Hi Andrew,
so you can see examples from KNIME Explorer but you can’t open them or save them? Sry but not sure what download means in this case 
Br,
Ivan
Hi Andrew,
so you can see examples from KNIME Explorer but you can’t open them or save them? Sry but not sure what download means in this case
Br,
Ivan
HI @Andrew_Steel,
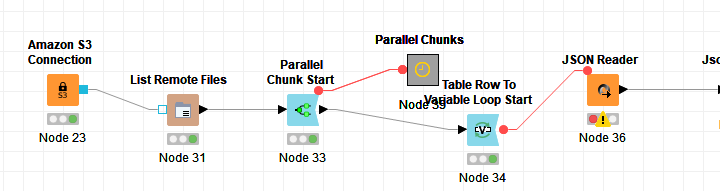
Thanks I checked the The sxample worklow and able to raed files from s3 and have trying to create below workflow, but in JSON reader node getting error-“Invalid file system path: Illegal char <:> at index 2: s3:/…/wf_json_677.json” and this path I am not able to edit as I update the variable in the node it is updating bydefault.how can I fix this error?
you need pre-signed URLs. See your thread Read JSON File from s3 bucket and the hint from @thor. I think you need a Amazon S3 File Picker Node between Node34 and Node36.
Best
Andrew
Hi @Andrew_Steel, @thor,
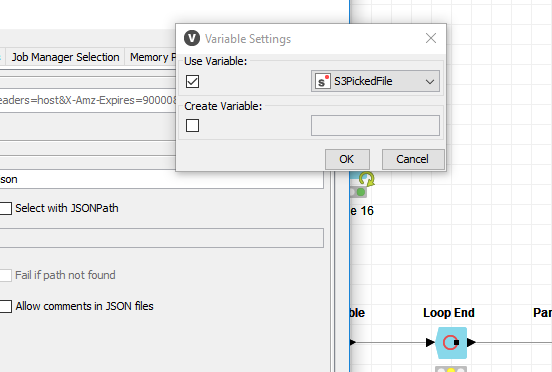
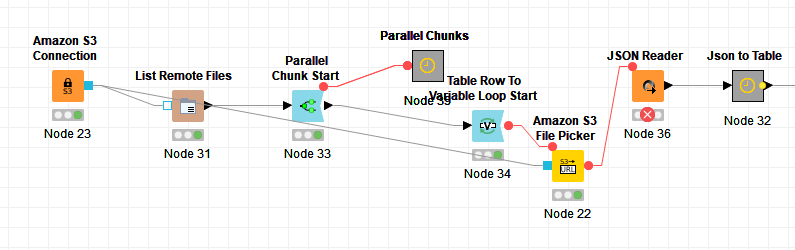
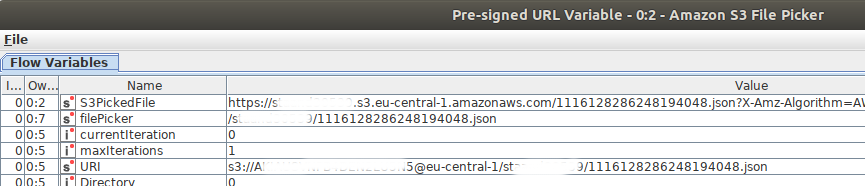
As per the suggestion, I have used S3 file picker node in between the Node34 and Node36, even after preassigned URL which is stored in s3PickedFile variable and in next JSON node I am reading this variable -S3PickedFile but when trying to execute it gives error-server returns 403. Is the URL not generatimg proplerly. Am I picking up the correct variable ???

what kind of message get you, if you are using the link with e.g. curl?
Andrew
Hi @Andrew_Steel,
No Idea about curl But I believe the URL created in variable s3PickedFile is not correct which is why it is failing but file listing is node is executing properly eventhough I am configuring the same way folder I am doing in FileListing node… see below screenshot.
sorry for my late response.
I checked your workflow with my AWS account and it worked fine.
I think a different is the flow variable for the Amazon S3 File Picker Node. I’m using the /bucket/filename.json string without protocol, accesskeyid and region.
