Hi @mauuuuu5 ,
I took a look at your java code, and what I realised is you are misunderstanding how the java snippet works.
You are assuming that the java snippet is called once and that you can then iterate over all the rows in the table. Unfortunately it doesn’t behave that way,
The java snippet code in the section entitled “// Your custom variables:” is invoked once when the node is executed but has no direct access to the table data.
The snippet code in the section entitled “// Enter your code here:” is invoked once for each row in the data table. But on invocation it has access ONLY to the one row for which it is being invoked, plus any java variables that have been defined in the “// You custom variables:” section.
It is therefore not possible to write a piece of code to “loop through the row values” like you are doing.
In terms of specific compilation errors:
The first error displayed re List and ArrayList classes is that in java these are contained in the java.util package, so to have the java snippet recognise them you’ll need to include the following import statement.
import java.util.*;
You have commented this out, so you’ll need to uncomment it.
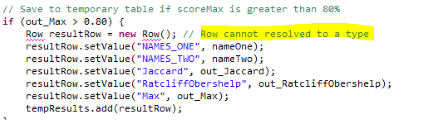
but you have also got a line of code referring to a “Row” class, which is undefined.

If you were able to do the processing that you need in the java snippet, then you’d probably want to change this to one of the java Map classes such as HashMap, so the line would instead be:
List<HashMap<String,Object>> tempResults = new ArrayList<HashMap<String,Object>>();
but that’s kind of irrelevant since the java snippet cannot work how you want it to here.
Now, in terms of your algorithm, yes a Cross Joiner will significantly increase the number of records (it is after all the product of all the rows in the two tables being cross-joined), but your algorithm is going to be doing (almost) the same thing since it is ultimately comparing every row with every other row, although the memory footprint may be smaller.
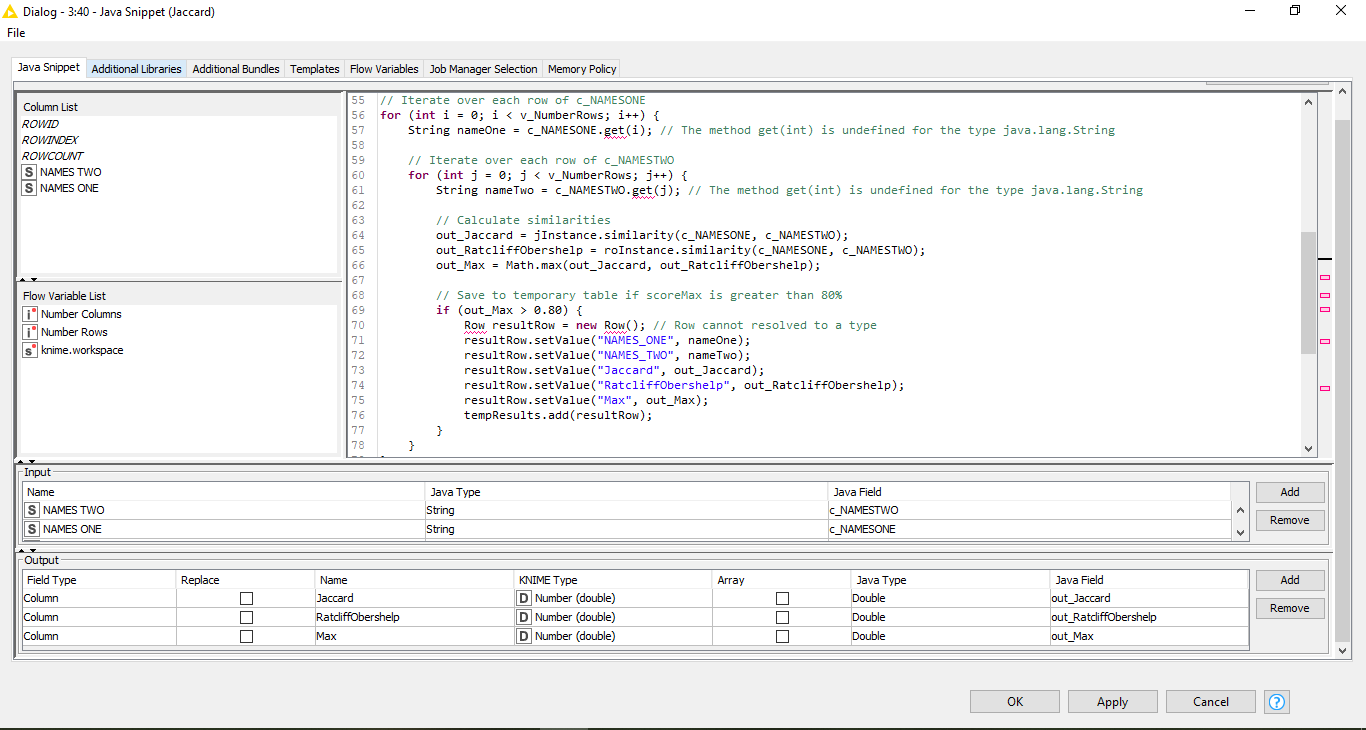
If you are trying to keep the memory footprint down, one approach would be to keep your original java code from your referenced post, and adapt the workflow around it.
