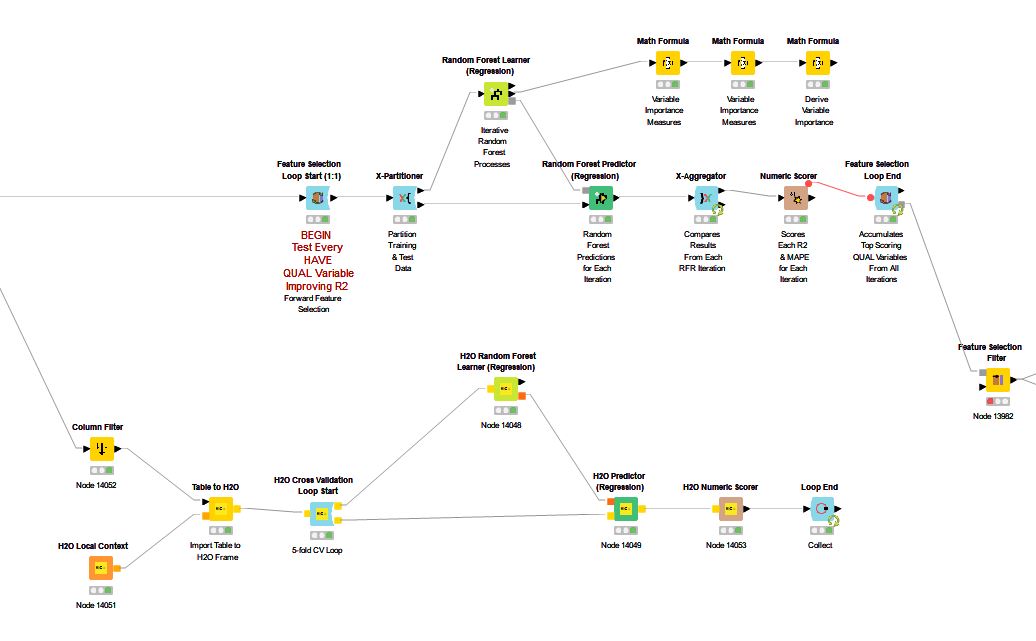
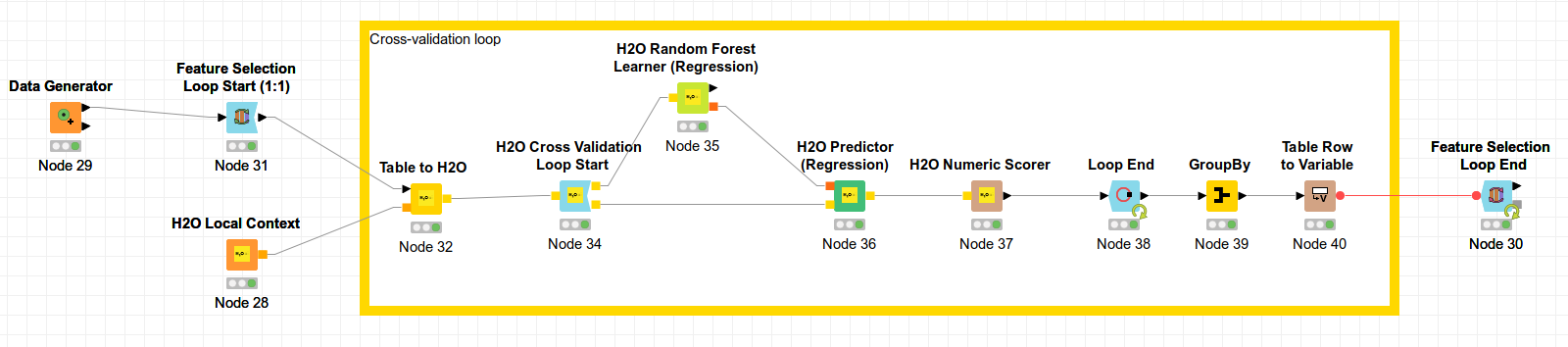
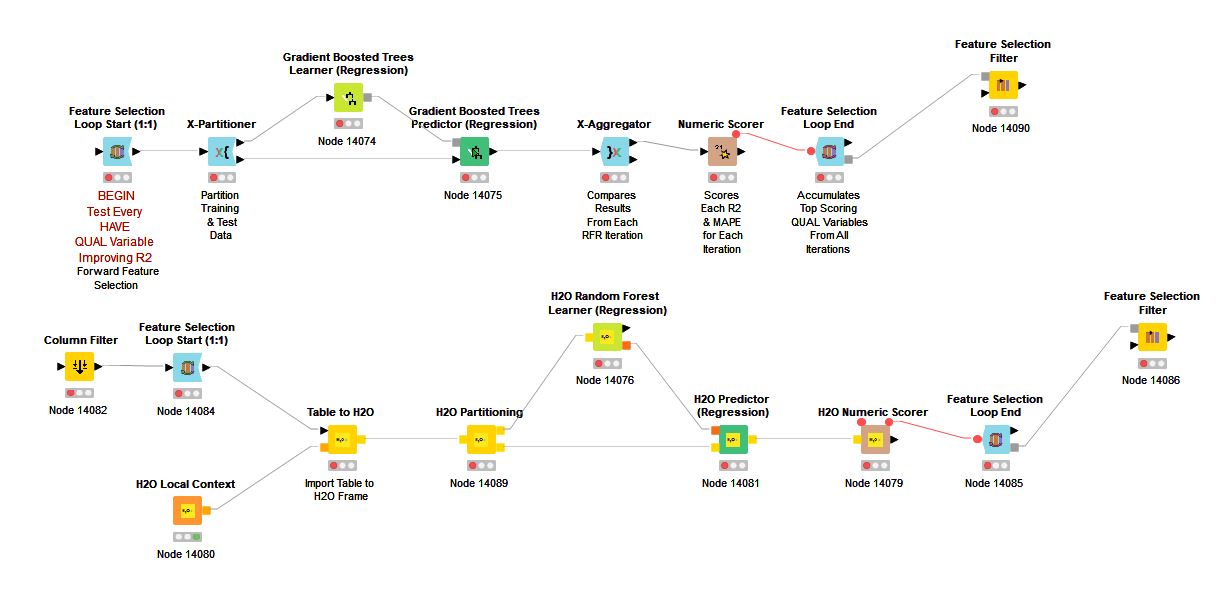
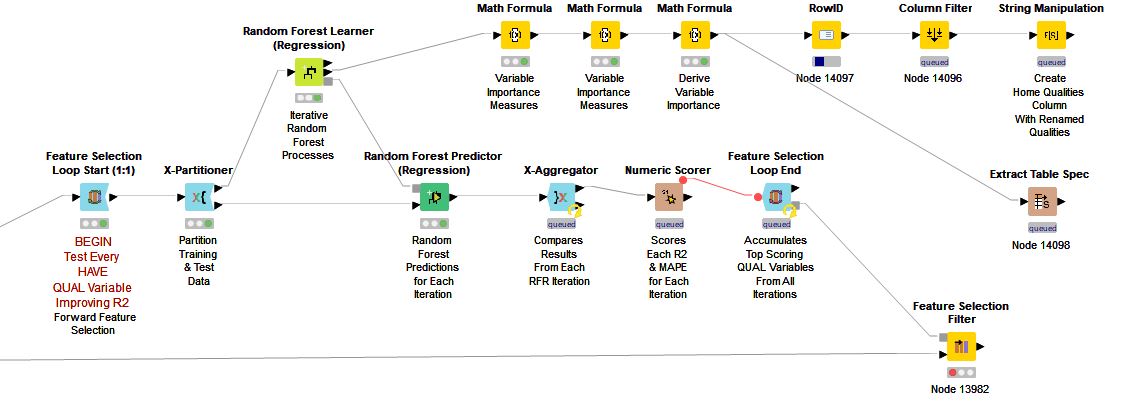
I am comparing KNIME Random Forest and H2O Random Forest variable importance results after running a series of 104 variables through loops. (Prior I completed several variable reduction tactics to bring the variables from 200+ to the reduced 104.)
