HI ALL,
i have some problem with 2 tables and a JOIN.
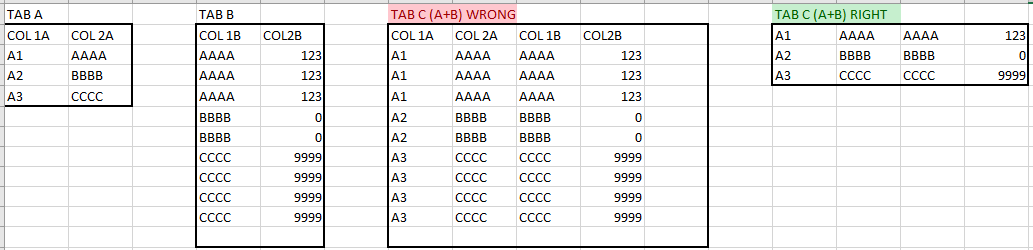
in table A (Left), I have different lines like this: (all are uniques)
|A1|AAAA|
|A2|BBBB|
|A3|CCCC|
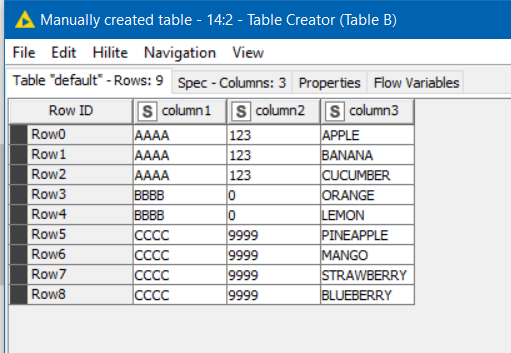
In a table B (right) i have lines like this: (lines are not uniques, sometimes are duplicated)
|AAAA|123|
|AAAA|123|
|AAAA|123|
|BBBB|0|
|BBBB|0|
|CCCC|9999|
|CCCC|9999|
|CCCC|9999|
|CCCC|9999|
When i join together the lines of table A increase for how much rows find the record in a table B.
I fix this with “Duplicate row filter” before to join the table B, but i this i should have a different solutino, right?
let me try to help.
What if you use a group by node on table B before the join, so that you won’t have repetitions in B?
With group by you can aggregate column 2B using sum, average, etc. or just selecting the first value.
The join should result as you asked.
The joiner node performs the standard “relational” joins and it’s not common to have a join-on-first option but I can understand there may be an occasional need to do this.
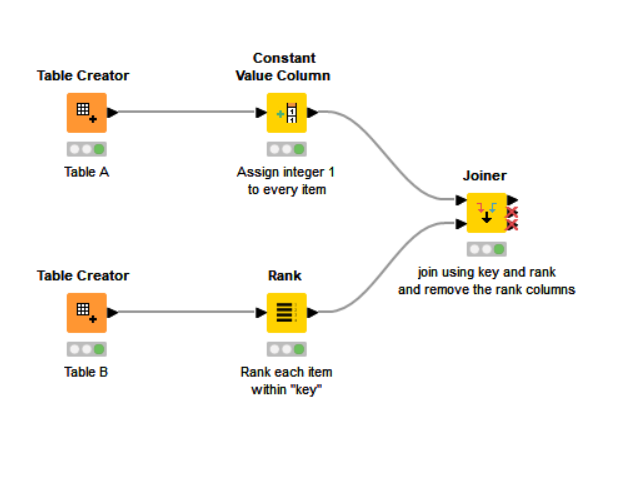
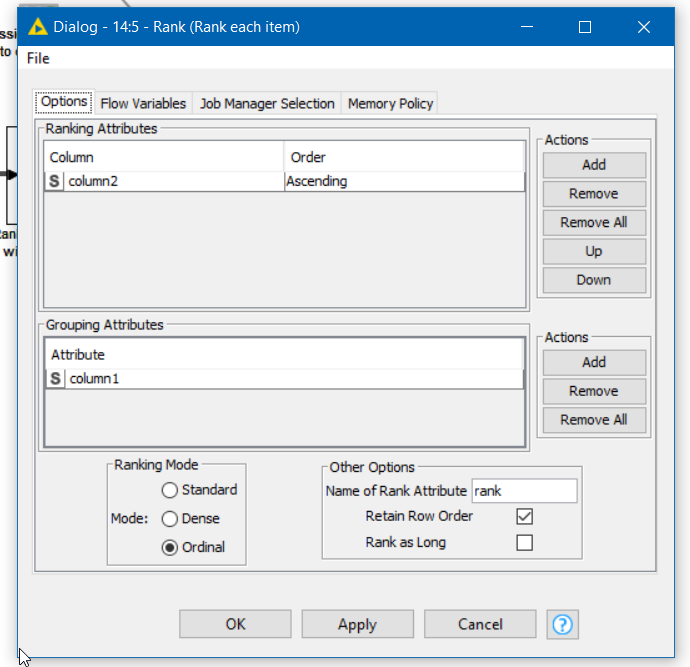
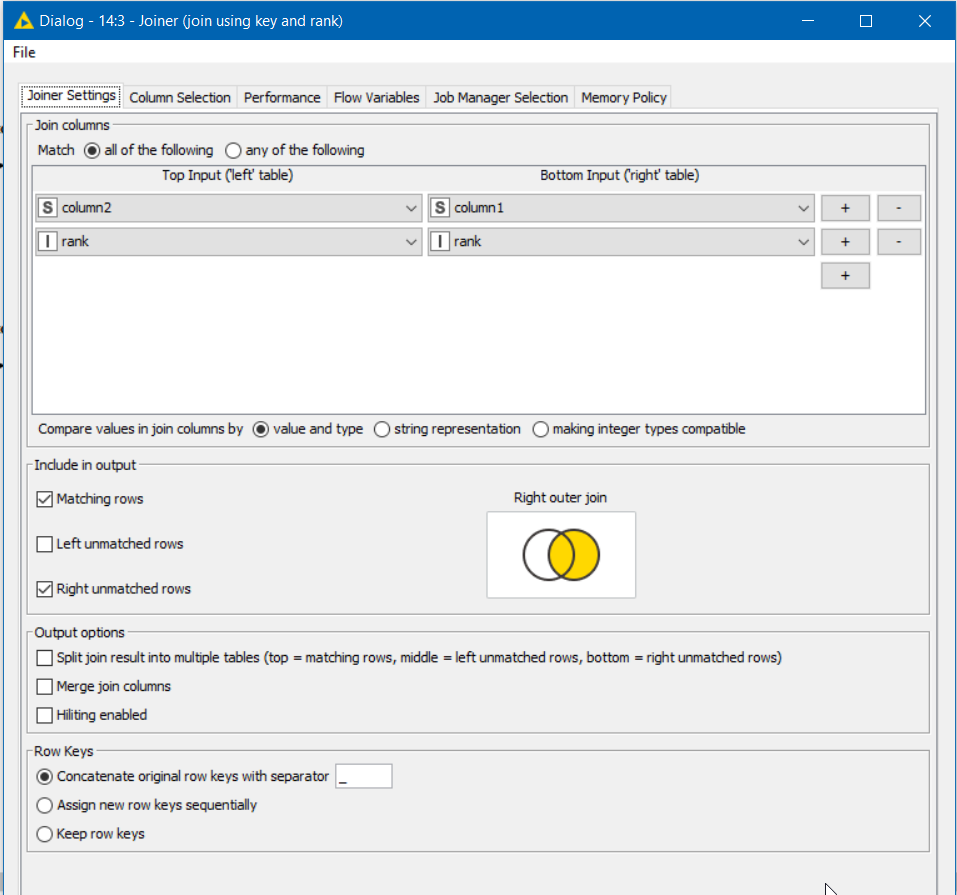
