Hi all, I have a trouble with Joiner Node, after use it I have to clean rows with “duplicate node” because it make a lot of duplicated data.
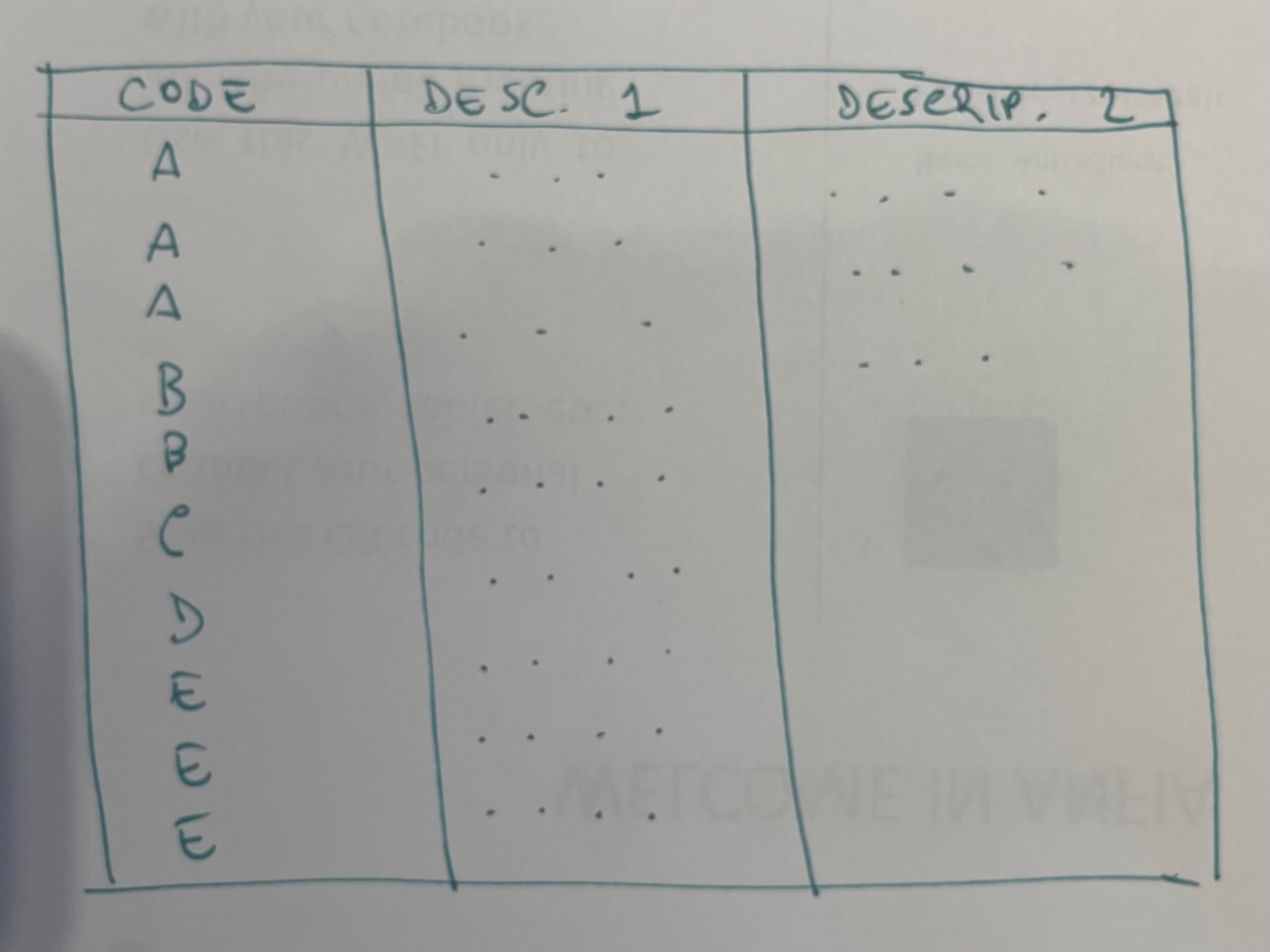
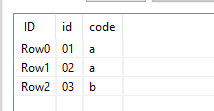
In a TYPE TABLE I have several rows that sometimes could be duplicate, but i cannot fix this
In a TRANSACTION TABLE I have a list of transaction
If I join that tables i found this error:
Transaction 01 need to be just 1, but in a output table i have 2 rows because in TYPE TABLE there are 2 rows with the same code A
Wrong output:
01 A
01 A
Desidered output:
01 A
Can you help me guys:
I’d like to set in Joiner Node this rules: match just 1 time.
