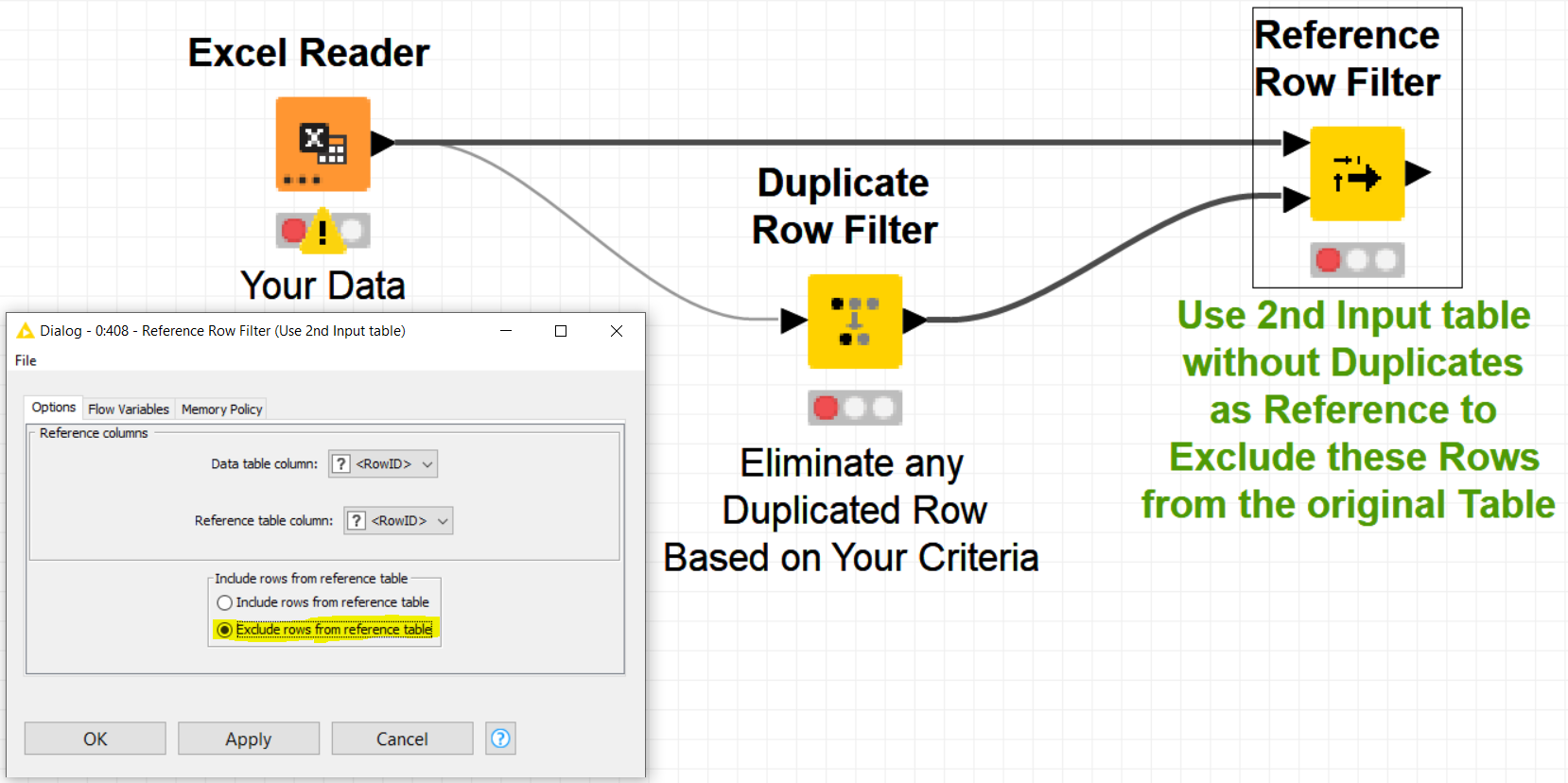
Hello there, very new to Knime (awesome piece of software btw) and still learning the ins and outs. I have a question regarding duplicate entries:
I have a project where we would like to read an Excel file and keep ONLY the duplicated entries of a certain column. After some searching, I could only find topics about how to REMOVE or filter them out, but I would like to achieve the opposite. I’ve tried something with the Rules-based Row Filter node or even the dedicated Duplicate Row Filter node with no avail.