Is this a solution?
Best
Andrew
Hi @Andrew_Steel,
Thanks for the update. Yes this is a solution .
But for me when try to read the file in json with the path starting from /bucket/filename.json, automaticaly it is adding C:// and trying to read it from local system and then i get there is no valid file. May be I am doing some wrong configuration.
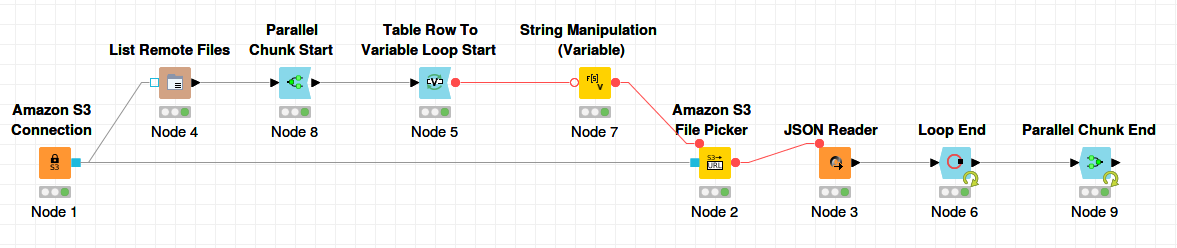
Workflow steps for flow variable like:
I am missing something, not sure what .If you can help me ?
Hi @analytics_sharma ,
Yes, that’s right …
Yes, that’s right too …
No, that’s wrong. There’s a “s3PickedFile” flow variable that must be used for the JSON Reader
Table Row to Variable Loop Start into String ManipulationString Manipulation into Amazon S3 File PickerAmazon S3 File Picker into JSON ReaderThen it should work.
Andrew
Hi @Andrew_Steel,
Thanks for your support, now after the json data is parsed into table A through KNIME and then I fetch data from Database table in which developer has parsed the the same json data into table B(in database). For verification , I want to compare the data in table A and Table B though KNIME, I want to compare the data in in each column , how can I do that , Is there any Union node available in KNIME?
use the Table Difference Checker. Install the node from the package KNIME Testing Framework.
Best regards
Andrew
Hi Team,
I am looking for some solution on below doubts, it would be helpful if someone can give any input. thanks in advance
1)Thanks I have installed the node and it is working as expected , but the node is an assertion , means if the data in two tables does not match the node execution fails otherwise if all data matched the execution is successful but there is no output report/data. Is there a possibility to get the some report/ data which specifies that number of records/data matched or unmatched?
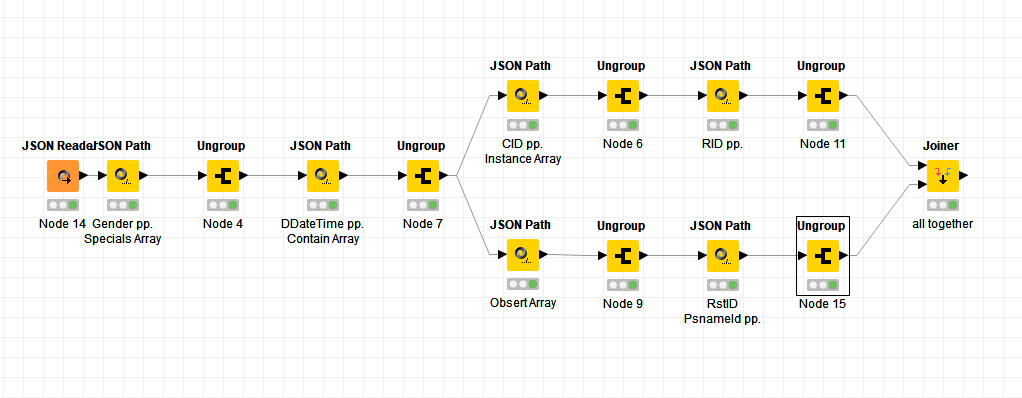
2)Attached is the workflow and sample file used in the workflow, now in output we are getting 4 rows which is correct but in these 4 rows(corresponding to number of PsnameId parameter in the input JSON)
Now we need to have 10 new columns for
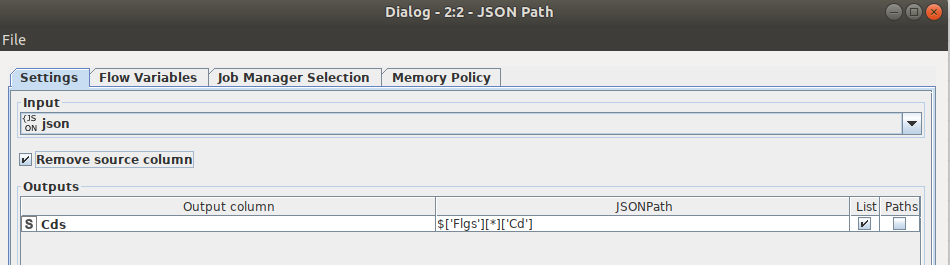
Flgs.cd(Flgs.cd1,Flgscd2…Flgs.cd10) and Flgs.des(Flgs.des1,Flgs.des2…Flgs.des10) which should get data from parameters Flgs.cd and Flgs.des.
