So far, the flow loads a set of unformatted addresses from CSV, prepares the strings for use within a query and then POSTS the query using a POST request. All of that works great. When the service returns the addresses it returns them in this format:
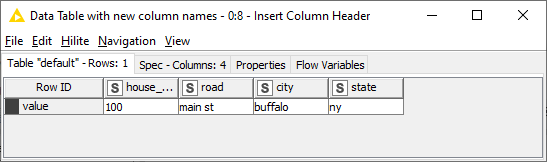
Ultimately, I’d like to transform this JSON response to a set of columns with “ROAD”, “CITY”, “STATE” and so on. The quantity of JSON fields that the service returns varies depending on the input and the order varies as well, also dependent on the input. For instance, there may be more than one postal code identified or the street may be listed after postal code etc.
Unfortunately, the service doesn’t return {“house_number” : “100” “road” : “main st”} or this would be a non-issue.
Any recommendations on resolving this issue using knime node processing?
It would be best if you provided your workflow with sample data that demonstrate the problem.
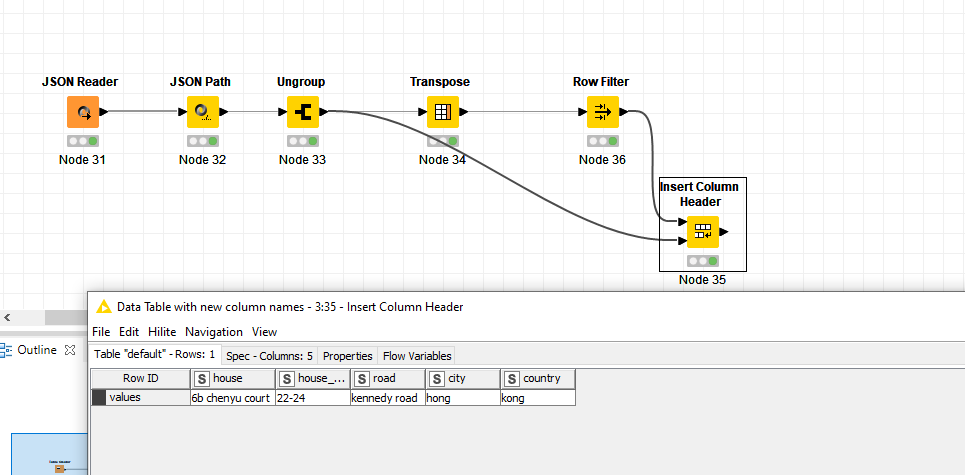
As it stands, the standard response will be to first use the JSON Path node and/or the JSON to Table node to get the data in table format. Then you can do whatever manipulations are necessary. This will probably involve the Transpose node and then some nodes to modify the column headers:
Because there are no repeats in the data it’s impossible to say how well this example workflow will work for your specific situation.
The service should return a json file. Your attached files are csv.
Can you attach the json file the service returns that you want to be converted into the column structure mentioned above?
BR
The script iterates through the list of addresses. For each address, the service is called and a JSON is returned. Each JSON encoded response is then embedded in each csv column titled “BODY”. An example is embedded in the previously attached libpostal csv. Here’s a subset of that example and is exactly what the service returns:
[ {
label : house,
value : 6b chenyu court
}, {
label : house_number,
value : 22-24
}, {
label : road,
value : kennedy road
}, {
label : city,
value : hong
}, {
label : country,
value : kong
} ]