first time poster here … and I like to thank all of you who have posted and answered here - I learned a lot!
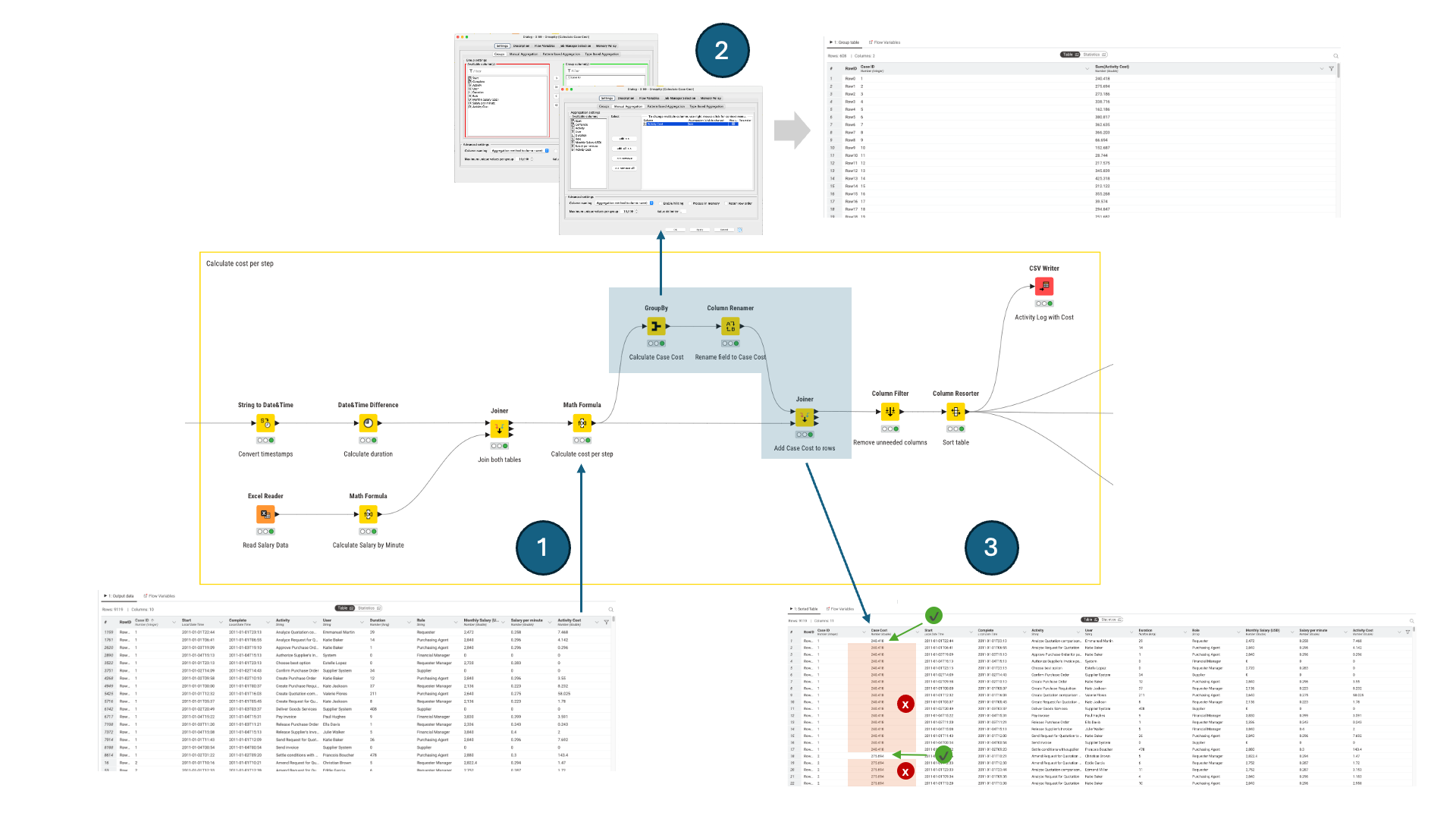
But now I am running into a problem that I cannot solve by myself. I am preparing a data set for consumption in a Process Mining tool and have calculated the activity cost for each activity (row) in the data set. Then I used the Group By node to calculate the overall cost for the case (column Case ID).
So far, so good. However, when I join the case cost with the original data set, the Joiner node fills the case cost into every row with that case ID. That leads to a multiple of the overall case cost in the Process Mining tool.
What I want is that it only fills the first record for each case - the green checkbox in the screenshot in the lower right corner. All other cells in that column for that case should be empty (the orange highlight).
