Hi, I am writing this post because after countless trials I have no idea of the problem. I have done all the procedure to install the extensions to use tensorflow and keras but unfortunately on Gpu it doesn’t work ! When the keras learner node starts in the window where you can see the loss graph and the accuracy graph it doesn’t calculate … It is stopped! I have a laptop MSN gp76 that mounts a card nvidea rtx 3060 … I downloaded a software to benchmark the gpu processor and it works. Can you help me? Thanks
Hello, have you read our guide on GPU x Keras (just need to make sure this has been read):
https://docs.knime.com/2019-06/deep_learning_installation_guide/index.html#keras_python_installation
Have you tried making sure your GPU is compatible with Tensorflow with a different tool aside from KNIME?
Have you checked the workflow runs with CPU settings?
For these problems, it helps to share screenshots and versions of what is installed. Please post the errors you get as well as the workflow you are trying to run.
Good day Victor, thank you for responding…
A) Yes I have read the guide and have performed the recommended special installation.
B) I am not a python expert so I ran a test for cuda with this software to check if my video card supported cuda " https://compubench.com/ " and the test went well. Maybe I should have done a specific test for tensorflow but I don’t know how to do it.
C) yes the workflow works fine with the CPU after replacing the CudnnGRU node with the GRU node to make it work on CPU
D) I insert some screenshots of the software of the installed one and the errors… there is only one warning that says:
"WARN Keras Network Learner 0:6017 C:\Users\Nio2.conda\envs\py3_knime_dgpu\lib\site-packages\keras\engine\saving.py:292: UserWarning: No training configuration found in save file: the model was not compiled. Compile it manually. "
thank you

test_gpu_project.knwf (593.2 KB)
Hi Victor… can you help me ?
Hi @antoniovisone , sorry for the late response. We still need to know if the problem is KNIME or the GPU, so I’d be best if you can show us a python script (in jupyter lab etc.) where you can use your GPU with keras.
This may work: How do I know I am running Keras model on gpu? - Ke Gui - Medium
The only issue with that article is that it is from 2018, so the code may have changed slightly. Without knowing if your gpu is compatible with keras, we won’t be able to move forward, so please let me know how that goes.
Could you also tell me your knime version and what OS (windows?). Thanks
Hi Victor
I took some time to figure out how to do the test to check if there are any problems with the GPU as you suggested …
I did the test as it is in the link you sent me and I think for the GPU there is no problem, it works. I did the test on the configuration made in automatic for the use of the gpu from knime and it seems to me that everything is ok. I insert the file of the test result
The version of knime i’m using is “KNIME 4.5.2” while the operating system is windows 10 home edition with Intel(R) Core™ i7-10870H CPU @ 2.20GHz 2.21 GHz, 32 gb ram and NVIDEA GeForce 3060 Laptop GPU… is a MSI laptop model GP76 Leopard.
What is the next step I need to take?
the attached file is the result of the test
test tensorflow.txt (4.1 KB)
Hi @antoniovisone,
I’m asking internally because I’ve been told this issue was recently reported by another user as well. I will get back to you next week if I have results. If not, I can only recommend using a Python Script node to run your script instead of the Keras KNIME Nodes or using your CPU for the task.
Thank you Victor for your answer… with the Python script I have not tried because I should first study the programming language! But I want to try if it helps to get around the problem
With the cpu I’m already working for a long time but since the models have become very complex I need to use the gpu.
Also I wanted to understand why the node that is used for the GPU has less parameters than the CPU one? in the options section in the node “Keras CuDNN GRU Layer” is missing the activation function and the recurring activation function, these are present in the node “Keras GRU Layer” … the two nodes should not be equal?
PS can you point me to the post of the other user with the same problem ?
I investigated and it seems, the Keras CuDNN GRU Layer doesn’t have options for the activation/recurring function: https://www.reddit.com/r/learnmachinelearning/comments/kmtcej/why_does_cudnn_in_tensorflow_keras_only_require/
The other person who reported the problem was not found on the forum but it was reported to our team.
1 Like
Good day Victor, thanks for your answer
I saw that the activation function and the recurring activation function are already built into the node and can only be tahn and sigmoid to run on the GPU.
