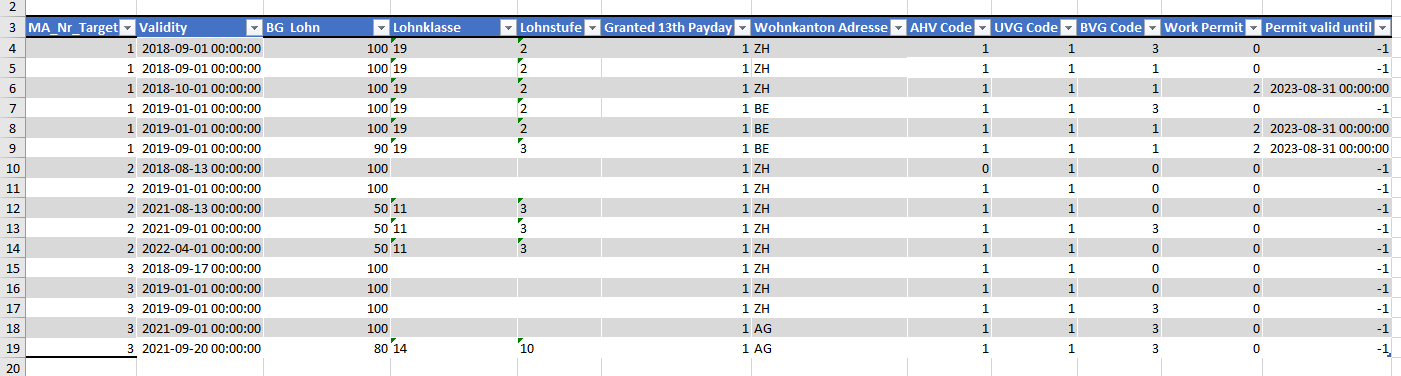
Question: How do you join a table, if you have to check something like “take the timestamp from table A und see, if you find a timestamp on table B, which is the same or older. If older, only the newest one is valid.”
Background: we are migrating our employee data from an old application into a new one. The old application has a main table with the employee data and 3 referenced tables, each of which provides historical information on some aspects of the employee. The key for the referencing the tables is the employee ID.
The new application has a main table with the employee data and 1 referenced table, on which we have to combine the information of the 3 tables from the old application.
Unfortunately, on each of the old tables, there is only a “valid from” timestamp. Each of the 3 tables has entries independent form the other tables. When joining the data, we need to find the rows belonging together, based on the timestamp.
Example file with the 3 tables: Test.xlsx (14.7 KB)
Hi @schneich , and welcome to the KNIME community!
KNIME doesn’t have a standard node for performing non-equal joins and the joiner node handles two tables at a time, so for such joins we have to sometimes get a little creative.
I gather that MA_Nr is “employee number” in the three tables.
Using Employee with id 1 as an example from your data, can you give an idea of the steps you would take if performing this manually and the output you are expecting for that employee, as I wasn’t sure which tables took priority in the date ordering, and what the end result would look like.
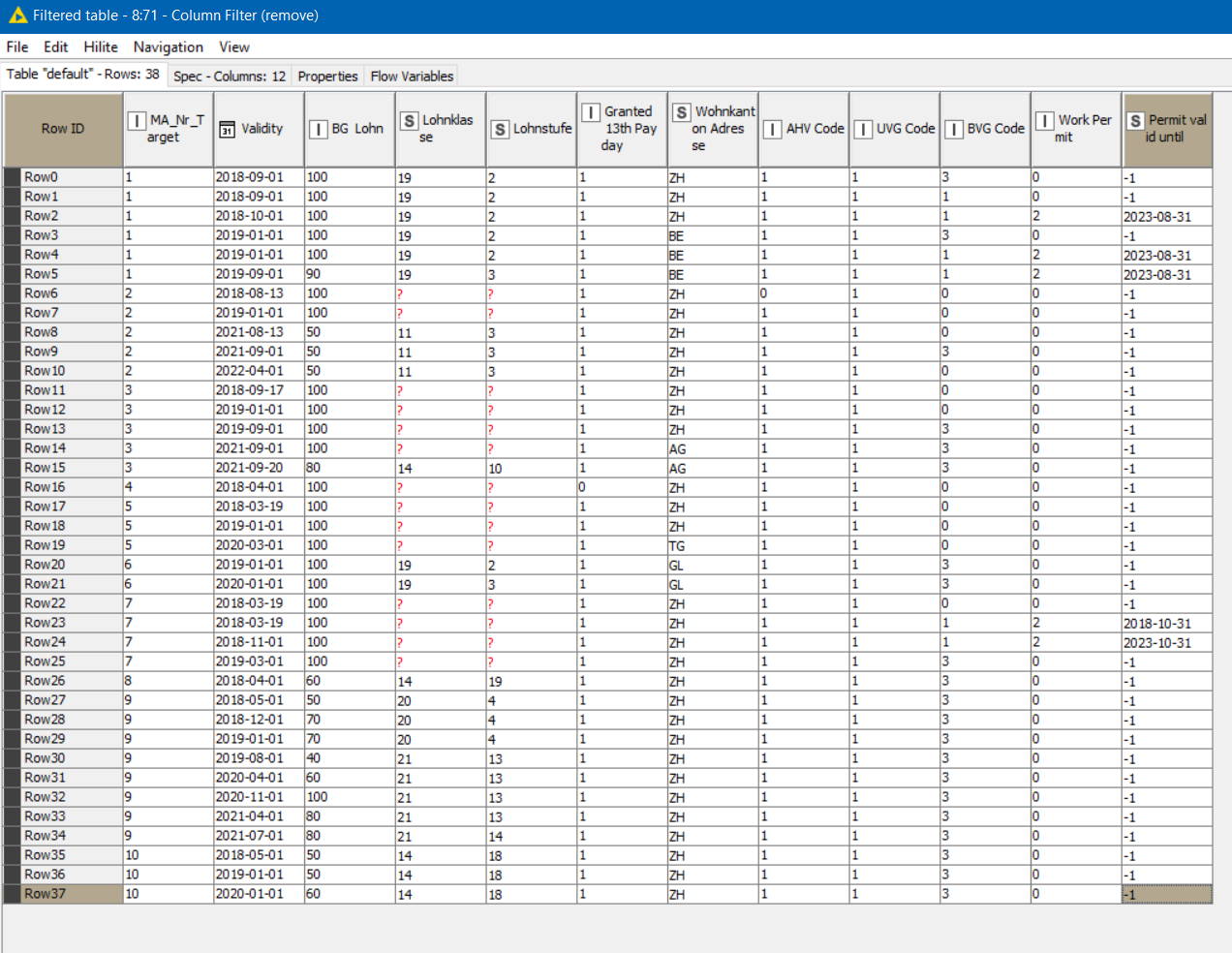
Here are screenshots from your file for ease of reference:
(the ####### in Tab3 is the value -1 , which I presume means missing/null )
I also wasn’t sure, if we look at rows “Row0” and “Row2” how you would choose between them if they happened to be the “match” as they both have the same date.
btw thank you for uploading a sample data file, which is always helpful. So many times we just get a screenshot and we are expected to “imagine” how it might work, or have to type data in ourselves before we can even get started!
Well, by looking at it, I realise that there are some duplicate time stamps in there and it is not clear, which one would be the correct row. My colleague will check with HR on monday. For now lets take the assumption that we can make the timestamp unique per source table.
Yes, Ma_Nr is the employee-ID.
If doing this manually, I would…
