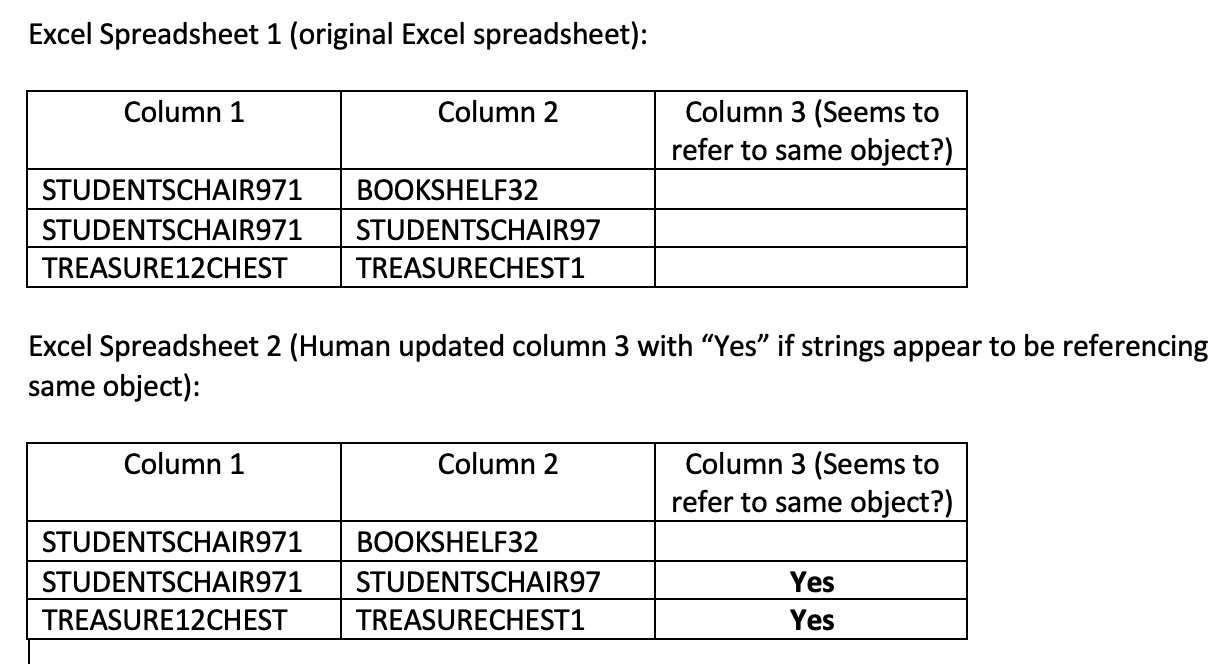
The purpose of the model would be to learn how the human would update column 3 with “Yes” when the person believed Column 1 and Column 2 values seemed to refer to same object.
The model would then tag “Yes” in the same way the human would for future spreadsheets.
Very new to Keras, hoping to get an idea on how this would be built! Especially, which nodes would be recommended.
Note: Please do not mention String Matcher node (already used for initial data prep)
This is an interesting idea for learning your way around Keras!
We don’t currently have workflows to do this type of string comparison on the Hub. I googled around a bit and found a couple of Github repos that contain some interesting approaches for using Siamese networks in a text similarity context. The second repo is based on the first:
Now, if you’re less interested in this particular use case, and just more generally trying to wrap your head around how KNIME works together with Keras and Tensorflow in processing textual data, there are some workflows on the Hub that can help. One is for predicting classification of movie reviews, and the other is for free generating text for product names:
I will say that Keras is probably overkill for this particular use case, as there are distance calculation nodes in KNIME like Similarity Search (as well as python libraries like fuzzywuzzy and others) that can help with fuzzy matching without a full deep learning approach.
This sounds like it could be a fun project, so if you tackle it, please feel free to post your progress here.