Then I tried to insert the node “Dl Python network editor” to check tensorflow backend … and I could verify that the problem is maybe in the tensorflow backend because the “worning” is before the “CuDNN GRU layer” node. I attach images of the test
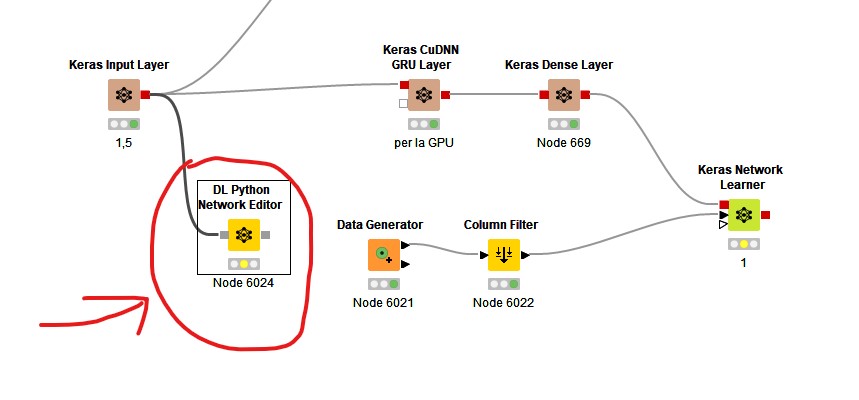
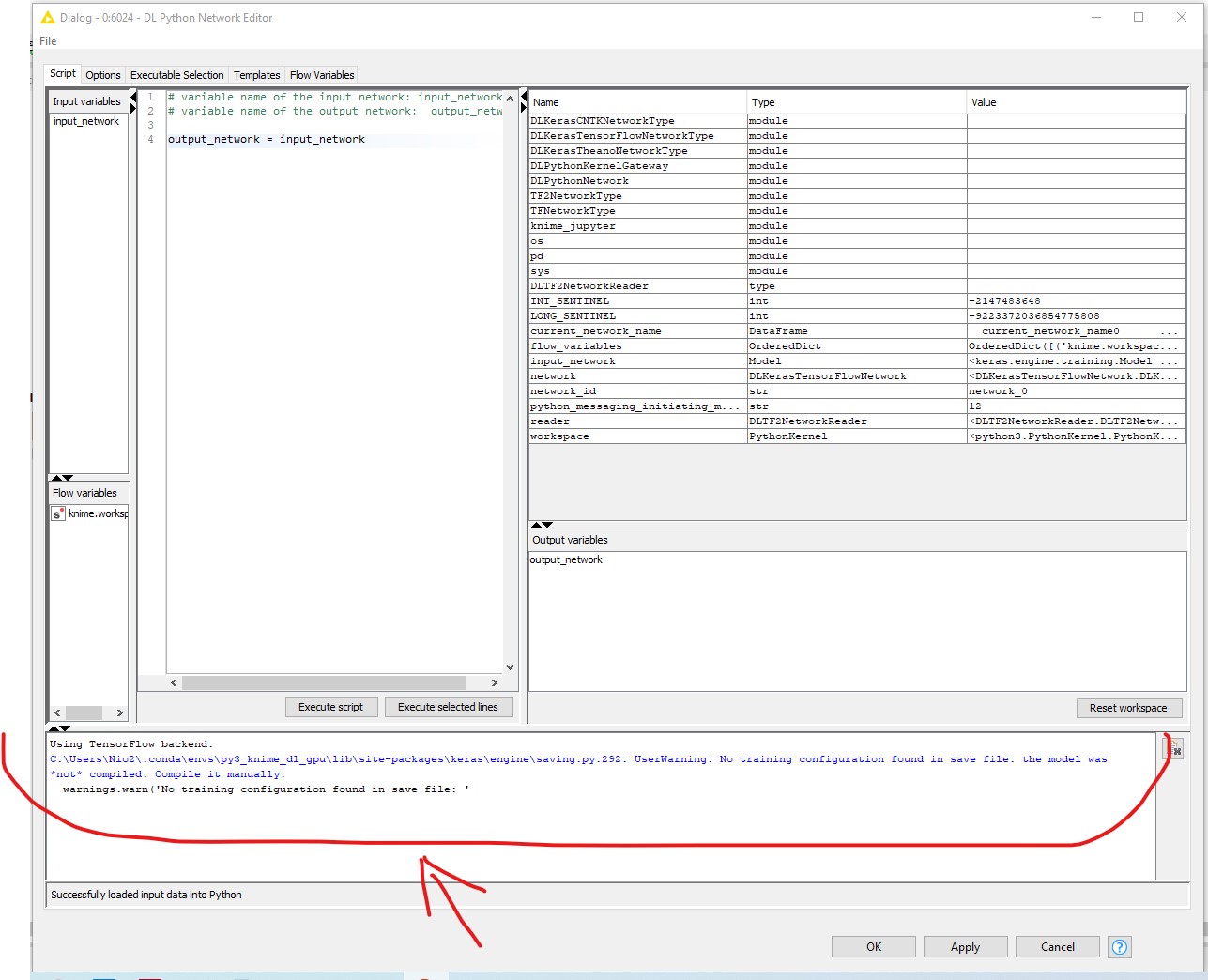
1 Like
Good morning Victor, I wanted to know if you have any news. In case I have to give up because I don’t know how to do it. Thank you
Hi @antoniovisone,
Sadly, we can’t reproduce your issue and we don’t have a very similar system available. I have a few more notes that could help to debug the problem:
- The warning about no training configuration that is available is not important here and actually it is expected. The Keras package logs this warning when loading a model that is not compiled. We only compile the model before training it.
