Hello,
I am familiar with machine learning using python and the scikit-learn package, but I am new to KNIME. I’m investigating the use of KNIME 5.2 as a tool to teach machine learning to students who have no coding background and who fear coding.
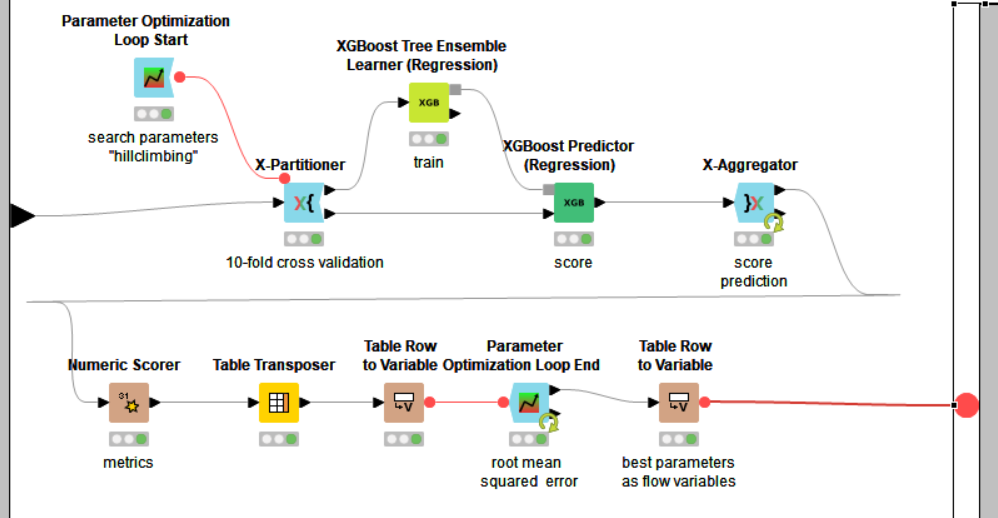
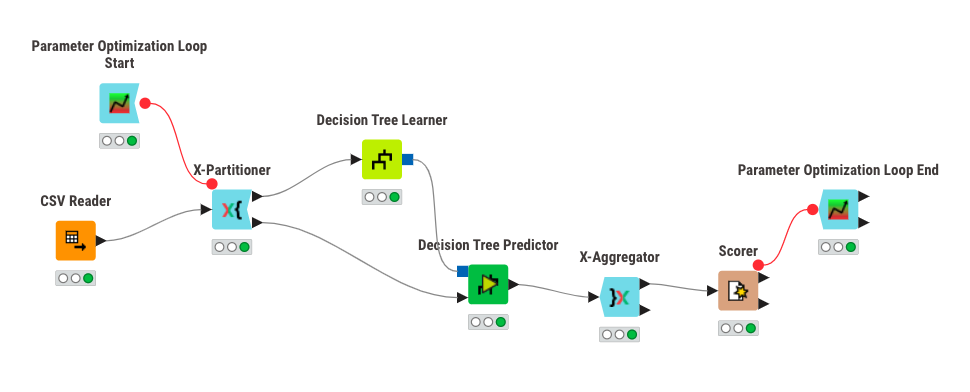
I’ve managed to put together a workflow that implements a grid search to find the value of the minNumberRecordsPerNode parameter to the Decision Tree Learner that maximizes the accuracy on the test data.
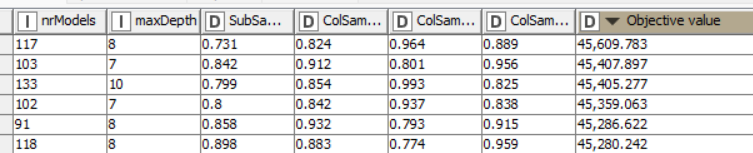
In the Parameter Optimization Loop End node I can find the accuracy metric for each value of the minNumberRecordsPerNode parameter.
I would like to somehow also calculate mean accuracy on the training data for each value of the minNumberRecordsPerNode parameter, but cannot figure out how to make it work. The reason I am trying to do this is that I would like to make a line plot with the minNumberRecordsPerNode parameter on the x-axis and accuracy on the y-axis. Two lines would be plotted, one for training accuracy and one for test accuracy. This plot can serve as a reference for a discussion of overfitting and underfitting.
I’ve tried connecting a second Decision Tree Predictor node to the training data output port of the X-Partitioner and then connecting both Decision Tree Predictor nodes to a Loop End node with two input ports (replacing the X-Aggregator node). This seems to collect only the data from the last iteration of the parameter optimization loop.
Has anyone found a way to do this or something similar? In essence, I have a nested loop (X-Partitioner loop within Parameter Optimization loop) and I want to collect and concatenate accuracy on the training data for each iteration of the Parameter Optimization loop. I will also need to somehow add the parameter setting as a column in the data, so that I can calculate the training accuracy for each value of the minNumberRecordsPerNode setting.
Thanks
MH