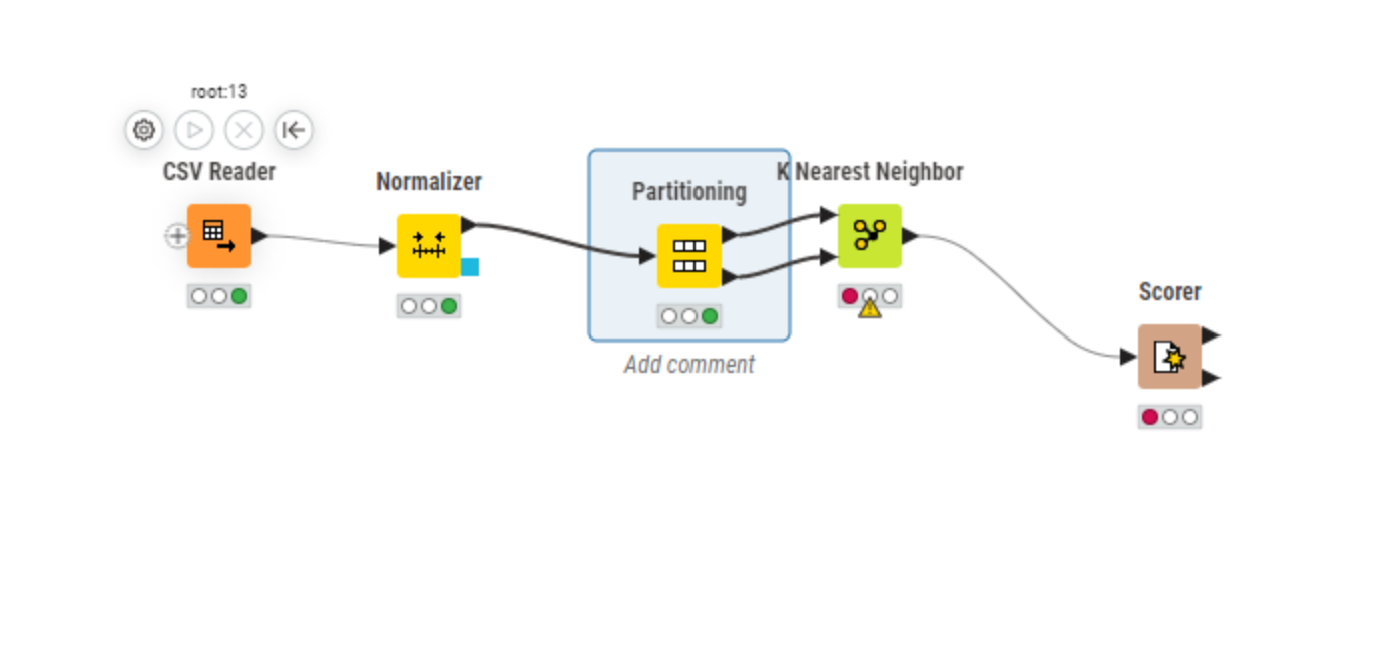
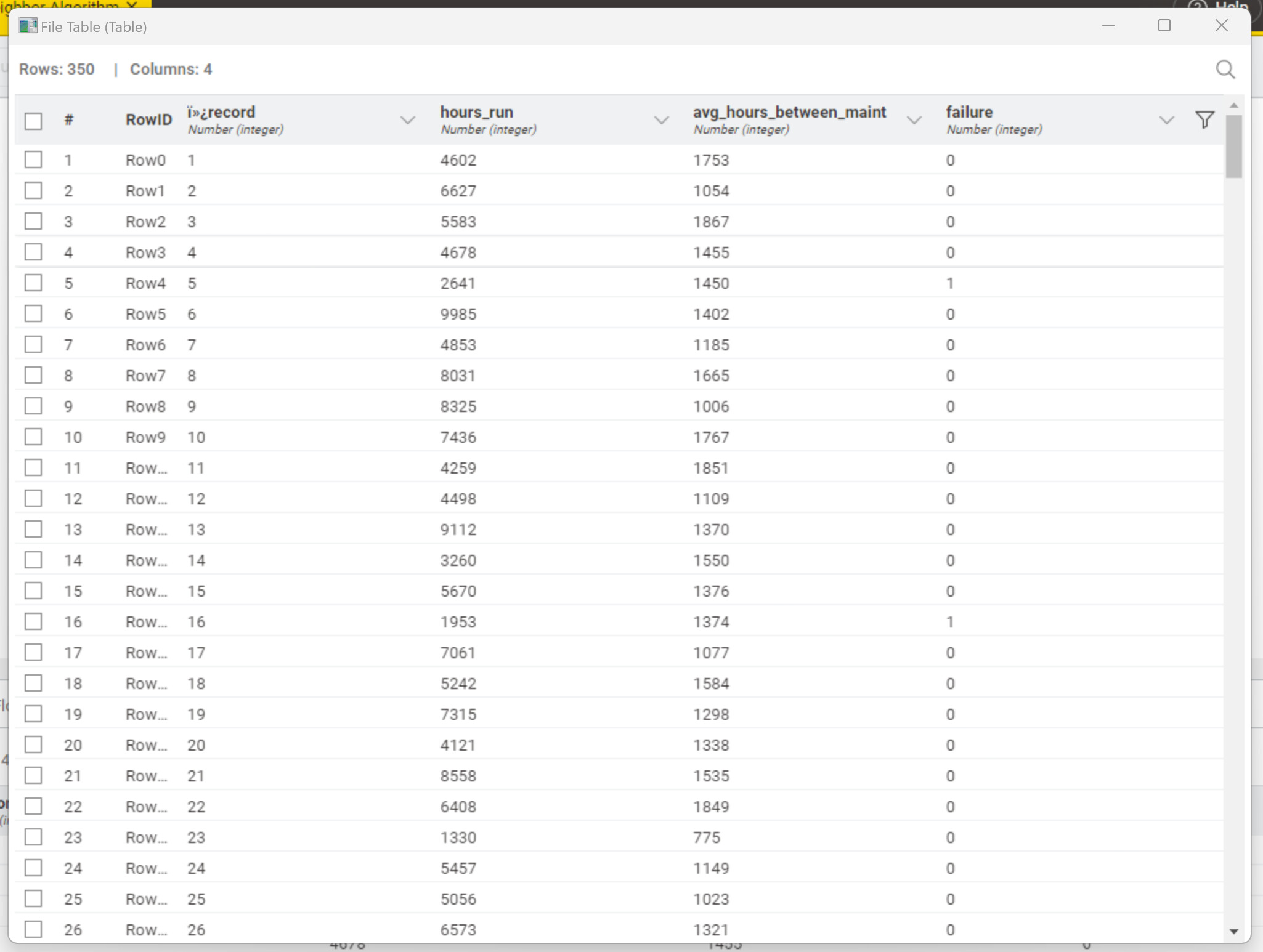
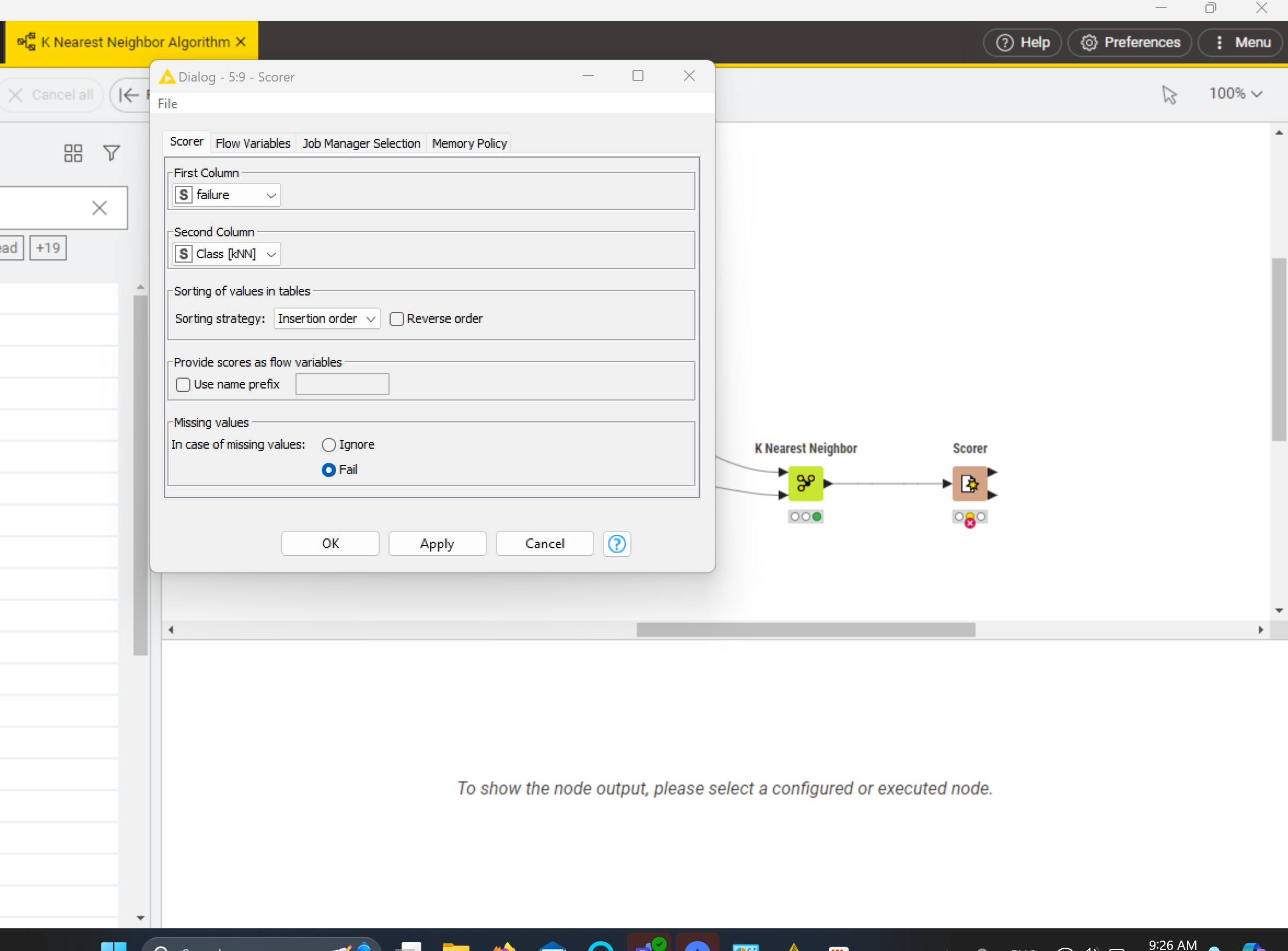
I need assistance with troubleshooting my algorithm. When trying to connect the Partitioning to the K Nearest Neighbor, I presented with an error message "The Dialog cannot be opened for the following reason: No column in spec compatible to “NominalValue”.
I am trying to do the following steps:
Partitioning Node: Using the Partitioning node to split the data into training and test sets. Set the partitioning to 70% Training and 20% Test for records 1-300.
k-Nearest Neighbor Node: Creating a k-Nearest Neighbor node and connect it to the Training data output from the Partitioning node.