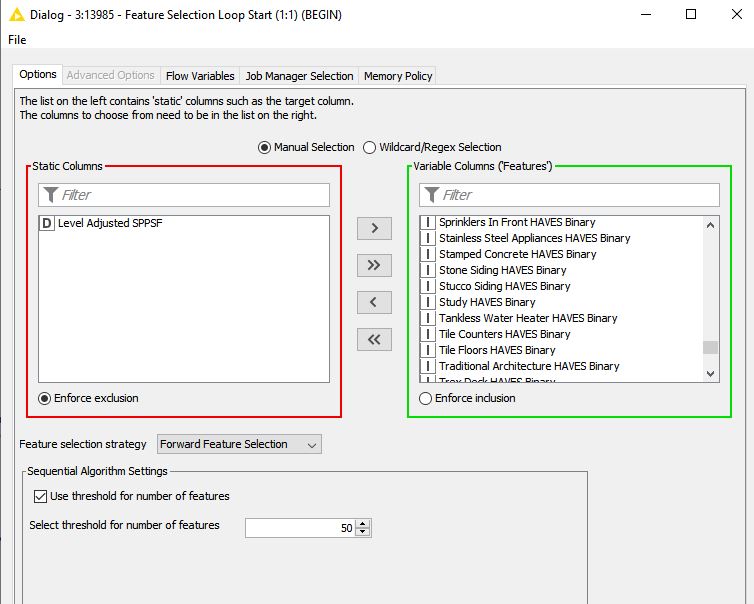
The KNIME Feature Selection Loop Start node allows me to designate to stop at the top 50 scoring variables from the 104 in the reduced table. However, I see no way to set this up in the H2O Cross Validation Loop Start–so it scores all 104 variables–thus making the side-by-side comparison of each variable’s results from the two processes very inaccurate.
