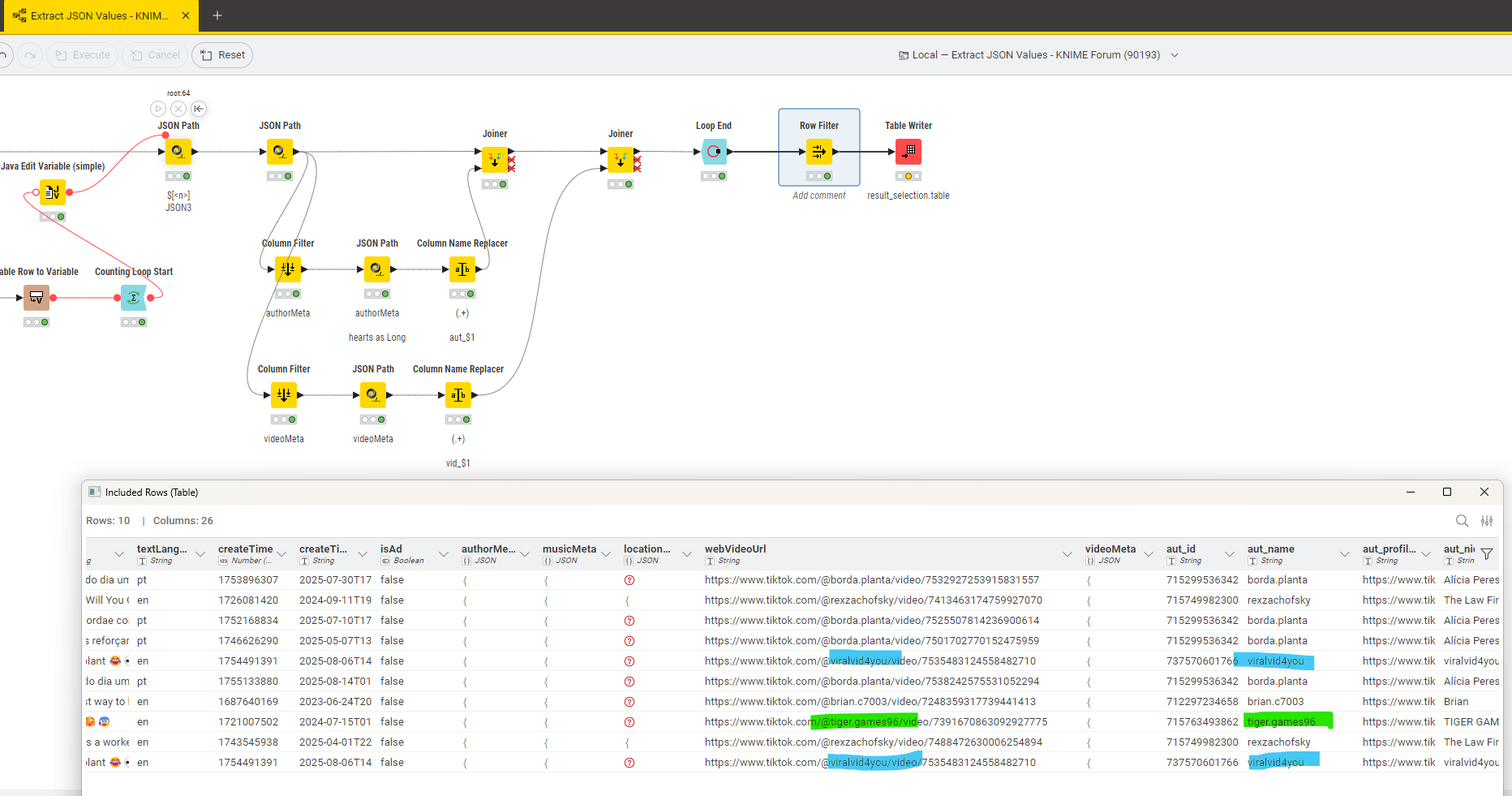
@ace2131 I tried another approach where I iterated over the single blocks inside the JSON and not do a massive ungroup which might lead to problems in the IDs. Here the JSON path is created by a Flow Variable and will isolate one entry:
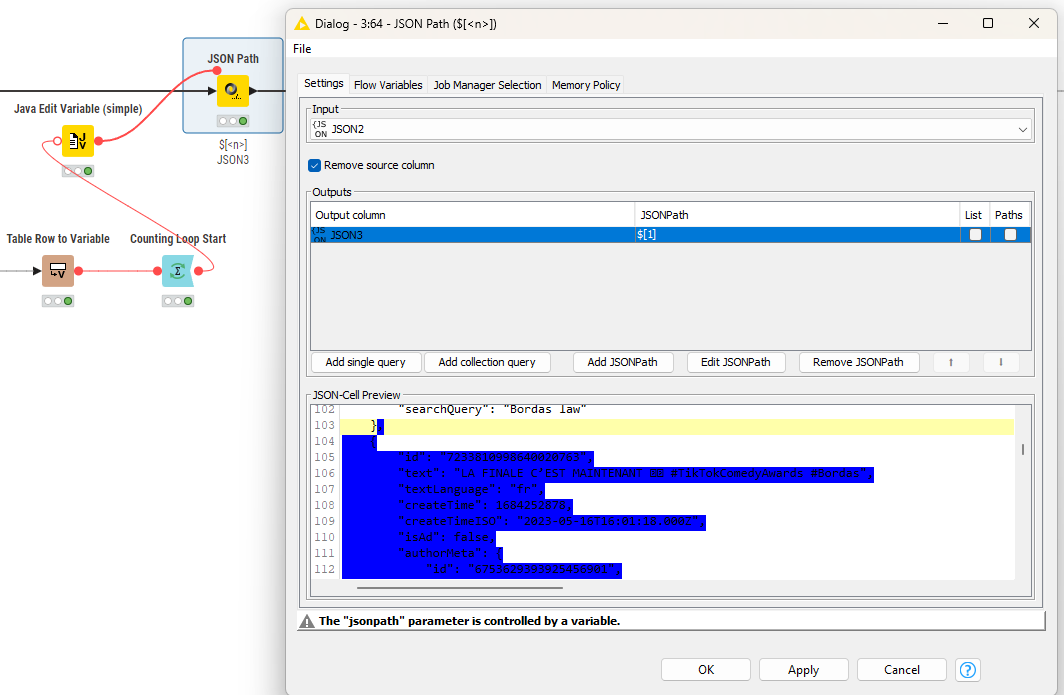