Scorer Node: Connect a Scorer node to the k-Nearest Neighbor node. This will evaluate the model’s accuracy using the Test data from the partition.
Table Node: Attach a Table node to the second output port of the Scorer node to view the accuracy results.
Run Model for k Values: Configure the k-Nearest Neighbor node to run the model for k values ranging from 3 to 6.
Would someone be kind enough to check that I have not missed a step?, I have been working on this item for the past week and have search through every single source without a solution.
Pretty hard to help you without knowing what kind of data you are working with. The error is somewhat self-explanatory: missing the correct type of values.
I’d say have a look on the Community Hub, there are a lot of reference examples that you can use and compare to your situation
Sorry. I wasn’t as clear as I could have been. By “target” I meant the column you’re trying to predict, i.e. 'failure." I cleaned up your data and changed the workflow some. This workflow produced 94% accuracy. I assumed the “model” column is a legitimate predictor. You can play with the k if you want.
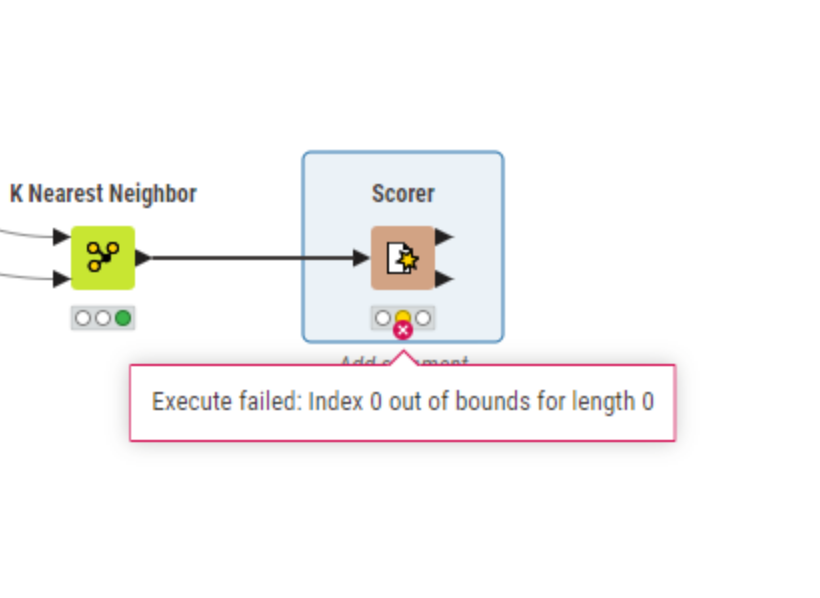
Thank you for the example that you have shared, the last issue I am having is with the scorer, for some reason I keep getting an error with the scorer. Do you think I ran one of the nodes incorrectly? <Error Message: Execute Failed:Index 0 out of bounds for length 0>