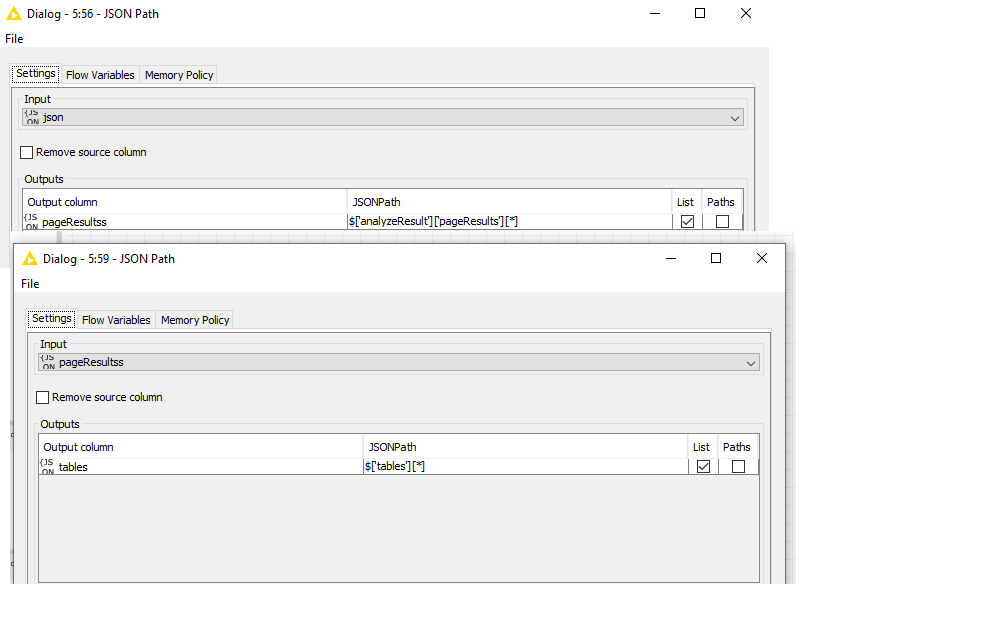
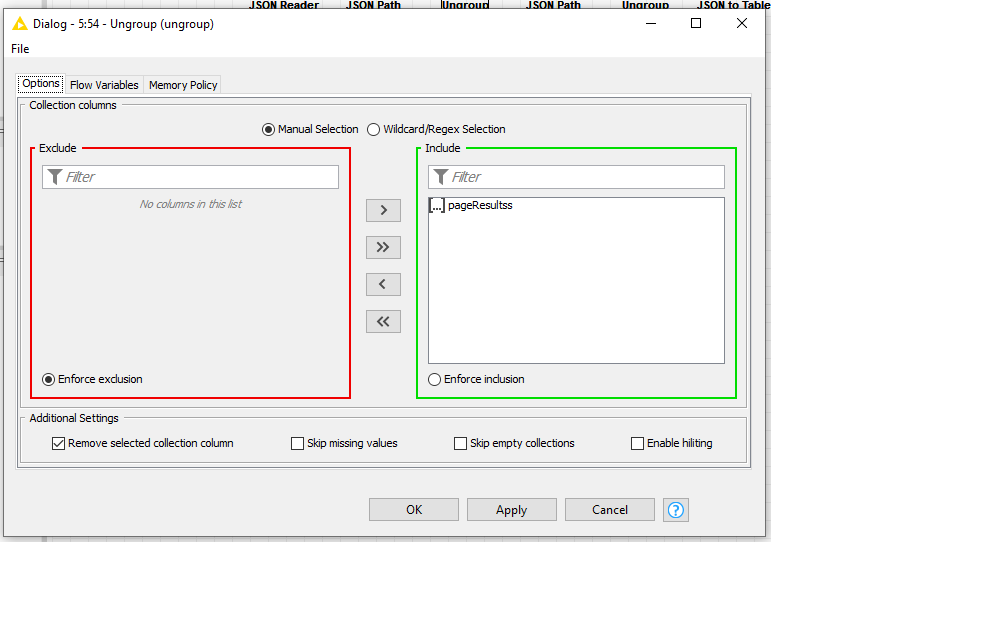
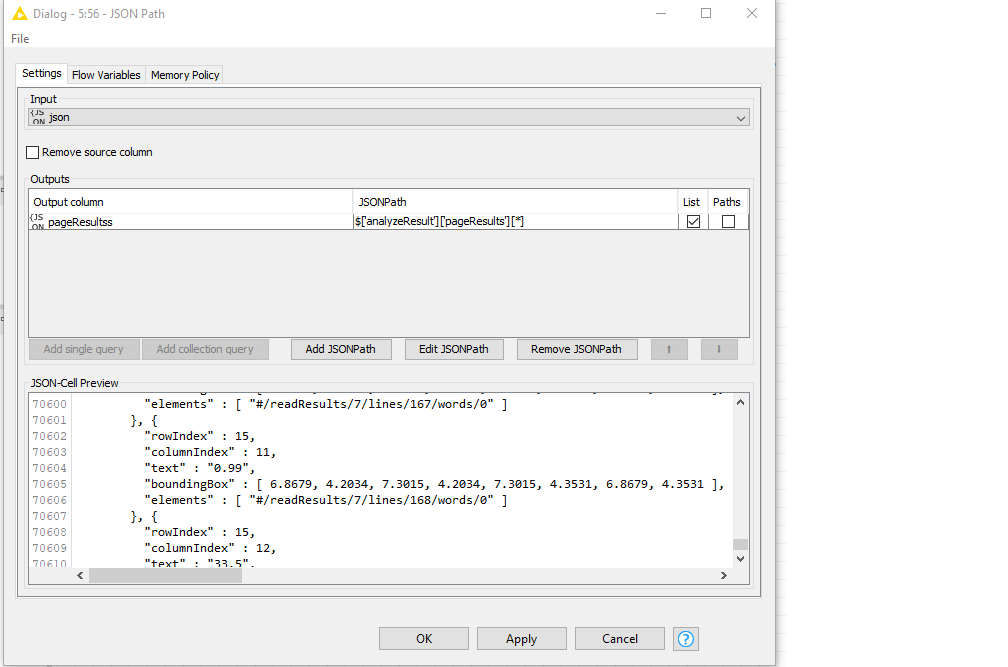
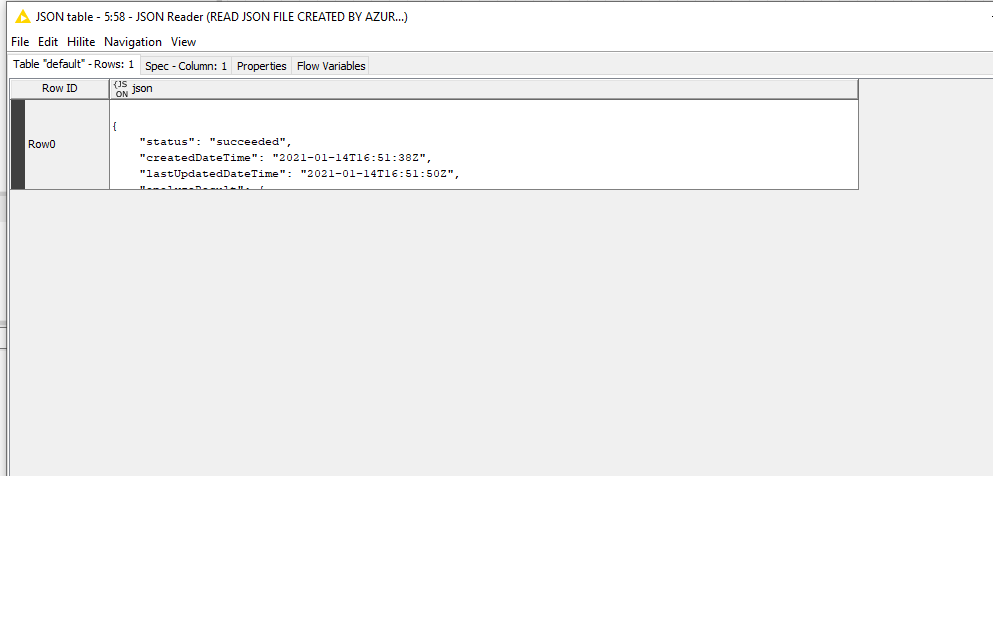
Using azure form recognizer to read PDFs for some data capture.SO after a few trials, I got a clean CSV extract from the JSON file. so far so easy. The problem is with PDFs you can get 2 or 3 tables on a single page, and as they have row and index numbers… if you try to pivot the results from a multi-page PDF you get a mess.

