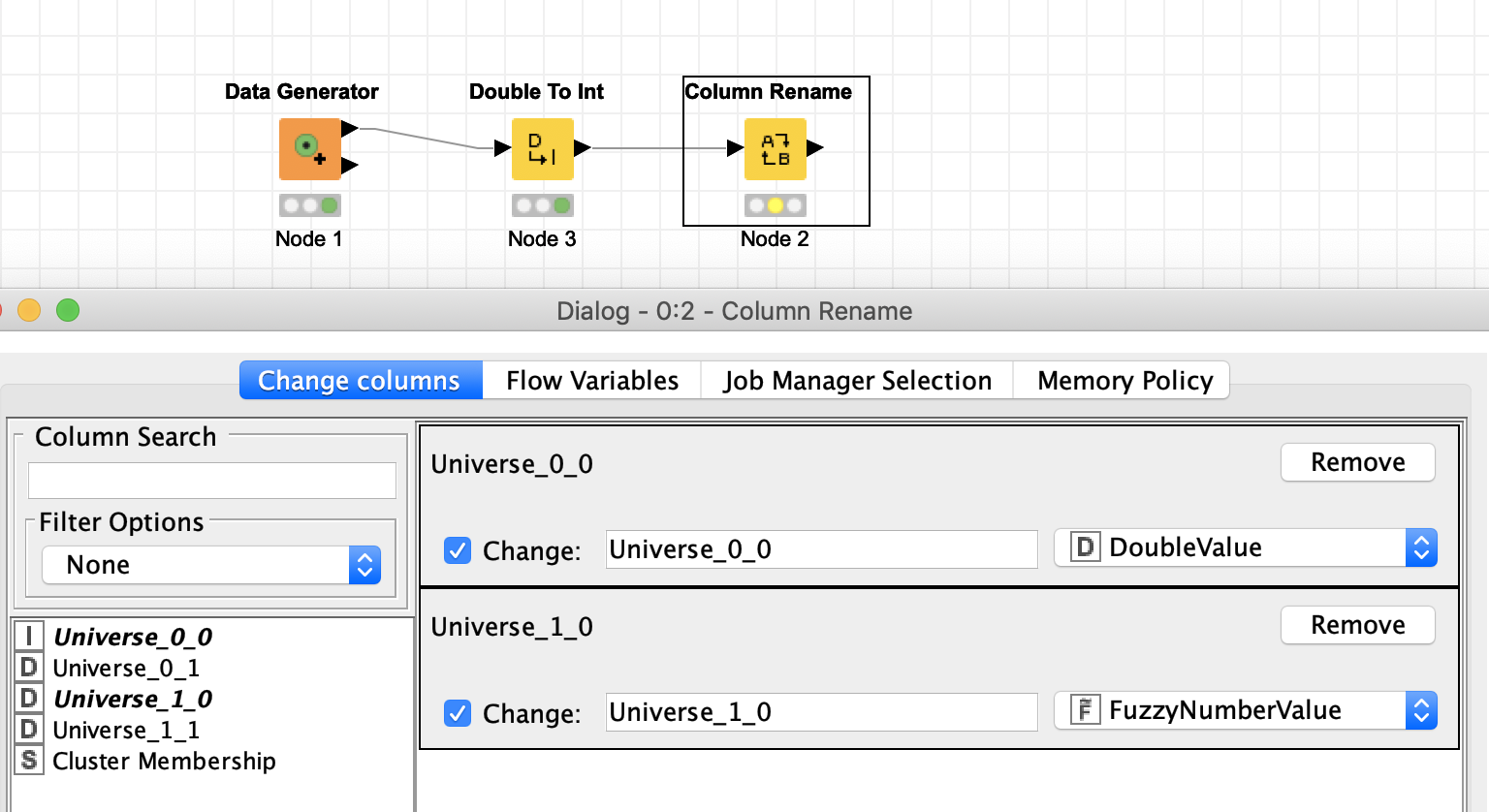
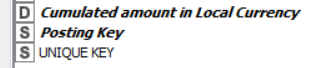My main KNIME workflow is installed on the laptops of 15 different people. When users came to use the workflow on the 7th January, the workflow did not function as expected as the parameters of some nodes had been changed (on every users individual version of the workflow).
The issue was also experienced in a previous version of the workflow that had been stored outside of KNIME since mid-December. This change was only experienced in 1 of my 5 workflows - even though the same Meta-node is included in all 5.
I did not change the workflow and the users have confirmed that they have not done so either (although I can’t see how it would be an issue for all users if 1 person changed theirs). I managed to fix it by going through each and every node individually and checking the parameters we as expected but this was extremely time consuming. However, I did diagnose the issues as:
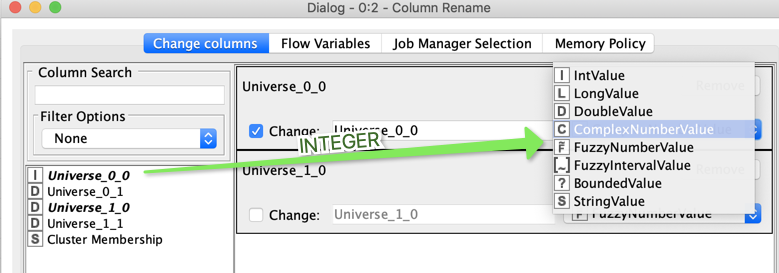
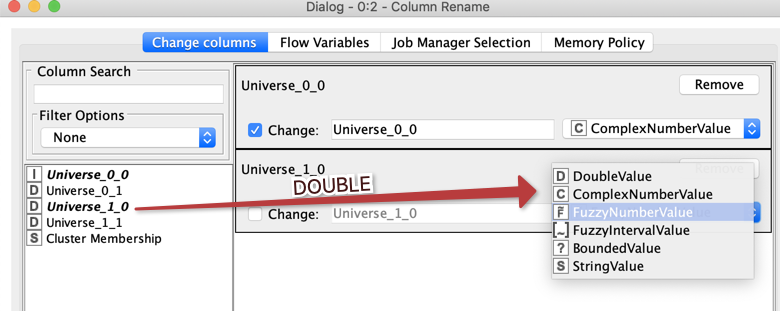
e.g. A node that was renaming a column and setting the header type as Double was changed to setting the header type as Fuzzy Number.
