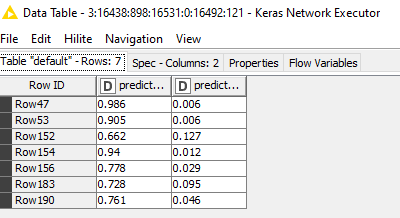
I am not sure if the loss function, or any other parameter in the configuration could be leading to this: I am attempting to solve a binary classification problem, however I have converted my two classes into percent probabilities (i.e. 90% or 0.9 the observation is Class_1, 10% or 0.1 the observation is Class_2). The inputs are doubles as well… My approach may be the reason for this miscalculation. Does anyone have any suggestions? Thank you in advance!
Hi @JoshuaMMorriss,
It seems like nothing in your network architecture forces the network to output a valid probability distribution. During training, you feed in data with a valid probability distribution and you use an appropriate loss function. The network tries to reproduce this but there is nothing forcing it to output values that sum up to 1.
To get a valid probability distribution you can try the “softmax” activation function for the last layer. Alternatively, use the “sigmoid” activation function and only use one output neuron x, and use x as the probability of class 1 and 1-x as the probability of class 2.