- If I see it correctly, you checked that TensorFlow can detect the GPU but you haven’t tried using it. You could try the following script to just run something using the GPU:
import numpy as np
from keras import Sequential
from keras.layers import CuDNNGRU, Dense, GRU
model = Sequential()
model.add(CuDNNGRU(2, input_shape=(2, 2))) # Or: model.add(GRU(2, input_shape=(2, 2))) for non-cuDNN version
model.add(Dense(2))
model.compile(loss="mse", optimizer="adam")
x = np.random.rand(1024, 2, 2)
y = np.random.rand(1024, 2)
model.fit(x, y, batch_size=32, epochs=100)
I am sorry that I can’t give a definite answer on how to solve the issue.
Best,
Benjamin
Hi Bwilhelm
I thank you for your reply.
I inserted the code you wrote in the “DL Python Network Creator” node … I executed the script and I attach you the screenshot with the text it gave me at the end of execution.
What do you think?
this is the result:
Using TensorFlow backend.
Epoch 1/100
2022-05-24 18:02:53.548080: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX AVX2
2022-05-24 18:02:53.644455: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1432] Found device 0 with properties:
name: NVIDIA GeForce RTX 3060 Laptop GPU major: 8 minor: 6 memoryClockRate(GHz): 1.702
pciBusID: 0000:01:00.0
totalMemory: 6.00GiB freeMemory: 5.04GiB
2022-05-24 18:02:53.644735: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1511] Adding visible gpu devices: 0
2022-05-24 18:06:08.050124: I tensorflow/core/common_runtime/gpu/gpu_device.cc:982] Device interconnect StreamExecutor with strength 1 edge matrix:
2022-05-24 18:06:08.050279: I tensorflow/core/common_runtime/gpu/gpu_device.cc:988] 0
2022-05-24 18:06:08.050396: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1001] 0: N
2022-05-24 18:06:08.050613: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1115] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 4771 MB memory) → physical GPU (device: 0, name: NVIDIA GeForce RTX 3060 Laptop GPU, pci bus id: 0000:01:00.0, compute capability: 8.6)
2022-05-24 18:23:39.688765: E tensorflow/stream_executor/cuda/cuda_dnn.cc:82] CUDNN_STATUS_EXECUTION_FAILED
in tensorflow/stream_executor/cuda/cuda_dnn.cc(1501): ‘cudnnRNNForwardTraining( cudnn.handle(), rnn_desc.handle(), model_dims.seq_length, input_desc.handles(), input_data.opaque(), input_h_desc.handle(), input_h_data.opaque(), input_c_desc.handle(), input_c_data.opaque(), rnn_desc.params_handle(), params.opaque(), output_desc.handles(), output_data->opaque(), output_h_desc.handle(), output_h_data->opaque(), output_c_desc.handle(), output_c_data->opaque(), workspace.opaque(), workspace.size(), reserve_space.opaque(), reserve_space.size())’
2022-05-24 18:23:39.689702: W tensorflow/core/framework/op_kernel.cc:1273] OP_REQUIRES failed at cudnn_rnn_ops.cc:1221 : Internal: Failed to call ThenRnnForward with model config: [rnn_mode, rnn_input_mode, rnn_direction_mode]: 3, 0, 0 , [num_layers, input_size, num_units, dir_count, seq_length, batch_size]: [1, 2, 2, 1, 2, 32]
Failed to call ThenRnnForward with model config: [rnn_mode, rnn_input_mode, rnn_direction_mode]: 3, 0, 0 , [num_layers, input_size, num_units, dir_count, seq_length, batch_size]: [1, 2, 2, 1, 2, 32]
[[{{node cu_dnngru_1/CudnnRNN}} = CudnnRNN[T=DT_FLOAT, _class=[“loc:@training/Adam/gradients/cu_dnngru_1/CudnnRNN_grad/CudnnRNNBackprop”], direction=“unidirectional”, dropout=0, input_mode=“linear_input”, is_training=true, rnn_mode=“gru”, seed=87654321, seed2=0, _device="/job:localhost/replica:0/task:0/device:GPU:0"](cu_dnngru_1/transpose, cu_dnngru_1/ExpandDims_1, cu_dnngru_1/Const_1, cu_dnngru_1/concat)]]
