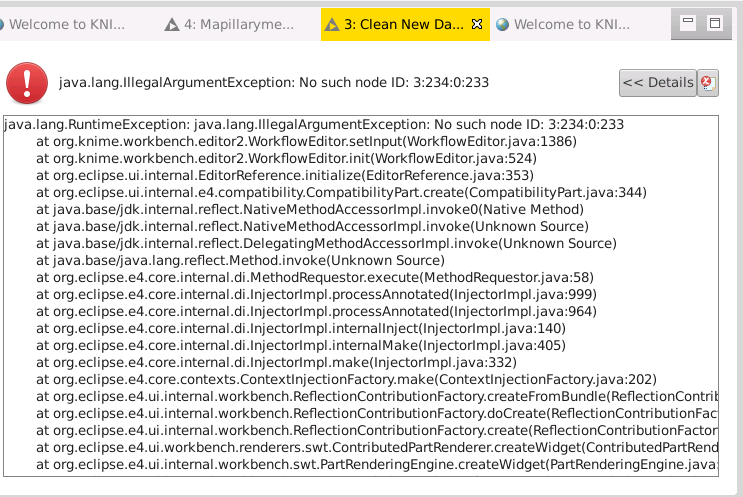
I have runned the workflow explained here for exlosion of the data which stored in a JSON format. I run my code for around three days on a server and now I face the below errors and cannot open my workspace anymore.
It seems the file became a very big file and crashed. I guess I need to store data in database to use this workflow idea. Is there any way I can retrieve my work without having to restart everything?
I am sorry that your workflow crashed after such a long execution time. Since you did mention your file you read in is somewhat >30 GB I would also recommend to move (at least parts of) the processing into a more robust and stable environment (like a DB) instead of handling everything with the memory.
Am I right that you run this workflow solely on your local machine with KNIME Analytics Platform or do you have a KNIME Server in the background handling the load? In any case, would it be possible for you to provide the software version number for reference? And what kind of hardware resources is available to you to run this workflow?
If you are running the workflow locally, would you be able to share the last 25-50 entries of the KNIME log (View > Open KNIME log) before you have faced the errors?
Can you also tell, if it is a specific node (e.g. writer node) that causes the trouble?
I am using 4.6.1 Knime Version and am running my code on the server with the below memory details:
total used free shared buff/cache available
Mem: 128549 91427 1061 79 36060 36005
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 40
On-line CPU(s) list: 0-39
Thread(s) per core: 2
Core(s) per socket: 10
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Silver 4114 CPU @ 2.20GHz
Stepping: 4
CPU MHz: 2500.120
It seems Regex Extractor is causing that issue. I would probably need to move everything to db as you suggested as I guess the explosion of cells containing json data is highly increasing the number of rows.
As I am running everything on server, it seeems I don’t have acess to the log anymore.
If your original table is in fact already more than 30GB and you explode it via transforming the JSON cells, you will end up in an incomparably larger file, forcing the system to use a lot of resources, esp. memory. Thus, switching to a DB is highly recommended.
Am I right that you run your workflow on a KNIME Server, with the hardware specs mentioned? If so, access to logs is a bit different. In that case, only someone with admin rights can retrieve the logs of the KNIME Server but also the KNIME Server Executor (which runs the workflow as a job in the end). If you do not have the necessary rights, you could contact your KNIME Server admin to investigate the logs.
Furthermore, did you already try to work with the Remote Workflow Editor (video)? It is an extension, which lets you open the KNIME Server workflow job inside your KNIME Analytics Platform to debug the workflow, in case of an issue. However, since the amount of data inside your workflow is quite large, it might take a while, to load the job.