How can I set up the H2O Loop to stop with the top fifty scoring variables instead of using the full 104 available which “waters down” each variable’s importance score?
I don’t think this is possible right now, since the H2O Random Forest Learner is set up to output importance for all variables, and I don’t believe there is a way to change this in the node settings. (At any rate, it’s not something you adjust through the H2O Cross Validation Loop Start node.)
I’m happy to be corrected on this point if someone has a workaround. I will also ping @SimonS here to see if he has any suggestion.
@ScottF Okay, thanks. I will see what others may think also. Sure it makes sense to score all variables, and I could either run the top 50 back through a second time–but maybe that messes with the accuracy. Similarly, I could “standardize” the top 50 after removing the scores of the lower 54, but maybe that invalidates the true analysis?
You are comparing two different things here. Cross-validation is not meant for feature selection. The counterpart to the H2O Cross Validation loop nodes are the X-Partitioner and X-Aggregator nodes. There are no feature selection loop nodes specific to H2O but you can simply use the Feature Selection Loop Start and End nodes and put them around the H2O cross-validation loop (similar as you did in the upper workflow).
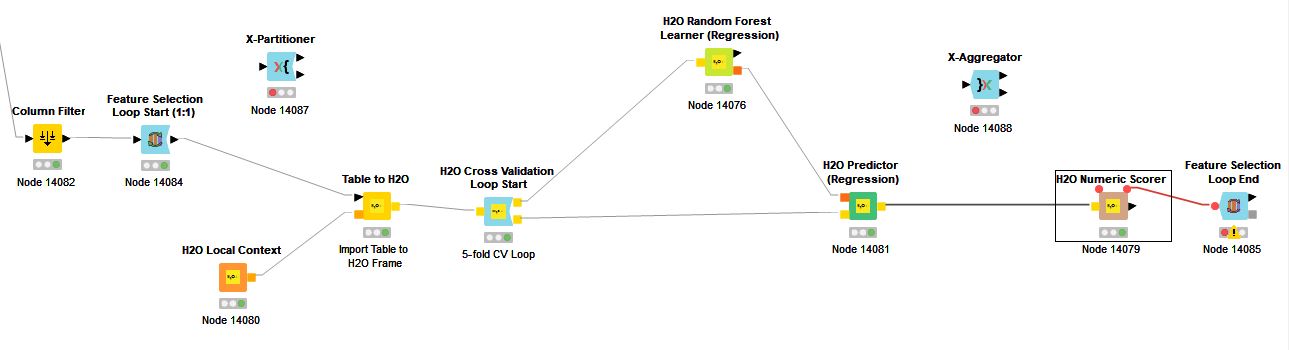
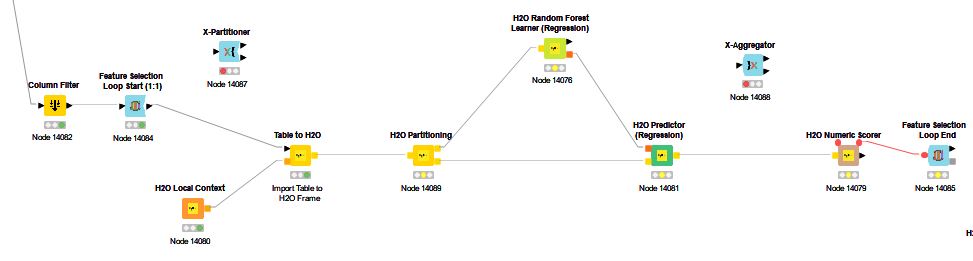
@SimonS Sorry, but I can’t figure out how to interconnect the KNIME nodes and the H2O nodes. I’ve tried a couple of different flows but the Feature Selection Loop End node always has the same error message “corresponding feature selection loop start node is missing”.