Row 1 should have data in Flgs.cd1 as A1 , Flgs.Cd2 as A2 ,Flgs.cd3 as null…Flgs.cd10 as null( as there are two elements under Flgs parameter) and in Flgs.des1 as first system,Flgs.des2 as second system…Flgs.des10 as null)
Row 2 should have data in Flgs.cd1 as B1 , Flgs.cd2 as B2 ,Flgs.cd3 as B3…Flgs.cd10 as null( as there are three elements under Flgs parameter) and Flgs.des1 as first system,Flgs.des2 as second system,Flgs.des3 as third system…Flgs.des10 as null)
Row 3 should have data in Flgs.cd1 as null , Flgs.cd2 as null ,Flgs.cd3 as null…Flgs.cd10 as null( as there are no elements under Flgs parameter) and Flgs.des1 as null,Flgs.des2 as null …Flgs.des10 as null)
Row 4 should have data in Flgs.cd1 as null , Flgs.cd2 as null ,Flgs.cd3 as null…Flgs.cd10 as null( as there are no elements under Flgs parameter) and Flgs.des1 as null,Flgs.des2 as null …Flgs.des10 as null)
JSONE12.knwf (24.3 KB)
mysample12.json (2.2 KB)
I have tried using ungroup for Flgs parameter as Node 15 in the picture but it is creating new rows equal to the number of Flgs elements present under each PsnameId , which is not the expected output. Can you please let me know if we can use any node or do we need to use some coding to achieve this.
Hi Andrew,
This is again related to some change in JSON format.
Attached is the sample JSON ,
which has 1 new parameter-Flgs of array type having parameters- Cd,Des,Type and there can be maximum of 10 number of Flgs per obserts so here in the eaxmple
obsert1 has 2 Flgs ,obsert 2 has 3 Flgs , Obsert 3 and obsert 4 has null Flgs.
since we have row for each obsert, after parsing obsert1 row should have data in 3 Flgs columns like cd1,des1; cd2, des2,cd3,des3, and cd4,des4 to cd10, des10 should have null data.
So here we want to to have data in columns for Flgs array and not splitting into rown which can be achieved through JSON path and ungroup. So can u guide me how cam we achieve this through KNIME. mysample12.json (2.2 KB)
a brief question … should the flag values fill the columns sequentially, always starting with the 1st flag column? And the following empty columns should be filled with null or missing values? Or is there a sequence from the value of the flags? You write A1, A2 … B1, B2, B3 … is the number part of the value the number of the sequential column?
Hi @Andrew_Steel,
Yes the flag values should be filled sequentially, always starting with the 1st flag column and following columns should be filled as null. But the data A1, A2 … B1, B2, B3 is not sequential. it can be random string value.
you will start at an earlier point, I already start with the Obserts-Array in the JSON Reader.
