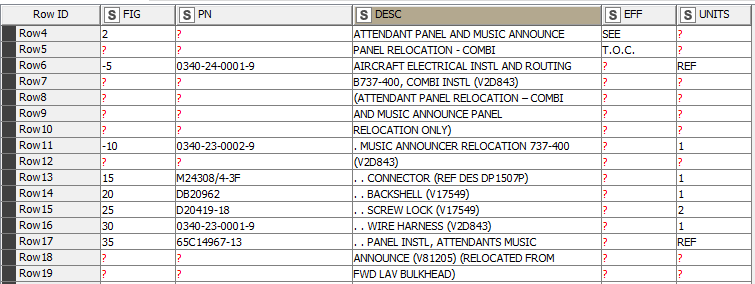
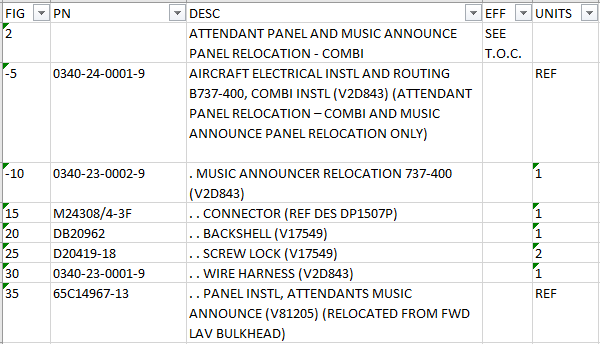
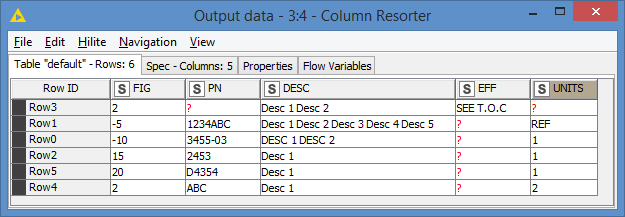
So whenever the value from the column “FIG” is missing, I would like to join this row with the last row where the “FIG” value does exist, separated by a space character.
Groupby is not suitable because the FIG number can occur more than once in the table, and I only want to join the rows that are next to each other, in order to keep the same order of the text.
Does anyone know a way how to achieve this?
Your help would be appreciated. Thank you!
Hi @mmelbaghdadi and welcome to the Knime Community.
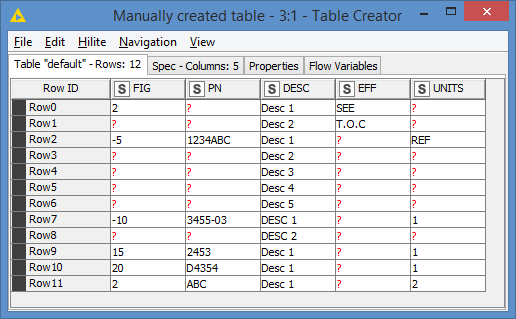
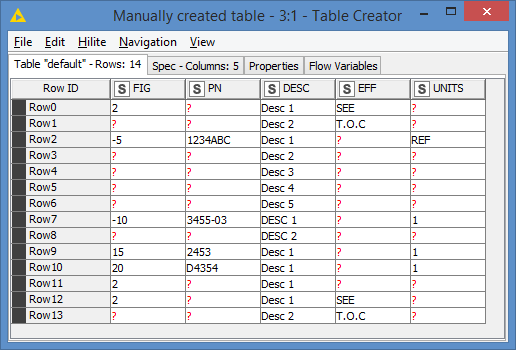
You should provide some sample data that we can use in our proposed solution. Noone is going to go and manually enter what you have in your images.
“the FIG number can occur more than once in the table” this is quite a crucial piece of information indeed. It would be great if an example of this is also included in the data sample. Would the repeated FIG values have the same PN, EFF and UNITS value?
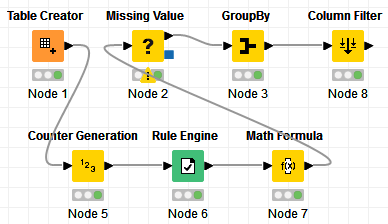
I built something based on the assumption that if the FIG is repeating, the PN and the UNITS are not the same.
EDIT: I modified the workflow so that the FIG is not dependent on any other fields. I still had to make another assumption though. In your sample, you are merging the rows for columns DESC and EFF since these are the cases that had different values in your sample. The assumption that I made is that the merge is happening with the other columns too, except of course for FIG.
The best starting point for me on this type of multi-row conditional test is to begin by dropping down the key column rows via the “Lag Column” node, and then creating a new column with your logic comparison test via the “Column Expressions” node.
@bruno29a thank you for your quick response!
Sorry for not providing sample data, but I see you already made the best out of it so I appreciate it.
Your assumption is correct, although it may not apply in this specific dataset that I am currently working on.
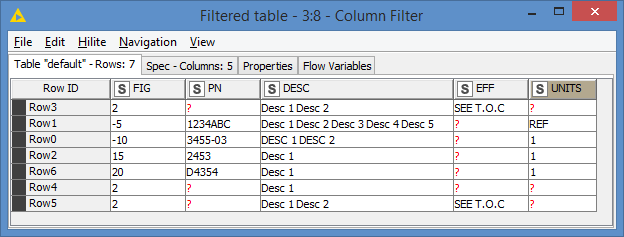
I tested the second workflow, and it actually does exactly what I wanted!
If you are still interested in the sample data, here is the file: Output filtered.xlsx (40.4 KB)
But for now, the workflow that you provided is doing the job.
Your time and effort are much appreciated, thank you!
If you have any questions about the workflow, please do not hesitate to ask, and I will explain
The general idea was to create some unique identifier other than FIG, hence the use of the Counter Generation node. And then it was a matter of doing some manipulation about it.