Inside the loop you will have to extract the sub-JSON structures about authors. Also rename the sub-columns to identify to which part they belong:
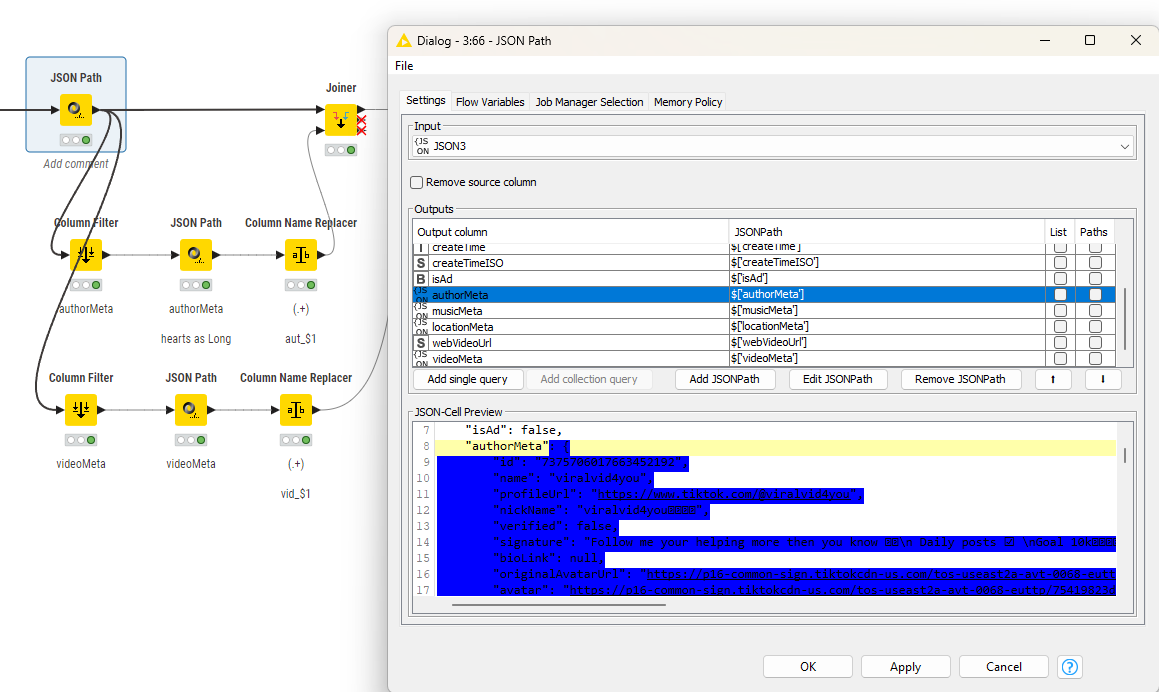
In the end you collect the results and now you can see where the information is. You will have to see if some sub-entries have more than one line (video subtitles) and how to handle that.