Hi Everyone,
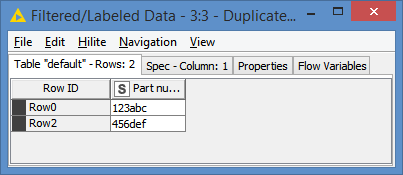
I have an issue. When I am trying to remove duplicate string data using duplicate row filter node, it cannot delete all the duplicate data. After transferring the data to excel file (using Excel sheet appender), i can remove duplicate data using excel built in function “Remove Duplicates”. How can I resolve this issue?
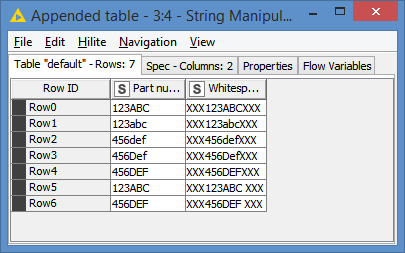
I think I found the issue. Excel 365 can understand “Case Sensitive” and consider as duplicate value. But knime considers both row as unique. Can you suggest anything how to resolve this issue?
Hi @emshihab , convert them to lower case, and then remove duplication.
If you want to keep the original data as is, you can convert to lowercase into a new column, and then apply duplication filter on that new column, and then remove that new column after the operation