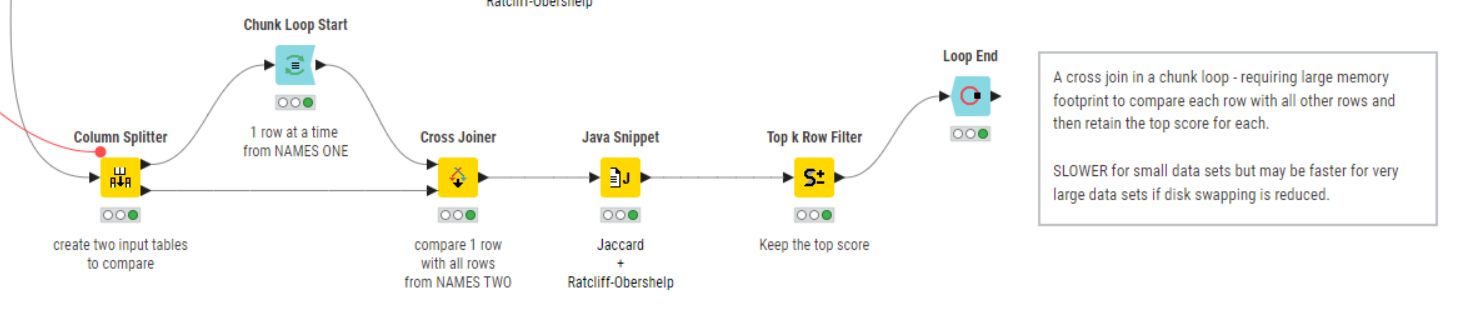
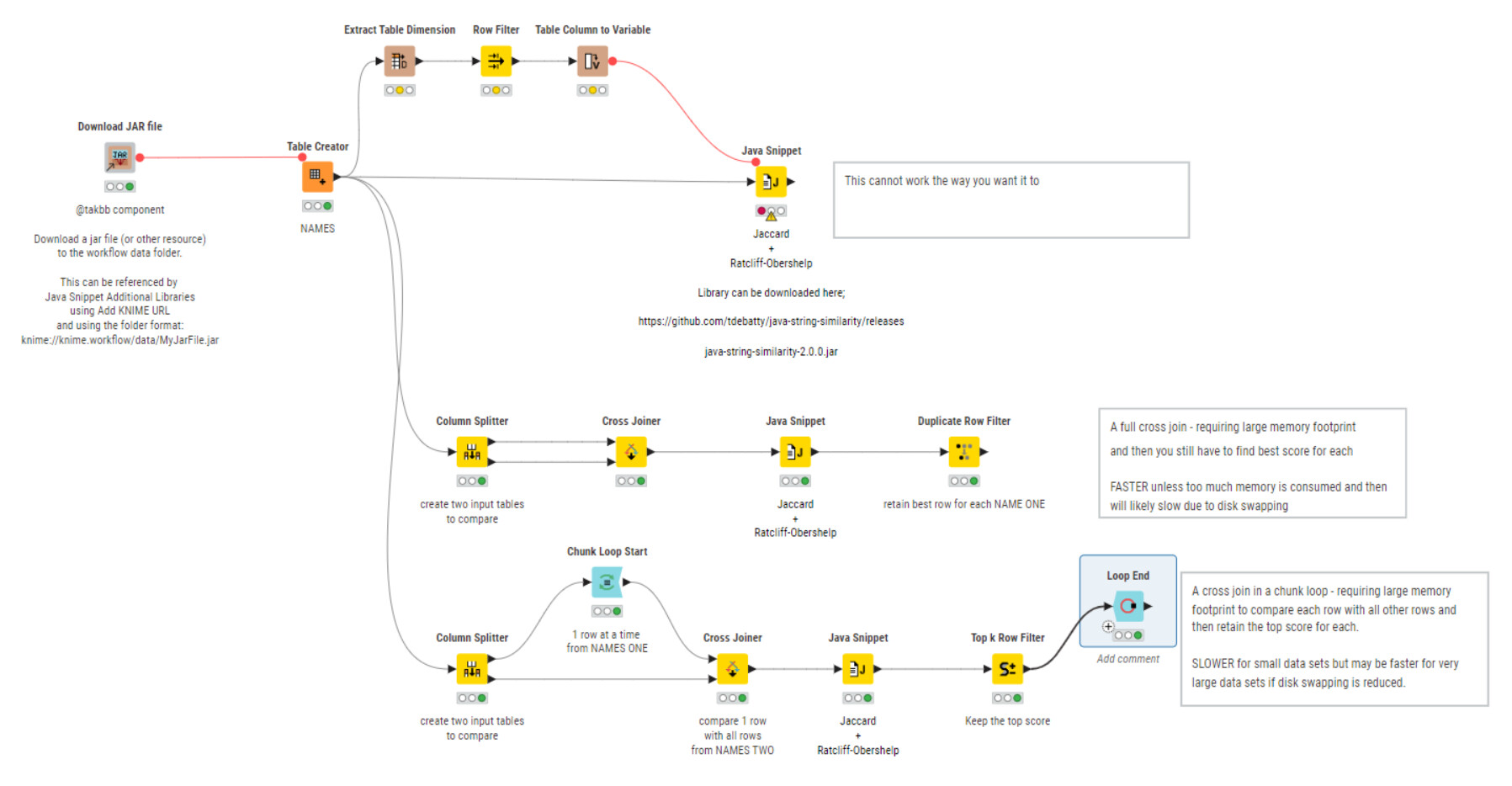
Let’s assume you then have a workflow something like this.