** …create a new master table, with all the collums of the 3 source tables.
** Then, I would copy all the data into their own rows. This would result in many empty collums.
** Then, I would sort after employee ID and the timestamp.
** Then, where there are empty fields, I would fill in the blanks with data from rows before.
Hi @schneich , Thanks for the additional target output.
I’m still not quite “getting” the rules for comparison, and as a result I don’t understand how you ended up with 6 rows in the target output for Emp 1.
As the sample data contains similar dates across all the tables, it’s difficult to work out which table each of the “Validity” dates originated from for each row.
When you are comparing dates, you mentioned the principle: “take the timestamp from table A und see, if you find a timestamp on table B, which is the same or older. If older, only the newest one is valid”, but what I don’t think you’ve said anywhere is that when comparing tables 1, 2 and 3, which do you consider table A and which is table B in each comparison? i.e. are you looking for table 1 dates to be newer or older than table 2, and again for table 3… etc.
I am currently not close to a pc. Therfore i try to describe my thoughts in words.
Use group loop for looping over your mastertable with employee and date as group condition.
Apply a rule based rowfilter on each subtable where employee = variable(employee) and date <= variable(date)
Use groupby node on each filter node with employee as group condition and maximum(date) as aggregation.
Join groupby nodes back to your filter nodes employee = employee and date = maximium(date). Now you should have only the latest record of your subtables,
Join your subtables to your group loop start node
Modify your masterdata if needed with e.g. a rule or java script node
remove the subnode columns
Connect to loop end node
This output table now represents your new table.
Hi @schneich … ok, yes I was fixating on the original wording and having re-read what you’ve said, I think it became clearer, and I now better understand the process.
The “merging” of the three tables can be performed by two joiners, each joining both matching and unmatched rows into a single output table. The first joins t1 to t2 based on MA Nr and date from each table, the second joins the result of that to t3 based again on MA Nr and date, so we then have the three tables merged. It was important on the joiner to “Merge join columns” so that the second joiner had a single pair of columns to join on.
After that, the output can be sorted by ascending MA Nr and Date Order, and missing values filled down in a group loop, (to enable us to fill down one employee’s records at a time).
Hopefully that should be a step in the right direction