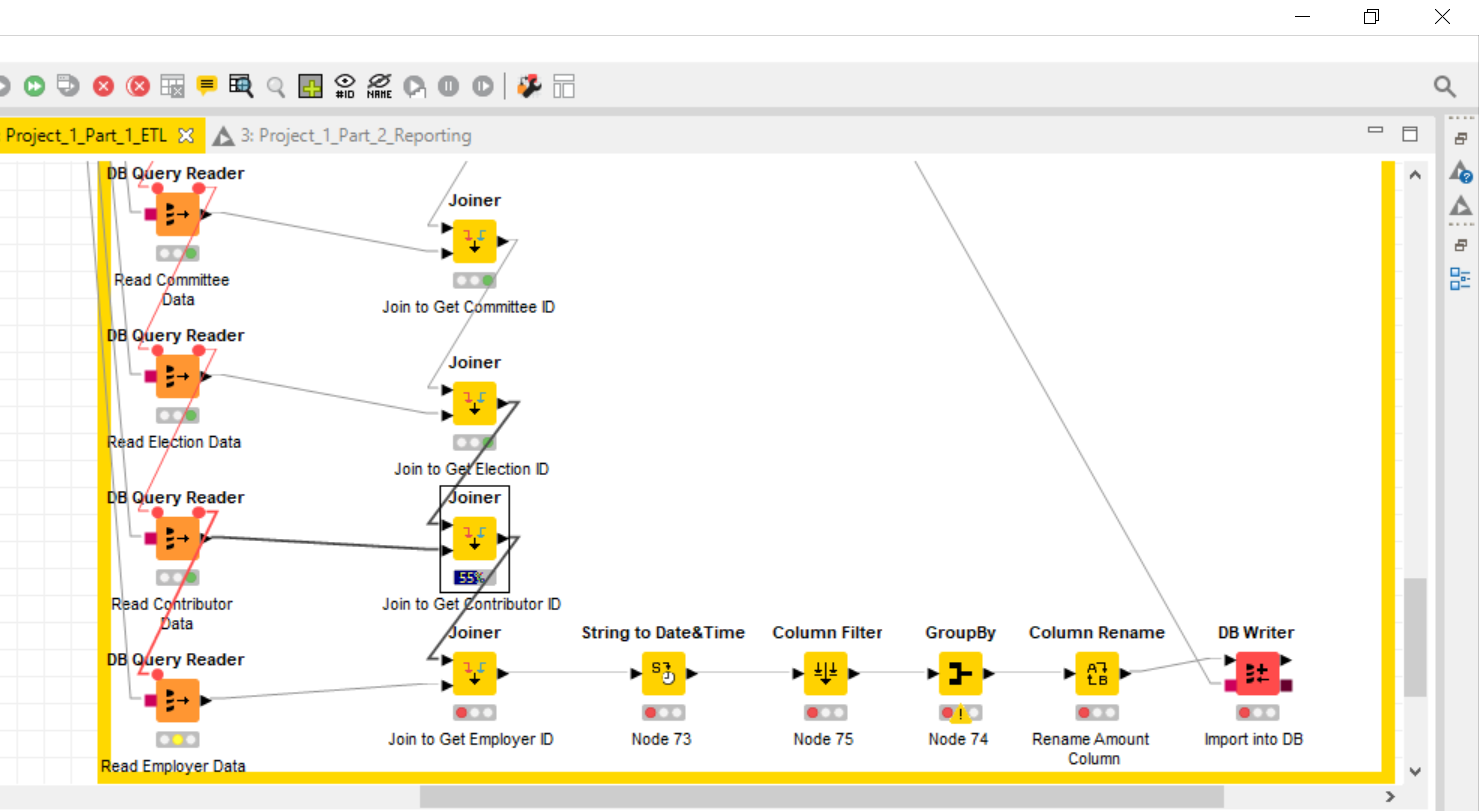
I’m working on a project for school that I’m really struggling with and a Joiner node in my workflow is always stuck between 50-60% for when I try to join data from a DB Query Reader node and another Joiner node. Looking online, I saw the Cache node was suggested but that didn’t work for me. I also modified the Java Heap Space from my knime.ini files but that didn’t work either. Are there other suggestions available to solve this issue? If you are able to meet offline to discuss the issue and view my workflow, that would be very helpful since I can’t find a tutor proficient in KNIME and this project is due soon. Below is a screenshot of the issue in question:
Hi @mcuz91 and welcome to the forum.
