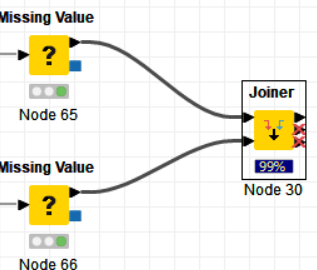
I am trying to find a solution for this issue I am facing (which I never faced before in more than 3 years of using Knime) with a very simple join (Left join) on two datasets with around 275k rows (both). I’ve declared every null ("?") cells from every column (as I know this was a problem in the past) with a value (I have added 0), but my join is still stuck at 99%. This doesn’t seems to be an issue related to the heap space, either.
The only occasions I have had same kind of problem with the -Joiner- node is when by error or inadvertently every row was joining to every row. Even if the two datasets are “small” (~257k), this all-to-all joining would take pretty long and KNIME would stack on the “99%” message. This can also happen if many of the rows of 1st dataset match to many of the 2nd dataset without even all matching.
Most probably all the 1st table “Zero” cells are joining many times all the 2nd table “Zero” cells.
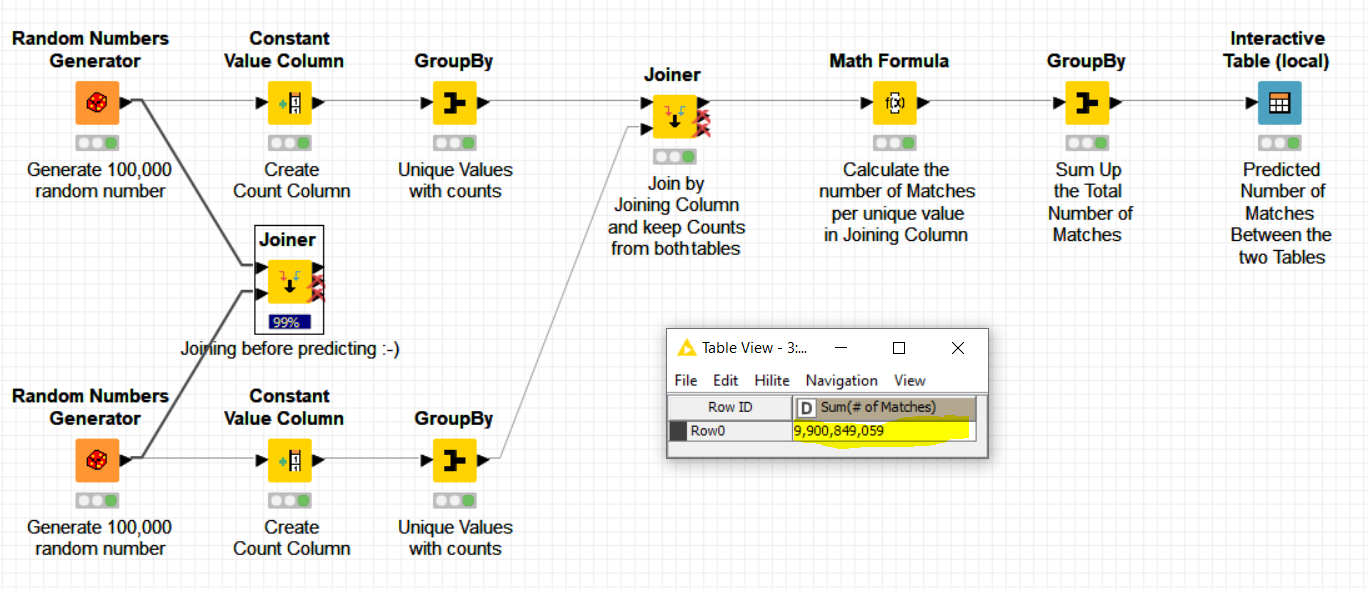
Maybe it would be wise to first calculate how many rows generates your joining operation, as follows:
For every table apply a -GroupBy- of the joining column with count as aggregation operation.
Then join the two “GroupedBy” new tables instead of the original ones by the joining columns.
At this point, you should get a new table with the joining column with two new columns with counts (Right & Left Count)
Multiply per row the two count columns using a -Math Formula- node to generate a 3rd new column, here called “Number_Of_Matches”
Do a -GroupBy- all the rows and aggregate by a Sum aggregation the “Number_Of_Matches”
The result of the -GroupBy- should give the final number of rows that should be generated if we have done a direct Join of the two tables. This should tell you if the Joining is realistic or otherwise a huge one.
True. This many-to-many join made the Joiner crash…strange. I have been using Knime in more complicated situations (with joins over 1 mil rows). The first and second suggestions you provided made the trick.
Please find below the workflow I described before which reproduces the problem and exactly predicts the number of final rows a -Join- node will generate before doing the -Join- which can be of help and save time