Whilst there is no direct option in the joiner to do it, you can replicate this behaviour without using the duplication removal by “ranking” the rows within the keys that you wish to join on.
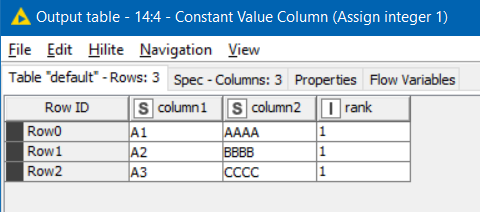
For the table that is the “lookup table” (Table A in your example), you just assign every row a “rank” of 1.
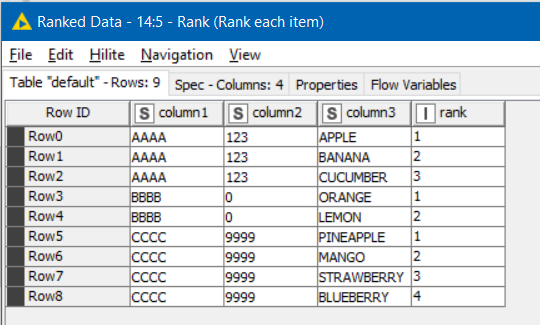
For the other table, you can assign each row a rank grouped within “key”
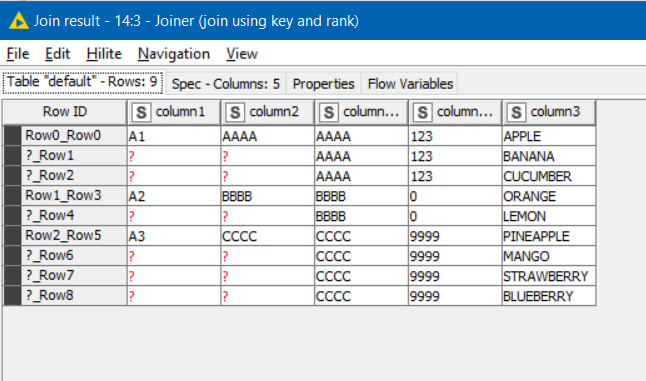
I added an extra column to your Table B containing to demonstrate this.
After the ranking node, each row is ranked as follows:
(EDIT)
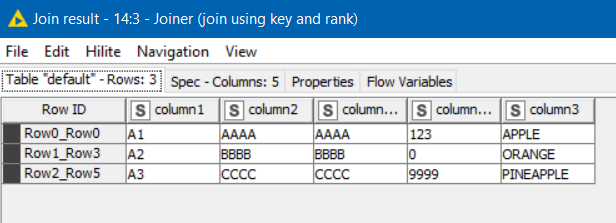
In the joiner, you include the “rank” column in the join. Since your lookup table only has 1 as its ranks, only the first row will match for each key. In the joiner we elect to remove the rank nodes as part of the join. Here I have elected to include the (right) unmatched rows too:
Personally I would generally do duplicate removal as you already suggested. I know it’s still extra steps, but I hope that helps if duplication removal is for some reason otherwise causing problems.
@gcas with a lot of databases you can use Window functions like RANK to have more control over which record gets selected at the end. You might have to have a criterion to determine which row would get choosen. I have discussed options here