This is not a problem solving request, rather a call of action to walk on an overlooked path.
So … recently I’ve came across various Medium & YouTube content by familiar faces here, producing workflows related to using Knime to interact with AI.
Some resources on the hub which I think are very specific include these below, and as you can see, we only have a few:
Correct me if I’m wrong. So far, our prompt is still text-based, right?
I envision that KNIMErs will appreciate a different way to interact with AI as we go further towards the future. I visualize us speaking with our KNIME platform directly, followed by the audio being transcribed into text to be used as prompt to query the AI.
This means that instead of using audio files like our current KNIME Audio Processing Extension does things (which by the way will be turned legacy), we use our device microphone to capture “realtime speech”.
A lot of community-developed apps on the KNIME Hub will embrace this new way of interaction.
Here are some external resources I have found through Google search that you peeps might be interested in:
Article 3 - i like this one, since its one of the few articles I found that incorporate pressing keyboards as a termination signal
All of these are Python-based solutions, so I hope that those here who have vast knowledge in Python can help pave the way to add the first KNIME implementation in the hub showing how to build a voice-based AI agent in KNIME.
love this type of discussion - and as someone who is keen to experiment with these type of things it really makes more curious to find out more:
I take that when you talk about voice-based Agents you mean the ability to have built-in voice-to-text in a chat-based data app that is running on the KNIME hub?
I.e. rather than typing in your question to your Chatbot or RAG Agent into the Data App UI, you have a “mic” button, which you hold down whilst speaking and the what you say is then turned into text?
Or rather than typing in your request to K-AI in e.g. Python Script Node or Expression Node you just talk to it and your speech is converted to text?
I think that is a very interesting idea.
Do you see the speech-to-text processing straight in KNIME or rather KNIME takes care of getting the voice recording and it is then processed by some provider via API?
Honestly speaking right now, at least from a Python Extension Development perspective, my first blocking point is how to built the button that triggers the recording…
In the context of developing a community app, we can be flexible. I personally prefer the app to be able to handle things without relying too much on any API services which has limit rates.
Thanks for providing feedback specifically from the perspective of Python.
As a first step, this is my theoretical idea, and it is intentionally simplified in the form of MVP. Hopefully if an MVP can be produced, it can be a starting point for people to develop a more complex app.
The MVP assumes that the user is not interested in long-term memory - the AI does not have to remember previous chat points (and for cases where we do need it to remember, we would need to append some of the previous chat content in the next prompt - but as I said, let’s simplify this and set that aside if it is troublesome).
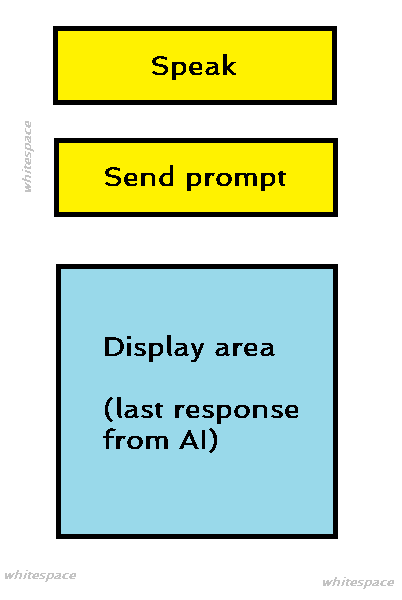
Here’s how the theoretical and simplified agent app’s UI would look like:
It has two (yellow) buttons, both of which are KNIME’s Refresh Widget:
Speak Button
It triggers the Python script. Let’s assume that we are using the Speech Recognition Library. It has its own in-built functions to automatically stop the recording by detecting ambience. So that means we only need the trigger button to start things out, eliminating the need to have a stop button. The Python script should produce a file containing the transcribed text from our microphone speaking session. For the sake of conversation, let’s name this file X. The second function of the trigger button is to extract current timestamp (eg. using the Create Date&Time Range Node, which will be used downstream.
Send Prompt Button
It triggers the sending of the prompt to the AI. First, it leverages on the Wait Node 's function of waiting for file X creation to finish. When X is available, its timestamp metadata is read by the File/Folders Meta Info Node and compared to the reference timestamp created earlier. If that indicates that the file is “new”, then only will the text be sent as prompt.
Do you think this is feasible? Theoretically, we can repeat our vocal interaction with the AI each time we click Speak, right?
I took some time to think this through - I’m afraid I cannot see how this can be implemented using the Python Extension Development API for various reasons - I’m still reasonably new to the API though don’t take this conclusion as final :-):
the node config dialogues are allow for static selection - it does not seem to allow let’s say “triggering” a recording that is then processed
An alternative thought was creating a node with a view - unfortunately these views seem to be intended for displaying data and not for interacting with other functionality like triggering recording a voice etc. I did play around with that at some point and tried to circumvent this by spinning up a local server and tried to embed a streamlit app, but for security reasons that is not possible.
I’m not sure whether this is any different if you look into Java Extension Development (looking at some Java based extension I have the feeling there are more possibilities…), but then again you need to implement this in Java :D.
Some other topics that can be challenging: Handling user input audio devices - both in a local setting and also when something like this is deployed in a hub setting…
After thinking this through I also thought:
Although this may not cater exactly for what you are after, but is a first starting point to leverage OS-built-in accessibility features?
I’ve been playing around e.g. with the Microsoft speech to text and that seems to be working really well
Just checking if we’re thinking of the same nodes. I was referring to the Python Script Node. Can’t it be connected to any suitable view nodes in Knime? If it can, I think the Refresh Button Widget (i.e. the button) should be working on that view node. My previous python projects was limited to using Python View Node, so I’m not familiar with the Python Script or other python nodes for that matter. I can only come up with theorization of what could be, so I could be wrong.
Basically, my idea was to generate the code using the Python Script Node (upstream) which should generate the text file when triggered by the refresh button on that view node (downstream). (The component’s display UI is the interaction point itself, as depicted in my image above).
If you have other ways, as long as the goal is achieved - to interact with AI agent using voice-to-text conversion tool, feel free to share the details.
I see - we were indeed thinking of two different ways.
I was already in the “Let’s build a dedicated node for that” mode using Python Extension Development…
If this is more like a component with some Python in it -it may actually work.
I’ve done a tutorial on conda env propagation where you could play Snake using a Python node so that definitely indicates that something else could work.
Only topic to note is that, if this works and it is used on e.g. Community Hub, I’m not sure if it will work with picking up a microphone - would have to be via browser I guess rather than direct from OS.
I’ll see if I can set up an env for this and to some testing once I find some time