Hello all,
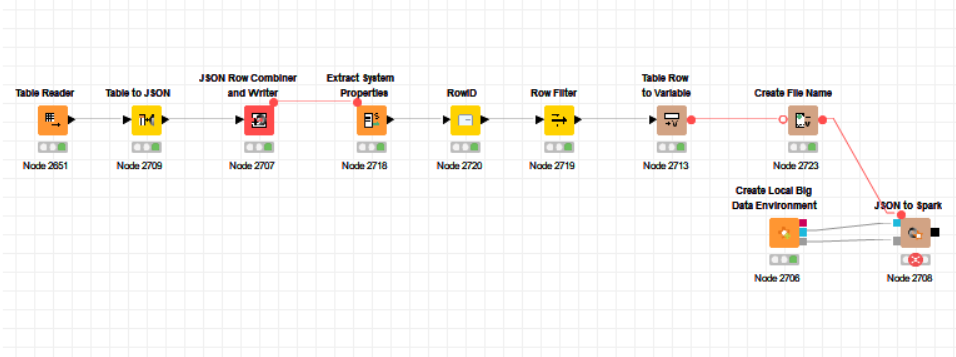
I’m having a problem when using JSON to Spark, it appears that I have to use multiline=true on JSON parsing, but I can’t figure out which node can do that. This is the error I receive on running the workflow:
ERROR JSON to Spark 2:2708 Execute failed: Since Spark 2.3, the queries from raw JSON/CSV files are disallowed when the
referenced columns only include the internal corrupt record column
(named _corrupt_record by default). For example:
spark.read.schema(schema).json(file).filter($“_corrupt_record”.isNotNull).count()
and spark.read.schema(schema).json(file).select(“_corrupt_record”).show().
Instead, you can cache or save the parsed results and then send the same query.
For example, val df = spark.read.schema(schema).json(file).cache() and then
df.filter($“_corrupt_record”.isNotNull).count().; (AnalysisException)
Thanks,