What comes up in my mind is to add a Rank node (Ranking Attribute = CaseID and Ranking Mode = ordinal) after Math Formula node.
Then in the GroupBy you add an extra Aggregation: take the minimum of the Rank.
In the joiner node add an another matching criteria, in this case the Rank.
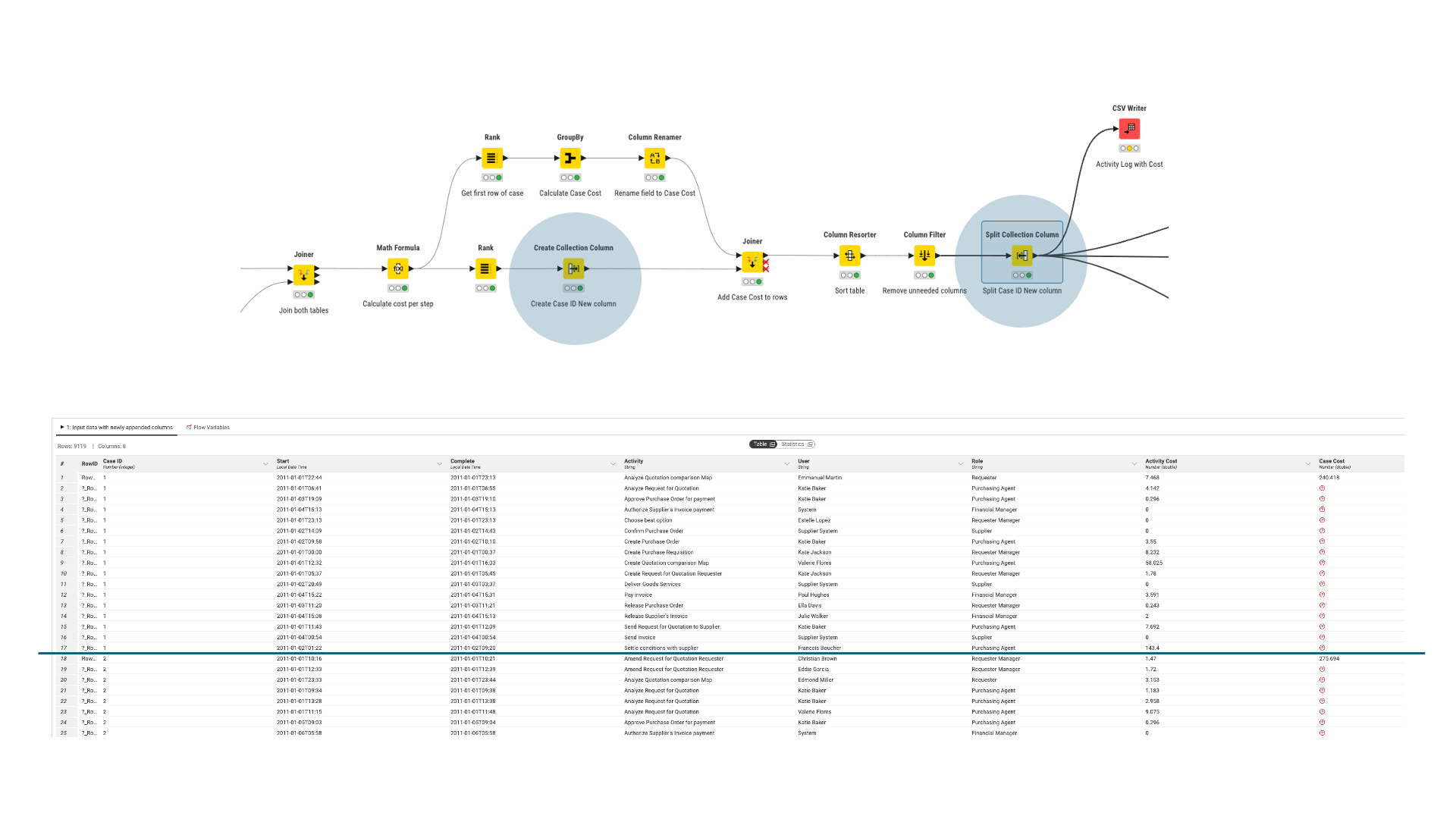
it worked Now I have to test if it also works in the process mining tool as I think …
What I had to do was to duplicate the Case ID column in the original table as a collection column and then remove the Case ID after the Join. Then I split the collection column and -ta da- I have the table that I wanted as a result.