[[{{node loss/mul/_75}} = _Recvclient_terminated=false, recv_device="/job:localhost/replica:0/task:0/device:CPU:0", send_device="/job:localhost/replica:0/task:0/device:GPU:0", send_device_incarnation=1, tensor_name=“edge_648_loss/mul”, tensor_type=DT_FLOAT, _device="/job:localhost/replica:0/task:0/device:CPU:0"]]
Traceback (most recent call last):
File “”, line 15, in
File “C:\Users\Nio2.conda\envs\py3_knime_dl_gpu\lib\site-packages\keras\engine\training.py”, line 1039, in fit
validation_steps=validation_steps)
File “C:\Users\Nio2.conda\envs\py3_knime_dl_gpu\lib\site-packages\keras\engine\training_arrays.py”, line 199, in fit_loop
outs = f(ins_batch)
File “C:\Users\Nio2.conda\envs\py3_knime_dl_gpu\lib\site-packages\keras\backend\tensorflow_backend.py”, line 2715, in call
return self._call(inputs)
File “C:\Users\Nio2.conda\envs\py3_knime_dl_gpu\lib\site-packages\keras\backend\tensorflow_backend.py”, line 2675, in _call
fetched = self._callable_fn(*array_vals)
File “C:\Users\Nio2.conda\envs\py3_knime_dl_gpu\lib\site-packages\tensorflow\python\client\session.py”, line 1439, in call
run_metadata_ptr)
File “C:\Users\Nio2.conda\envs\py3_knime_dl_gpu\lib\site-packages\tensorflow\python\framework\errors_impl.py”, line 528, in exit
c_api.TF_GetCode(self.status.status))
tensorflow.python.framework.errors_impl.InternalError: Failed to call ThenRnnForward with model config: [rnn_mode, rnn_input_mode, rnn_direction_mode]: 3, 0, 0 , [num_layers, input_size, num_units, dir_count, seq_length, batch_size]: [1, 2, 2, 1, 2, 32]
[[{{node cu_dnngru_1/CudnnRNN}} = CudnnRNN[T=DT_FLOAT, _class=[“loc:@training/Adam/gradients/cu_dnngru_1/CudnnRNN_grad/CudnnRNNBackprop”], direction=“unidirectional”, dropout=0, input_mode=“linear_input”, is_training=true, rnn_mode=“gru”, seed=87654321, seed2=0, _device="/job:localhost/replica:0/task:0/device:GPU:0"](cu_dnngru_1/transpose, cu_dnngru_1/ExpandDims_1, cu_dnngru_1/Const_1, cu_dnngru_1/concat)]]
[[{{node loss/mul/_75}} = _Recvclient_terminated=false, recv_device="/job:localhost/replica:0/task:0/device:CPU:0", send_device="/job:localhost/replica:0/task:0/device:GPU:0", send_device_incarnation=1, tensor_name=“edge_648_loss/mul”, tensor_type=DT_FLOAT, _device="/job:localhost/replica:0/task:0/device:CPU:0"]]

Ho Benjamin… Can you help me … Please ?
Sorry for the late reply. I missed your first post.
Sadly, I suspect an incompatibility between the CUDA and Cudnn versions required by the TensorFlow version we are using (CUDA 9.0, Cudnn 7, TF 1.12) and your GPU. However, I could not confirm (or disconfirm) that when searching for it online.
What happens if you use the commented code in line 6 of the snippet I posted above (GRU instead of DuDNNGRU)?
Iʻm bumping up this thread as I also face the same problem. I have an Nvidia GeForce RTX 2060 with Max Q Design GPU on my Dell XPS (i9, 64GB RAM) and I have a DL Python Network Learner node with which I would like to use the computing power of my GPU. I have set up a Conda GPU environment and a Tensorflow GPU environment but the node is not using the GPU.
I have added the Conda installation directory to the system PATH environment variable. Did the same for Tensorflow.
Neither will use the GPU.
Your input would be greatly appreciated.