Hello, we seem to be having issues with knime python API. Some of the downstream nodes convert the pyarrow.StringScalar types to knime._arrow._types.KnimeExtensionScalar and there’s no obvious way in fetching the underlying value because calling .as_py() on it will throw the following:
NotImplementedError:
Since PyArrow 8, accessing values that are dictionary encoded by KNIME is no longer supported.
Please use PyArrow 7 or refrain from accessing values in this column.
This means we can’t do any processing on the following type in the python extension itself. We’re using as to_pyarrow() API and then do the calculations, I have also tried tried using to_pandas() API for converting the type, however, it just spits out
Hello @ratchet ,
Could you please let us know which version of the KNIME Analytics platform you are using? Also, which version of PyArrow are you using?
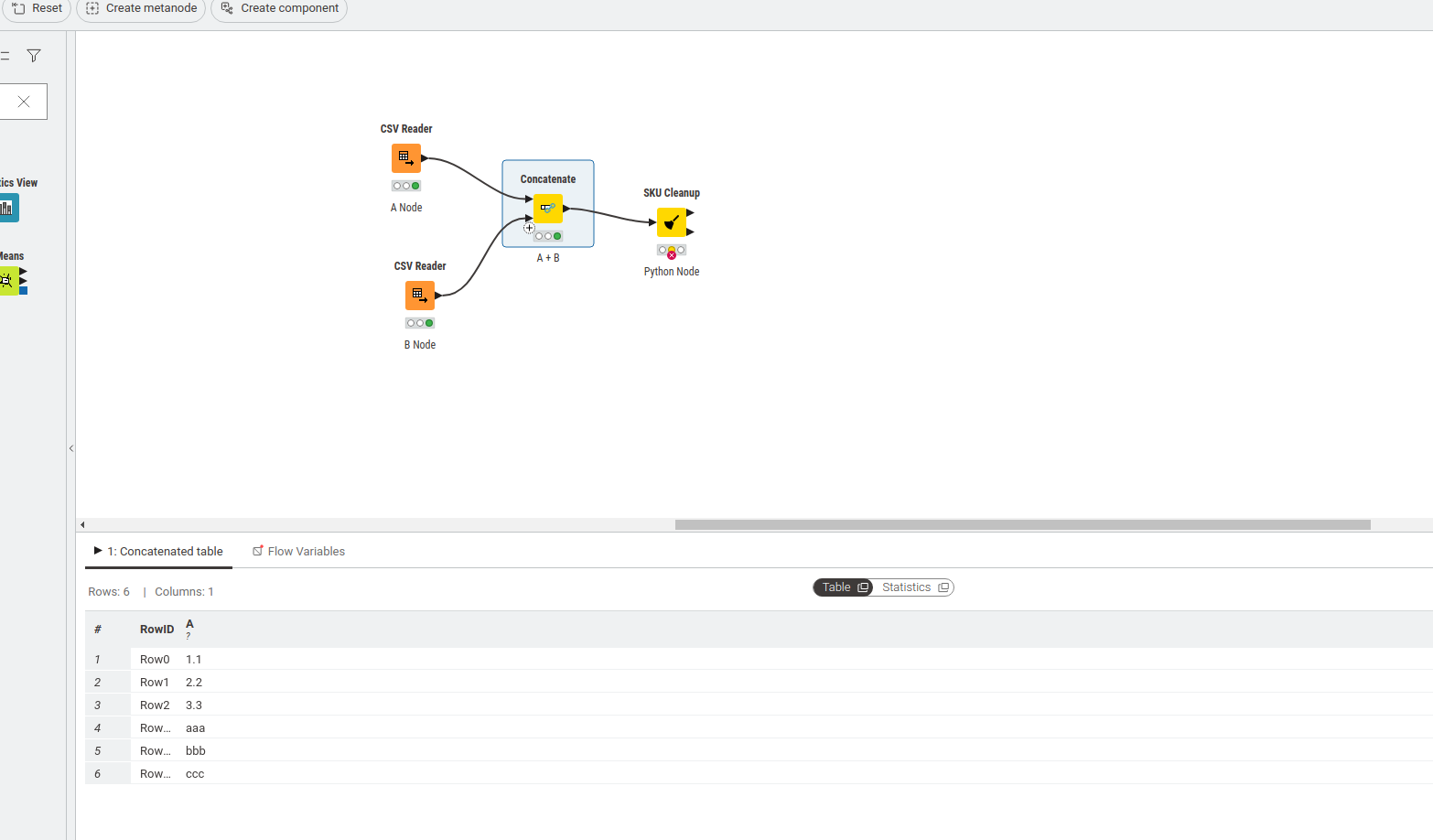
It happens when you concatenate string and number columns with Concatenate widget and then try to fetch the data with the python API. Because I cannot upload the custom extension here’s the how to replicate it.
A node num.csv
A
1.1
2.2
3.3
B Node str.csv
A
aaa
bbb
ccc
Concatenate[A node + B node] → Python node
Python snippet
def from_knime(table: kt.Table) :
for batch in table.to_batches():
pa_table = batch.to_pyarrow()
for name in table.column_names:
field_data = pa_table[name]
data = [v.as_py() for v in field_data]
Hi @ratchet,
Thank you for the further investigation. Your example demonstrates the issue very well. KNIME tables support columns with a generic DataValue type. However, many nodes do not support these columns because they don’t know which type of content they can expect.
Because of technical reasons (let me know if you are interested) the de-serialization of these columns is not available for Python-based nodes. Therefore, you only get a struct of the raw byte data and the type of the cell when accessing the values in Python.
For Python-based nodes, it is possible to limit the column types for a ColumnParameter with the column_filter parameter to make sure that the column has the expected type. Then the user is forced to use a node like the Column Auto Type Cast – KNIME Community Hub to use a column if it had mixed types.
That doesn’t really work as a solution because one of the things that the specific node does is “fix” the issue with these mixed columns. Is there a way to deserialize into pythonic representation in the API itself? I mean it’s already serialized and the datatype is known I don’t see why this can’t happen other than serialization from within python would probably be slower as it would need to be done on cell by cell basis.
Hi @ratchet,
It can be done. It would require the implementation of the deserialization code in Python for each data cell type (there are a lot and they are extensible by extensions). I created a ticket in our issue tracking system (AP-22703) but I cannot promise a timeline.