Hopefully somebody can help, but would you be able to give a few details which may help to work out what is happening…
-
How many rows are in each of the tables that are being linked by the joiner node?
-
Have you definitely got all of the necessary joins (ie all the columns to be matched) in the joiner configuration or have you accidentally missed some out?
-
What sort of join are you doing? (eg inner, left/right outer, or full outer join)
-
Which version of knime are you using and ON which operating system?
Thanks.
Hi @takbb thanks for the reply. To answer your questions:
- The Joiner node has over 5 million rows and the DB Query Node has 92,000 rows.
- I joined the columns using the state attribute which is contained in the Joiner and DB Query nodes.
- I’m doing an inner join.
- I’m using KNIME 4.3.3 on Windows 10.
Also, I notified my professor of the issue and he mentioned there is a lot of duplication in one of my dimension tables but I don’t exactly know what he means by that.
@mcuz91 thank you for giving those details. What sort of database are you using, and are all of the DB Reader nodes reading from the database? If they are you would possibly get massive performance improvements if you were able to do the joins in the database, rather than bringing all that data down to your pc and joining there which is what is happening here.
It depends on what other processing you are doing before we can determine if that is feasible, but it would definitely be worth looking at. You’d need to look at using the DB Joiner node if you want to try this out.
I’d still also double check your join conditions to ensure that you haven’t missed anything out which might be causing a “partial” cross join.
If you somehow were joining on the wrong columns and it caused everything on one table to match with everything on the other table, you’d be looking at a cross joined result at of 5million x 92000=460billion rows, which would certainly take some time!
Have you also tried doing the join using a cut down (filtered) version of your data as a “sanity check”? For example you could put a row sampling node on both the input to the joiner, and have it select maybe just 50,000 rows from the 5 million rows table about. You might need to play about with the sample size or other config, before you find a few matches, but it might move you in the right direction.
4 Likes
Hi @mcuz91 , which version of Knime are you using? I am not sure if this has been fixed in 4.3.x, but in 4.1.x (or possibly 4.2.x), the joiner node had a hard time when joining on NULLs. It would take hours to join as opposed to a few seconds, so that was a huge difference.
My work around for this was to do a Row Splitter to separate the NULL records and not join them, and join only on the non-NULL records, to then concatenate the separated records, that is if I was doing a left join, otherwise if it was an inner join, I would simply discard the NULL records.
So, I am not sure if you are having issues because you have NULLs.
I know with Knime 4.3.x, there is an alternative join node, which is the Joiner (Labs) – KNIME Hub which is supposed to be much more efficient and should not have any problem with NULLs.
May be try this node?
5 Likes
@takbb the database is in PostgreSQL and all the DB Reader nodes are reading from there. @bruno29a it is Knime 4.3.3.
I’ve been working on this issue for several hours and have a bit of urgency to fix this issue, would either of you be able to meet offline on Zoom or something to look over it? I’m behind on my project and learn a lot better when I get an explanation hands-on. I can really benefit from a tutor since I feel behind in my class and am always getting stuck on my project.
I’d use the db joiner nodes instead and join all your data before pulling them into KNIME. From your screenshot it looks like most if not all of the stuff you’re doing can be done using db nodes.
I assume the reason the node gets stuck (actually it is just slow) is because of the size of your tables and the amount if RAM your machine has.
Best
Mark
2 Likes
Mark, thanks for the response - I need to create a separate “fact table” that joins data from Excel files and merges serial primary keys from the DB Reader nodes in my PostgreSQL database which is why the Joiner nodes are used. The fact table will have the primary keys from the tables from the DB Reader nodes while loading data from the Excel files.