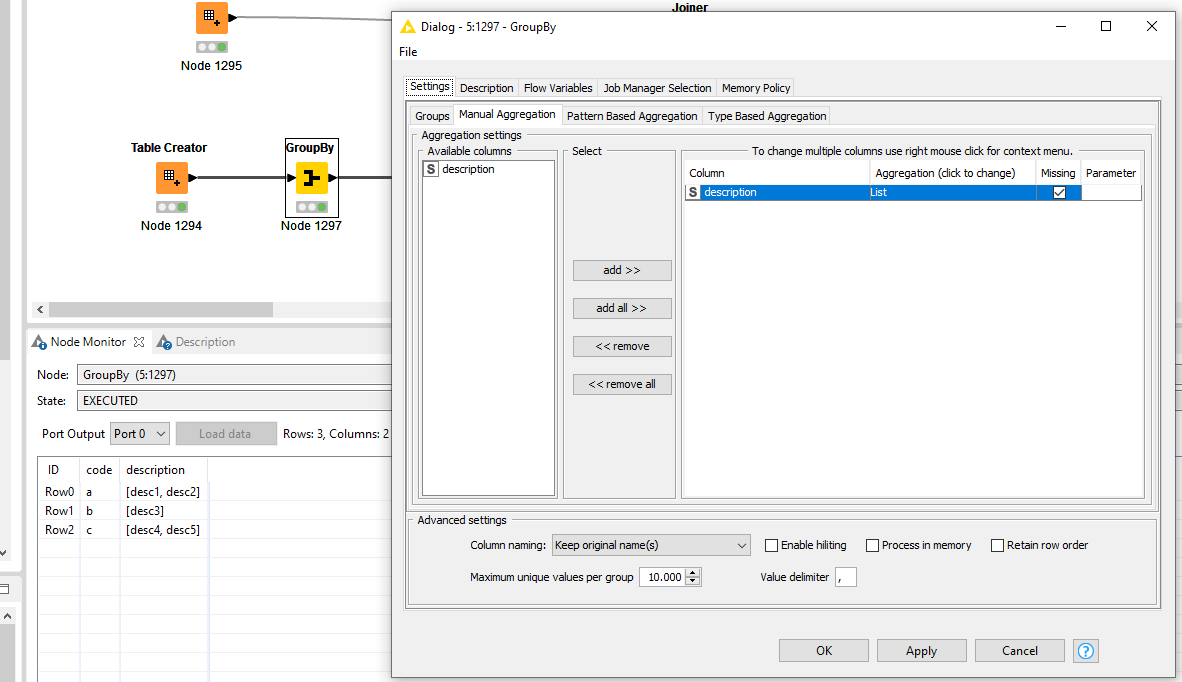
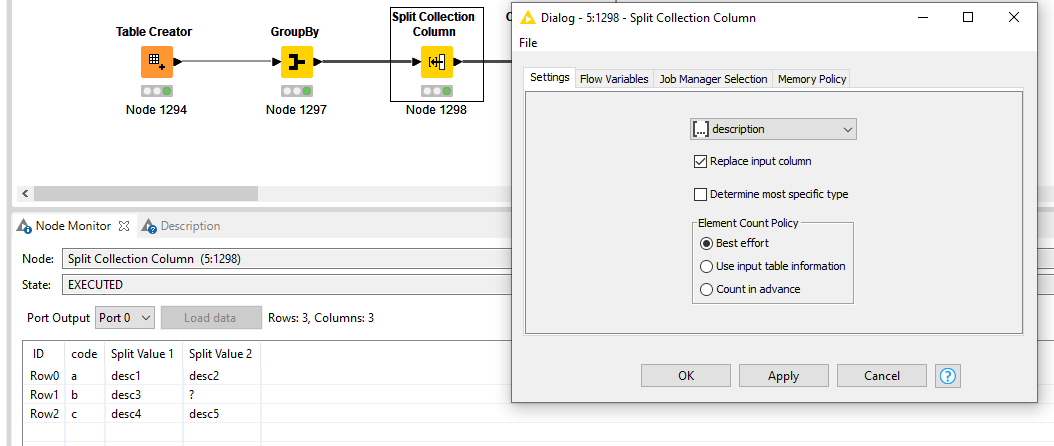
You cannot fix it or you don’t want to fix it because of your use case/business rules? If you GroupBy the type table and use for example Concatenate, First or Last the description that would create one entry and the joiner will generate the desired output.
If you just want to check if the code is available then there is little point in maintaining the duplicate entries in your type table.
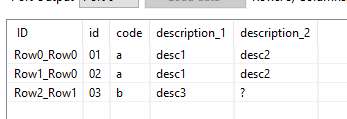
It’s to prevent hardcoding the renaming of columns. Let’s assume you now have two descriptions per code. Renaming them in a Column Rename works fine until a third description is introduced on the source side. That means the Column Rename has to be amended to also include the additional entry.
With the Regex equivelant of the node, this is done automatically because it looks for Split Value and replaces that with description_. As such, the number of split values can be unlimited.
Everyday a receive a xls with codes: some of them are new, other are know.
I think i should create a “smart csv” (code archive) that allaw to me to create a file without duplicats codes: in this way the next join wont be affect from duplicate rows
sorry read only briefly through your problem statement, but can you not simply use the ‘Pivoting’ node to create columns out of the duplicates ?
– it will be less error prone than using regular expressions, as Pivoting node is data driven.
– although, you will have to create an additional column prior to the Pivoting node, to create your column labels to route the values to the correct target columns
I use this approach all the time to create columns out of ‘recurring’ values and to bring the table back to the desired granularity level.