Hi there,
I had configured my local environment successfully to work with the Keras extensions. Specifically I was using a Keras Network Learner Node w/o any problems… except for performance on my small machine.
So I went ahead and configured a KNIME server (mount point) offered by my IT department, copied my workflow over to that server and tried it out. I got the following error:
ERROR Keras Network Learner 2:127 Execute failed: Selected Keras back end ‘Keras (TensorFlow)’ is not available anymore. Please check your local installation.
Details: Installation test for Python back end ‘org.knime.dl.keras.tensorflow.core.DLKerasTensorFlowNetwork’ timed out. Please make sure your Python environment is properly set up and consider increasing the timeout (currently 25000 ms) using the VM option ‘-Dknime.dl.installationtesttimeout=<value-in-ms>’.
https://www.knime.com/deeplearning/tensorflow
I figured maybe Python was not configured on the server properly so I went back to the local copy of the workflow… and got the same error message?!
Finding this strange I disconnected from the server and restarted KNIME but still got the error using the local workflow.
So I finally completely removed the server / mount point from my configuration again and now the local workflow runs again.
So for some odd reason having an additional server configured makes the Keras integration somehow fail even when that server is not used and not even connected. Browsing the known issues I couldn’t find anything which seems to be related.
So if anyone has an idea what’s going on that would be highly appreciated!
Thanks
Mark
Edit:
After the problem had disappeared upon removing the server / mounting point I closed KNIME. Just opened it again and tried again and now the error is back despite that server not being configured.
So looks like some sort of instability but maybe not related to the server configuration. It’s strange though that I used this for two weeks on a daily basis w/o any issues and suddenly I get a >50% chance of it failing…
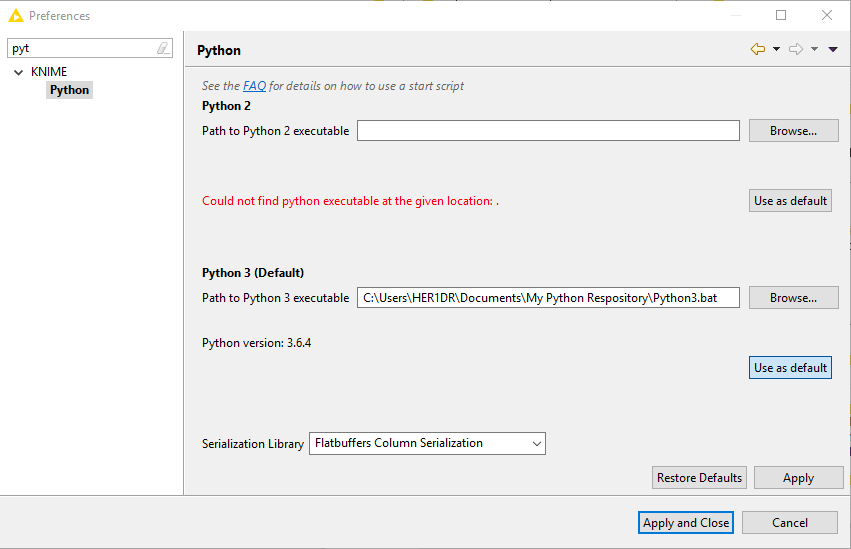
I checked the Python preferences to make sure they did not get corrupted:
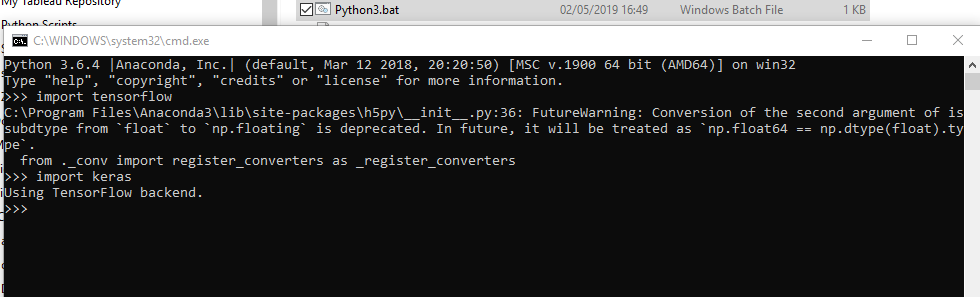
And I ran the *.bat in windows and imported Keras & Tensorflow w/o any issues:
Any idea what could be wrong would be highly appreciated…
Just found this topic, which seems to be the same issue…
Hi Mark,
I’m not sure I 100% followed the issue, but let me try and explain what I think is going on.
- You have Python configured to allow you to run a KNIME workflow using the Keras Deep Learning extension on your local Analytics Platform, and that worked great.
- You added a server mountpoint, and copied the workflow over. You then execute the workflow on the server (e.g. right click the server workflow in the KNIME Explorer, and then choose ‘Execute’. The workflow fails with the error message:
*ERROR Keras Network Learner 2:127 Execute failed…
If my understanding of the above is correct, that would be expected if Python/Keras has not been configured on the KNIME Server. That’s because the server itself would be running the workflow. Your IT team would need to follow the same setup instruction for the Python/Keras environment, and then follow the server specific instructions to enable that functionality on the KNIME Server.
General Python/Keras: https://docs.knime.com/2018-12/deep_learning_installation_guide/index.html#keras_python_installation
Setup Preferences on Server: https://docs.knime.com/2018-12/server_admin_guide/index.html#preferences-file
You could help the IT dept. by sending them the relevant lines from your preferences.epf file (you can export preferences to get that), and they will just need to adapt the paths to the conda environment on the KNIME Server.
I hope that helps. Please let me know if I totally misunderstood the problem.
Best,
Jon
1 Like
Hi Jon,
thanks for your input but this is not the case. What I was trying to say (and sorry if I wasn’t clear) is that after mounting the server executing my old local copy of the workflow doesn’t work stable any more. I completely removed the mountpoint so I was back to my original config and still the workflow in ~ 50% of the cases produced the error.
I went ahead, completely un-installed KNIME and re-installed it. Ever since it’s been working stable again. I dont’t know what screwed up my installation, the timely coincidence with mounting the server made me think it was related but maybe it wasn’t.
Next week it will give it another try with mounting the server and let you know if after that it becomes unstable again.
Cheers
Mark
Hi Jon,
as promised I re-mounted the server after having used my Tensorflow workflow extensively for two days w/o any problems. And you won’t believe this but my locally saved workflow when executed locally (i.e. the server is not involved at any point!) fails again with the same error:
Execute failed: Selected Keras back end ‘Keras (TensorFlow)’ is not available anymore. Please check your local installation.
Not a 100% of the time but >> 50% so I’m confident that the two days w/o problems confirms that somehow mounting and connecting to a server somehows screws up the KNIME/Tensorflow integration on my WIN10 machine.
I will go ahead and re-install KNIME which fixed the problem last time round but it would be great to understand how I can mount a server w/o creating problems with the stability of the Tensorflow integration.
Thanks,
Mark