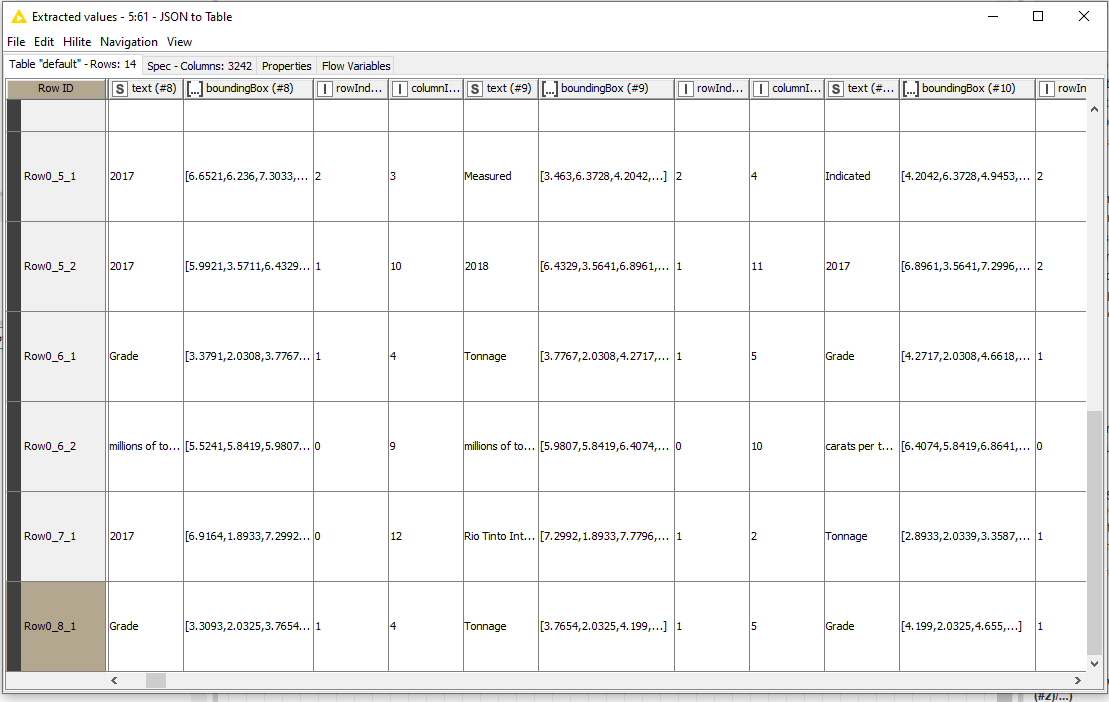
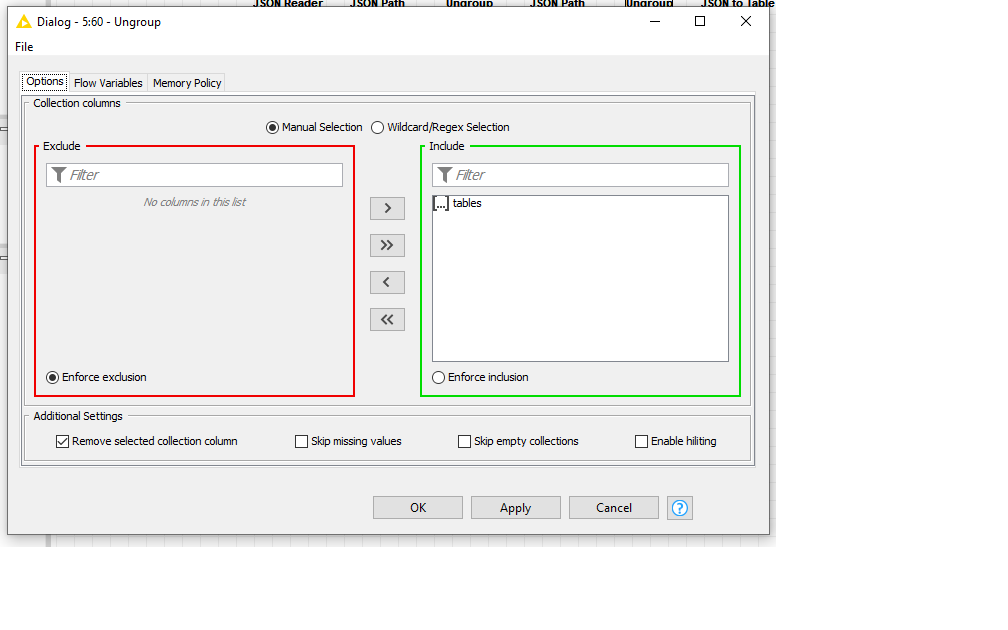
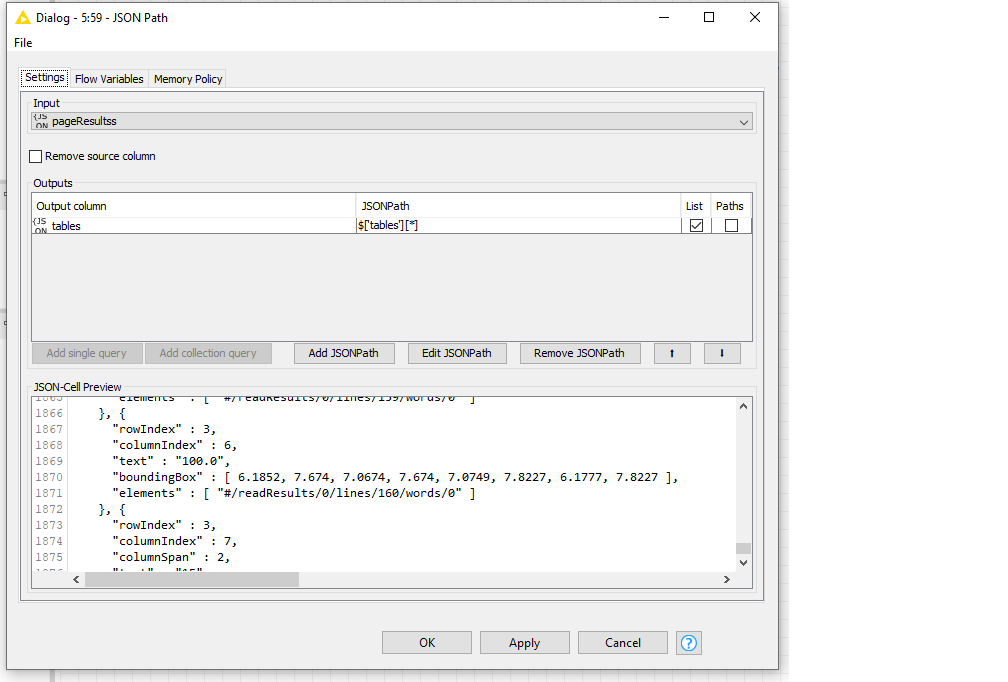
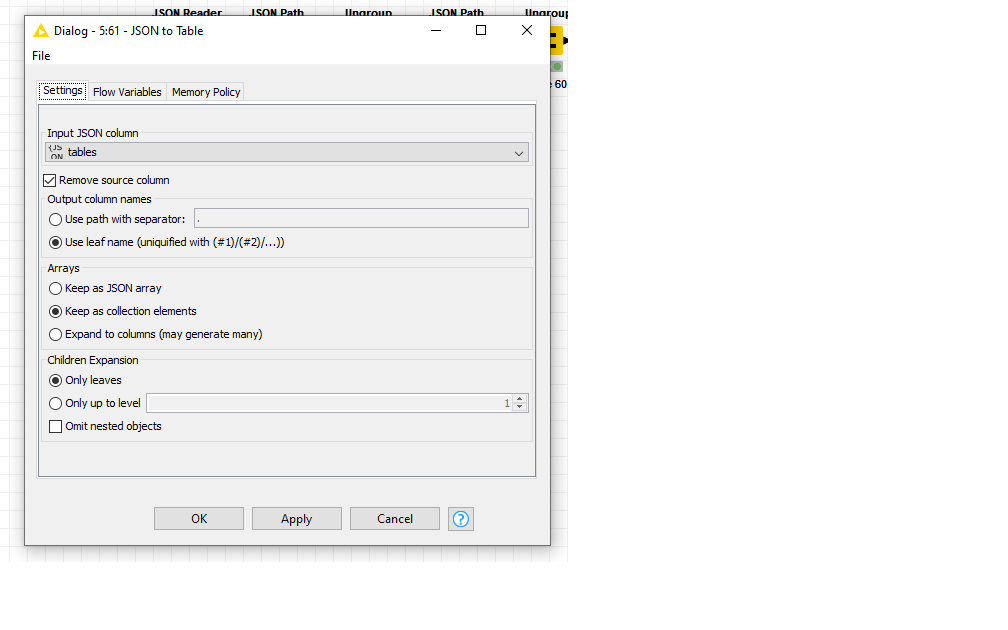
So my new workflow splits every table into a clean “row”. So my JSON to table output (the last step) is ok but ideally, I need to loop through this output and clean it a bit. Because I need to PIVOT on all 8 rows. For each row, i group on “row index” and PIVOT on columnIndex and aggregation is “text”.
SO basically the output should be 14 separate CSV tables…
I have uploaded my workflow and the source file. (JSON)Layout-Result-Pages from 2018 AR RIO (2).json (1.5 MB) 2021-02-01T00:00:00Z