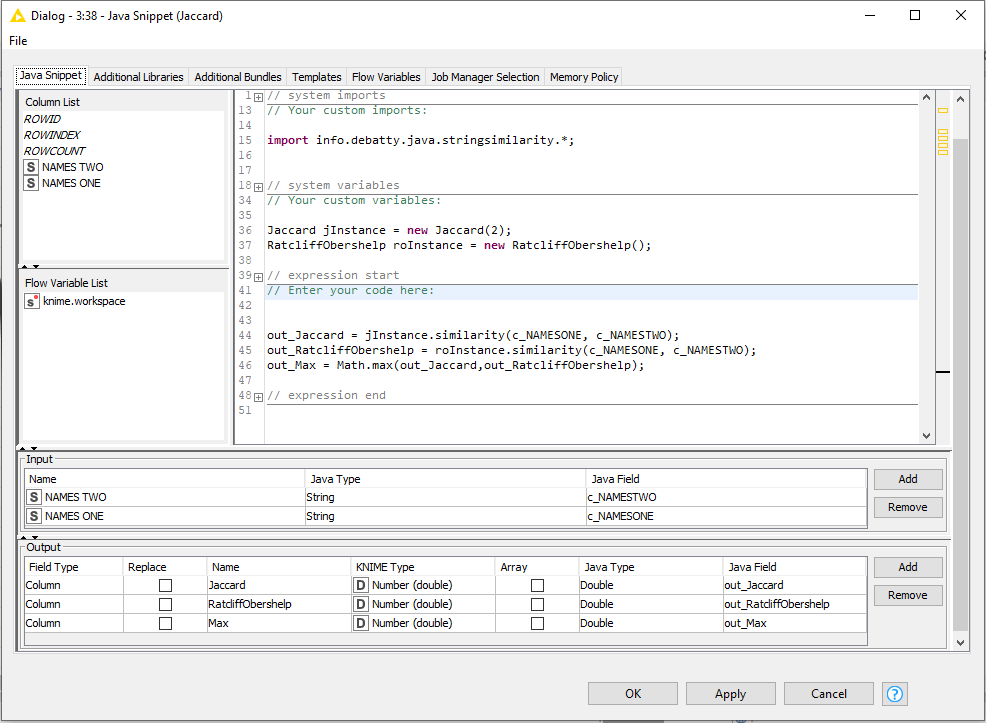
I have used a Column Splitter to divide you demo table into two tables. One table has NAMES ONE and the other has NAMES TWO.