If you have time tomorrow, I would appreciate if we could meet separately to go over the project in more detail so you can get a better idea of the whole scope. Let me know, thanks.
A few remarks about JOINS and data bases. Like @takbb has already mentioned you will most likely be better off of you do the join in the database (but also the database needs performance if it is on the same machine).
Then with joins you should check if you have a lot of possible duplicates or missing you try to join since this will hinder performance.
And also depending on the length and complexity of your keys long strings can be a challenge.
Then as you have already done you might want to do one join at a time (if possible) if might also save time.
If you absolutely must do joins in KNIME you should check out the ‚new‘ joiner node since it has been improved.
1 Like
Something to consider also is that if you are able to create a table in your postgres database, then an option is to move your excel “key data” into the database (using knime of course) so that you can do your filtering and joins there. Only once you have your dataset restricted and matched up do you then bring it out of the database.
2 Likes
Can I please meet with someone on Zoom to review my project and discuss more? It’s been stressing me out and I’m worried I won’t be able to finish it in time.
Dear @mcuz91.
Hope you solved your problem. I have never worked with the DB Query type nodes. Mostly CSV and Excel files for me. But I have noted that joiner nodes tend to slow down when the following issues are prevalent in your data:
- If you join on a field with missing values (the red “?”) it slows down
- If your data (especially top table) has too many missing values in the data fields it also slows down. Tidy things with missing value node before going into the next joiner node.
- If bottom table contains more than one row for the same value being linked to the top table, it will duplicate the row in the output (or more than duplicate depending on how many rows with same linked value in the bottom table).
As an example of point three the following (the joiner node performs an inner join linked on column b):
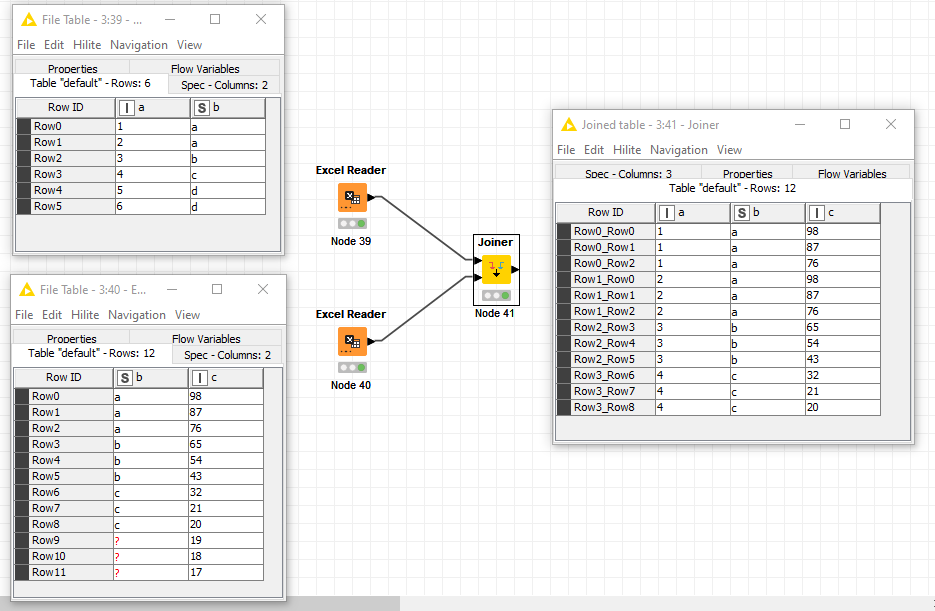
THUS: the 6 row table became a 12 row table. You are dealing with at least 5 million or so rows at the top and 90k in the bottom…I think your data rows might be trying to multiply exponentially, thus trying to create one big happy RAM sapping family.
Hope this helps.
1 Like
Hi @Thinus, I actually got my ETL flow to work now so I’m set. Thanks for the tips!
2 Likes
This topic was automatically closed 182 days after the last reply. New replies are no longer allowed.