Hey guys!
I need help on a topic, have an order table already handled, need to manage stock.
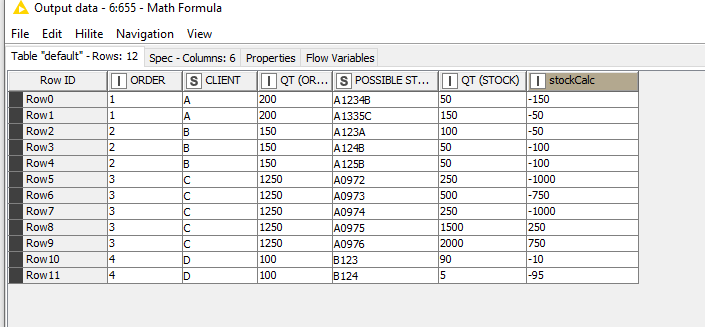
This table will arrive in the Java Snippet and need to treat it:
| ORDER | CLIENT | QT (ORDER) | POSSIBLE STOCK | QT (STOCK) |
|---|---|---|---|---|
| 1 | A | 200 | A1234B | 50 |
| 1 | A | 200 | A1335C | 150 |
| 2 | B | 150 | A123A | 100 |
| 2 | B | 150 | A124B | 50 |
| 2 | B | 150 | A125B | 50 |
| 3 | C | 1250 | A0972 | 250 |
| 3 | C | 1250 | A0973 | 500 |
| 3 | C | 1250 | A0974 | 250 |
| 3 | C | 1250 | A0975 | 1500 |
| 3 | C | 1250 | A0976 | 2000 |
| 4 | D | 100 | B123 | 90 |
| 4 | D | 100 | B124 | 5 |
In this table, grouped the orders and replicated them to possible stocks, so that within the Java Snippet I could calculate the QUANTITY (ORDER) - QUANTITY (STOCK).
In ORDER 1, we need stock A1234B and A1335C.
In ORDER 2, we need stocks A123A and A124B and we will not need stock A125B
…
I would like this result in output Java Snippet:
| ORDER | CLIENT | QT (ORDER) | POSSIBLE STOCK | QT (STOCK) | RESULT |
|---|---|---|---|---|---|
| 1 | A | 200 | A1234B | 50 | 50 |
| 1 | A | 200 | A1335C | 150 | 150 |
| 2 | B | 150 | A123A | 100 | 100 |
| 2 | B | 150 | A124B | 50 | 50 |
| 2 | B | 150 | A125B | 50 | 0 |
| 3 | C | 1250 | A0972 | 250 | 250 |
| 3 | C | 1250 | A0973 | 500 | 500 |
| 3 | C | 1250 | A0974 | 250 | 500 |
| 3 | C | 1250 | A0975 | 1500 | 0 |
| 3 | C | 1250 | A0976 | 2000 | 0 |
| 4 | D | 100 | B123 | 90 | 90 |
| 4 | D | 100 | B124 | 5 | 5 |
| 4 | D | 100 | - | INSUFFICIENT STOCK |
For order 4, there was not enough stock and you must add a line and include this message “INSUFFICIENT STOCK”.
Remembering that there may be many stocks, but only what is necessary should be consumed.
And another question, I need to import the libraries in code? How do this?
Thanks!