Please see below and tell me where to correct this. thanks
Actually, there must be something wrong with the flow directly above. It executed in 1/100 the time of the RFR flow and the results are just not correct from a practitioner’s perspective.
@Daniel_Weikert, Hi Daniel, I’m not a data scientist…I just play one in the real estate industry
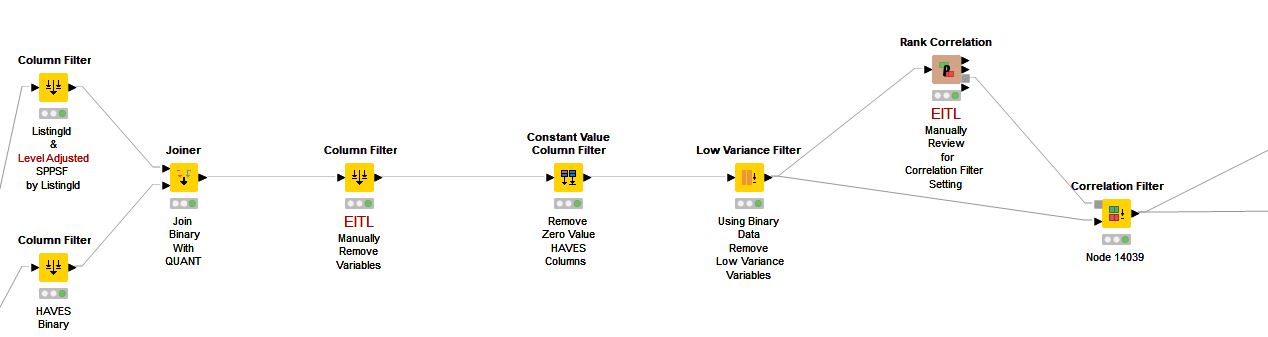
My variable reduction system is primitive with a fair amount of manual evaluation involved. My data set begins with 210-260 potential variables from my custom library. Then I manually remove a couple dozen that are just stupid from bad input from unskilled realtors. I then dump any columns with all zeros (at this point I am using binary analysis data). Next I remove Low Variance variables. Next I review Correlation. At this step I may go back to step one and manually remove a variable based on common sense so the Correlation Filter doesn’t remove the one of two I believe to be more important. I also get a solid feel on where to set the Correlation Filter based on the Correlation Matrix. I tried some of the more automated and sophisticated variable reduction nodes but there is a lot of correlation in real estate and I don’t want fully automated systems pulling stuff I believe the market places more value on.
I tried the Backward, Forward, and Random Strategies within the Feature Selection node. Random gave me pretty ugly output that I don’t believe. I wanted to also compare the Genetic Algorithm, but was doing something wrong with failures to complete the loop…
To begin placing market-based values on the individual variables I tried several different Feature Selection Loops and spent much time manually comparing all of the results. At this time I am down to three: 1) KNIME Random Forest Regression, 2) H2O Random Forest Regression, and 3) KNIME Gradient Boosted Trees.
After painful evaluation I am right now running with the KNIME Random Forest Regression. From a practitioner’s perspective the overall importance scoring feels more in line with market values.
Thanks a lot for sharing, highly appreciated. And don’t call yourself an idiot
Starting to select with domain knowledge is certainly beneficial.
So what is your RMSE (or other measure you are tracking?) Reasonable?
br
@Daniel_Weikert I am in the process of reconstructing nine of the same analyses (each about 1,000% bigger than the tiny step you saw here) just for one city. My discoveries above convinced me to rebuild this portion of the much bigger system.
Prior to the rebuild (may take a full week or more) my MAPE was running 4% to 4.8% with an 88% to 93% R-Squared on the nine sub analyses. Which is actually pretty phenomenal for valuing real estate.
But please keep in mind, the whole system is very large and complex; you saw just a tiny, tiny portion. I’ve tried some crazy stuff that I am sure nobody else has thought of–that I am amazed even sometimes work.
The funny thing is zillow’s latest valuation system is using thousands of data points. Mine is getting these results using four data points. Now, my four data points are synthesized from massive analyses creating each–but in the end there’s only four. take care.
@smithcreed you could try automated feature engineering at some point like with R vtreat. The example used actually is from a house price Kaggle challenge.
The result with such metrics sounds indeed pretty good. With the size comment, are you referring on the data and how you retrieve it? Maybe I misunderstood that.
br and enjoy your weekend
The size comment is regarding the small algorithm discussed at the beginning of this post relative to my whole series of analyses to derive the end results. take care
Well “80% of the time of a datascientist is spent getting the data” (General statement)
Applying the algorithm is only the cherry of the pie. Kudos to your work
take care