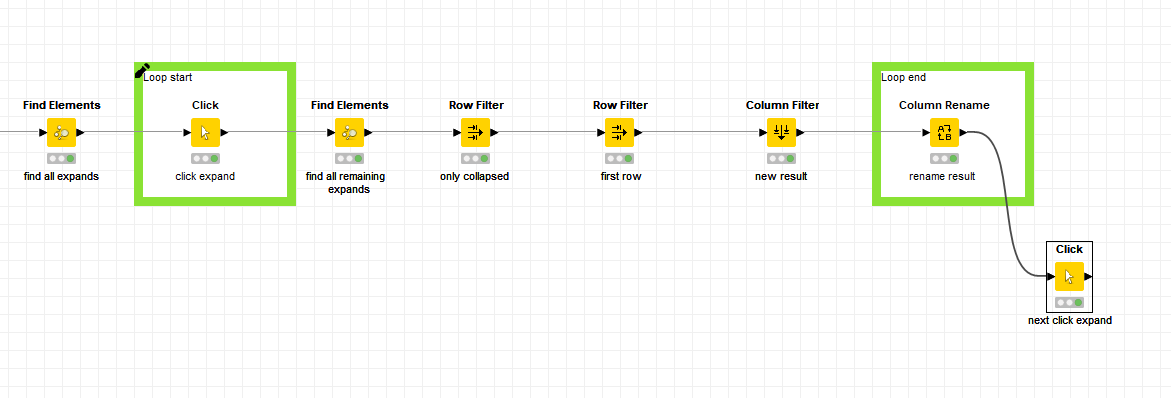

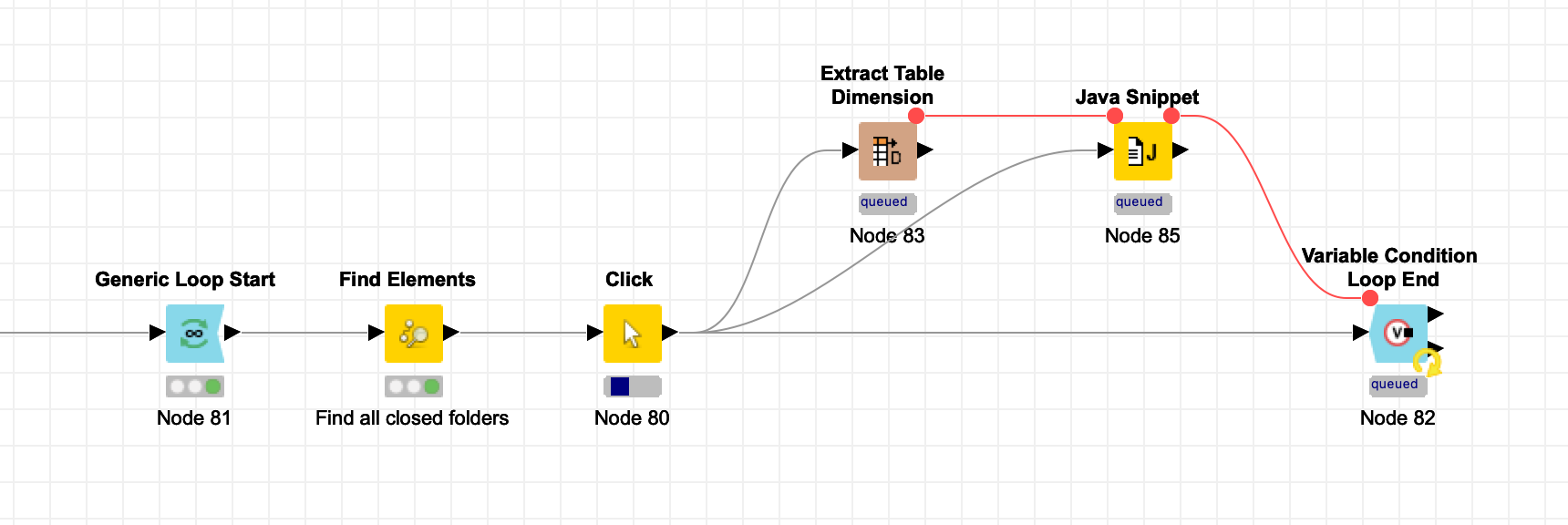
 ). Probably it makes sense to process all main categories one after the other?
). Probably it makes sense to process all main categories one after the other?