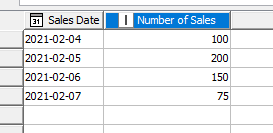
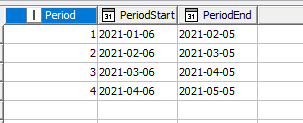
Hi everyone I have a table with data regarding sales per day and one table with the accounting close dates (which are diferent than the civil year).
So I’d like to to add to my first table base on the day of the sale, the accounting dates (beginning and ending )/months and so on…
My first aproach was to use a column expression node where I’d define the intervals of the accounting months, but this makes it “less pretty” lets say. And also since it’s manual errors are more likely to happen as if I use the first table this won’t happen.
This is from a process that is assembled in SAS like this:
proc sql;
create table data_end_month as
select distinct a.*, b.YearMonth_Account, b.Date_Start , b.Date_End, b.Date_Calendar_End
from base1 as a left join Dates_close as b
on b.Date_Start < a.Dt_Venda <= b.Date_End;
quit;
If anyone has any suggestions I’d appreciate it!
Thanks
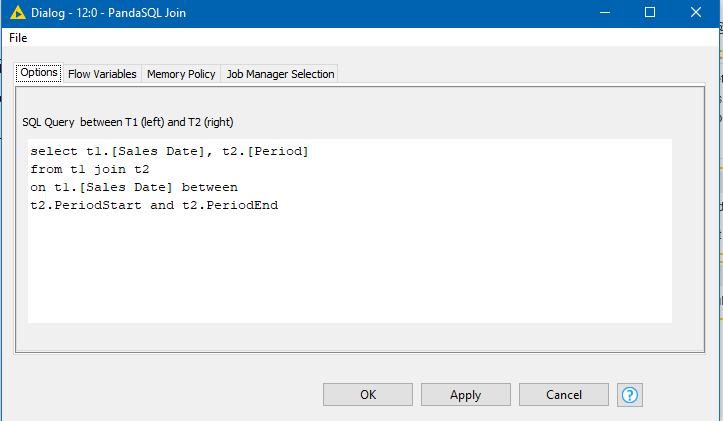
I can’t vouch for its performance or efficiency, but if you have Python installed, along with the pandasql package, you can do your join in a relatively simple python script too.
Simple example:
import pandasql as ps
import pandas as pd
sales_df=input_table_1
period_df=input_table_2
sql="select sales_df.[Sales Date], period_df.[Period] " \
+ " from sales_df join period_df " \
+ " on sales_df.[Sales Date] "\
+ " between period_df.PeriodStart and period_df.PeriodEnd"
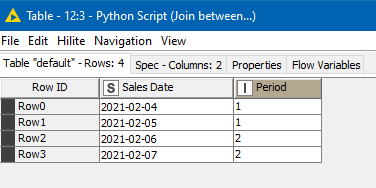
output_table_1= ps.sqldf(sql, locals())
Obviously the joined output could be whatever columns you want, but here I just return the period number for the given sales date.
@AnaMaximino , It’ll be interesting to see how it performs. I’ve not looked into it before, and I’d be amazed if it didn’t need some form of indexing to run well on large data sets. Let us know how you get on and maybe we can work out some refinements, or ability to specify columns to index on the underlying dataframes.