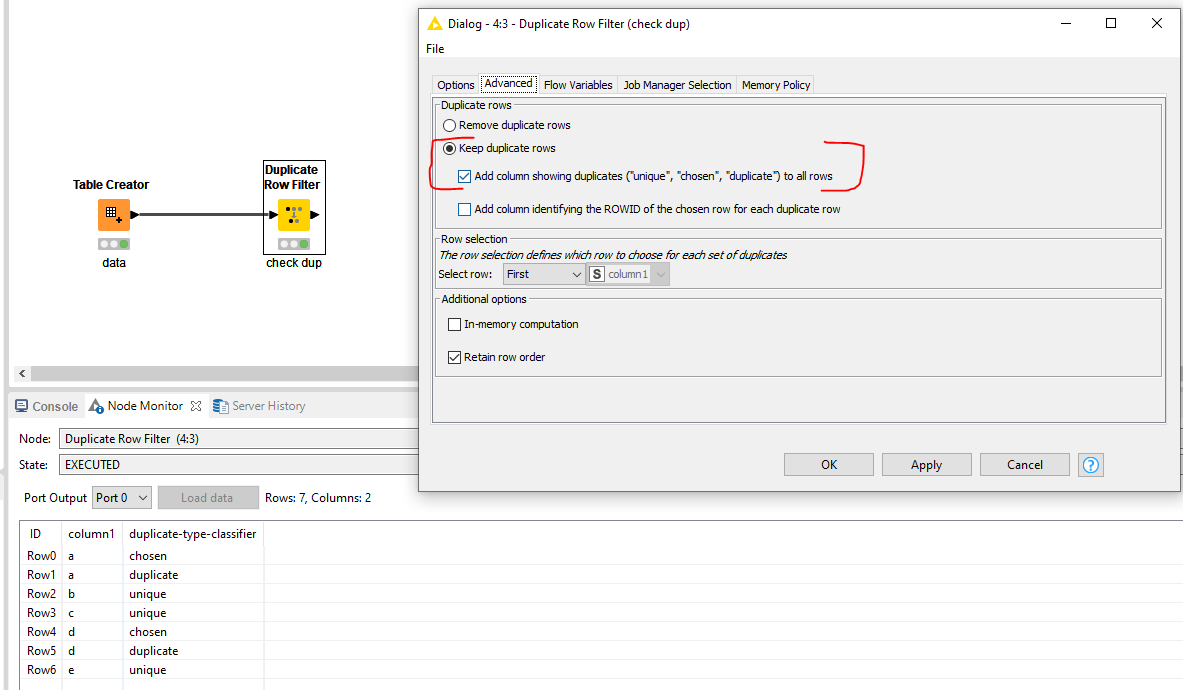
A small trick in addition to what @aworker mentioned: if you go to the Advanced tab of the Duplicate Row Filter, tick the box to “Keep Duplicate Rows” and “Add column showing duplicates”, KNIME will give an indication which rows are unique, it choose to keep and which are classified as duplicate subsequently. You can then keep the desired categories with a type of row filter.
A combination of both approaches solved my problem. Using the Row Filter node after, to throw away everything with the value “unique” from the column “duplicate-type-classifier” did the trick for me.
@aworker Now I am interested,
you haven’t tried running both against big data and give some details by any chance?
That is the only missing peace here. There is no detailed documentation regarding performance differences in Nodes/Workflows. That would be really interesting @ScottF
br
Knowing a bit how the nodes are implemented in Java in KNIME and their underlying KNIME data structure, one doesn’t necessarily always need to experimentally test on data to know when a combination of nodes should work faster than an alternative combination. Sometimes it can be guessed
I guess -Duplicate Row Filter- node is approximately of complexity O(nxN) where n is the number of duplicated rows and N the total number of rows. But this is not relevant for efficiency comparison because both solutions are using once the -Duplicate Row Filter- node.
@ArjenEX solution is of O(nxN) + linear complexity (with respect to the number of rows) because the -Row Filter- node needed afterwards is of O(N) complexity.
@aworker’s solution is of complexity 2 x O(nxN) because the -Reference Row Filter- node is again of O(nxN) complexity.
Thus @ArjenEX solution should be faster. Obviously, this is just a guess or mental approximation but I believe it should not be far of reality
Computational time is something I think of often when I imagine a possible KNIME solution but in this case I was not aware of this extra option (" add column showing duplicates") in its latest version that @ArjenEX is using in his solution. I learnt today a new thing as usually when I visit the KNIME forum !