The Cross Joiner matches all rows to all rows, then the java snippet calculates a score for each row, and finally a duplicate row filter can be used to find the best scoring row for each NAME ONE, for example.
For a small data set it is fine, but if you had 1000 rows in each table, then you have a dataset after the cross joiner of 1000000 rows. Which is where you are finding a problem.
An alternative to this then, is to have a cross joiner within a chunk loop. The chunk loop processes one row at a time from NAME ONE and then cross joins that row to NAME TWO. So at any one time, you run the java snippet against 1000 rows, rather than 1000000.
Of course the loop then iterates 1000 times, so for smaller data sets there is a performance penalty for looping, but for larger datasets it may be that looping is more efficient than the additional resource-swapping that may be required for a 1000000 row table.
I have uploaded a demo workflow for the above.
Interation among rows - takbb.knwf (158.1 KB)
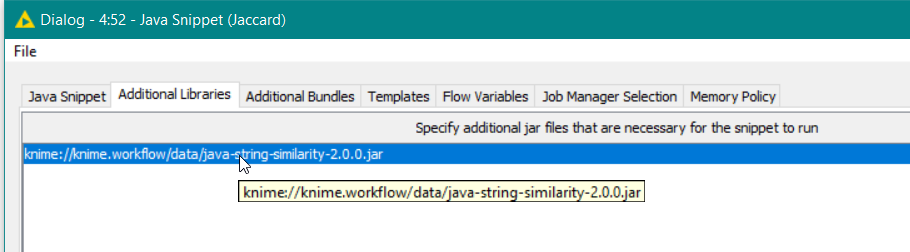
You’ll see that I’ve also included my component “Download JAR file” to make your workflow more portable. This downloads the jar file from the web address you mentioned and places it in the workflows ‘data’ folder. Within the java snippet you can then reference the additional library as:
knime://knime.workflow/data/java-string-similarity-2.0.0.jar
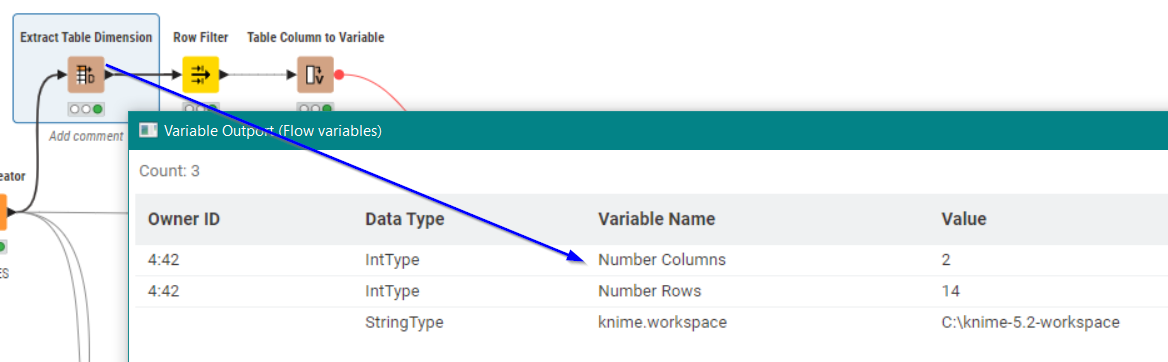
Incidentally in your flow, the Row Filter and Table Row to Variable nodes are not required:
The Extract Table Dimension node already returns flow variables as well as rows. You are not the first to do this!