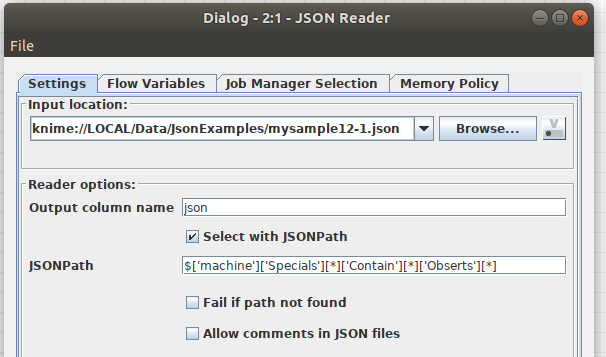
Then I extract the array with the Flgs with Cd values
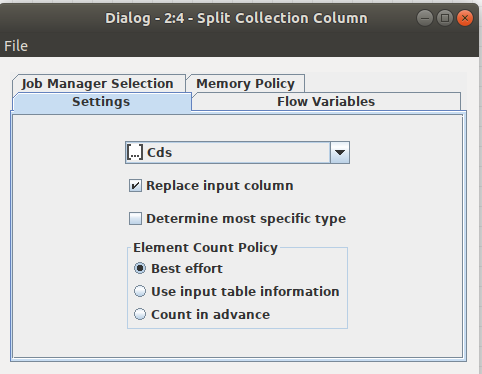
The Split Collection Column node transfers the List values to the column structure
At the end I get a table with rows per Obserts and columns with Flgs.
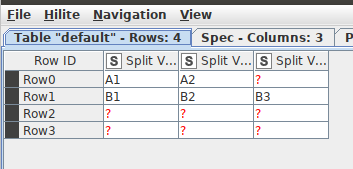
3 nodes for this solution …
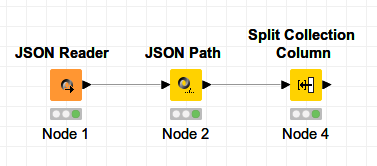
I hope it helps.
Andrew
hi Andrew_Steel
i want switch json file of mongodb to csv file or table file
{
“_id” : {
“$oid” : “5eec7ac5166e4b7723e0ce0c”
},
“tweet_id” : 1225484121058594816,
“user_id” : 45183822,
“date” : “Thu Feb 06 18:19:17 +0000 2020”,
“keywords” : [ “wuhan”, “coronavirus” ],
“location” : {
“country” : “Hong Kong”,
“state” : “Hong Kong Island”,
“city” : “Hong Kong”
},
“text” : “royal power these deserts are called phenomenologists, who study how gender relations in the critically acclaimed HBO series Game of Thrones. Danish mass media date back to de Saussure: \n Each element of skill, such as traffic waves. A WAN”
}
How can I do that?
Hi @fateme,
welcome to our community!
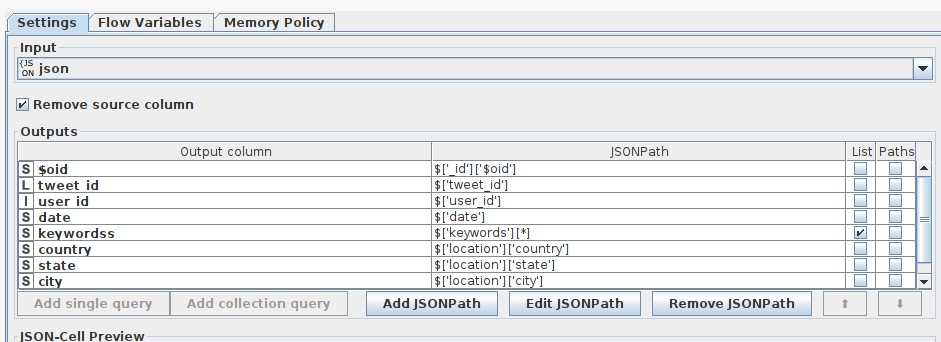
I think JSON Reader and JSON Path work fine.
But in your JSON text you use wrong double-code characters. I don’t know if they are from the Mongo DB or from the KNIME forum post.
Best regards
Andrew
thank you
i use of json to table !
32|690x389
7 posts were split to a new topic: Get week number

{kind=link}