A column filter node that was designed to select 2 fields out of 12 was changed to include all fields.
The fact that these parameters were changed unexpectedly meant that my workflow didn’t function as expected.
Has anyone encountered a similar issue before? I am trying to find the root cause in an attempt to prevent it happening again.
Can you share a bit more information to try to get to the root cause? What KNIME version and OS are you using? Have you done any updates in between?
Regarding workflow I guess you import some data? Is data consistent - column names and data types? Regarding Column Rename node what was the type of data before? Regarding Column Filter node do you use enforce inclusion option?
All users are running Windows 10 Enterprise and our KNIME version is 3.6.1.
As far as I am aware, a couple of users may have done updates but the workflow is saved on their individual computer (as it is with everyone), so I would have assumed that one user updating their KNIME wouldn’t affect all of us. As I noted in my original email, a version of the workflow that was saved in my email (not in KNIME), corrupted in the same place as soon as I opened it in KNIME.
The workflow imports, formats, updates and manipulates data from multiple Excel files. All of the data is consistent including Header names and data types.
Re: the column rename, the data type was originally double and after the rename is also double - I was merely changing the name of the header to add the text ‘prior’ (same for all other 10 columns, none of which corrupted).
I didn’t have Enforce Inclusion option ticked - I have done this now, thanks! - but the original data had not been changed so not sure how that would have helped.
My main concern is that I can’t explain this corruption that was experienced on 15 different computers - and only in 1 of many workflows (all of which have the same metanode).
Have you ever encountered something like this before? I would have thought that even if one person had changed the workflow on their machine, this change would only be for that user only?
I have never personally experienced something like it. For sure if update is made by someone it should not affect everybody. If someone changed workflow on their machine it should not affect others as well. This seems like a workflow related thing so that is the reason why everybody experienced the same thing.
Is there a possibility for you to share a workflow to investigate further? Or a KNIME log file?
I guess one possibility is that a node has been updated in such a way as to change the column it returns from a double to a fuzzy number, and that update has been applied across all the machines (a node implementation, rather than a setting in one of the nodes), although again that would require all copies of KNIME to have been updated, and a node to have been updated in a way that is technically contrary to the noding guidelines, which seems a bit unlikely in both cases.
The alternative source of error then is a node which guesses a column type based on the input data, e.g. an excel reader or file reader of some sort, for which the input data has subtly changed - in which case, your problem may well be actually somewhere upstream of your failing metanode, but only manifesting itself there.
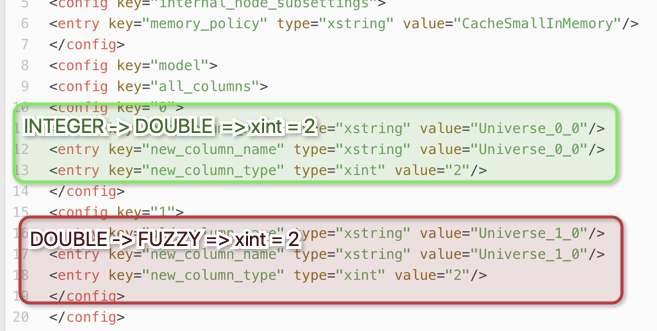
OK I have a theory of what is going on with the rename node and the changed column types. It seems the rename node stores the information of which type it should assign to a column based on the originating type of the column in question. An integer would have other possibilities to be turned into than a Double.
What could happen now if suddenly instead of an Integer a Double variable comes along? The settings might well turn into Fuzzy.
So the logic of stored transformations does not seem to be one list like 0 = Integer, 1 = Long, 2 = Double but the order seems to be dependent on the source of the variable. Not sure if this is a bug or a feature but one more reason not to convert variables using rename. We experienced some funny (or not so funny) things with it.
Thanks very much for your reply - much appreciated. I will continue to investigate with your input in mind - it does seem to make sense but I will need to follow it through. Thanks again.
Hi,
The node where I encountered an issue is set up as below:
It is a Column Rename with multiple columns selected to be changed.
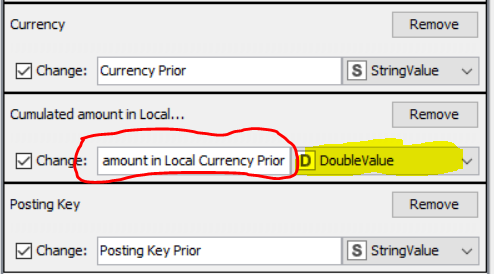
These columns were all keeping their Column Type (e.g. Double) but I was having to change the name of each column - in all cases adding the word ‘Prior’ at the end of the existing column header name as outline in red below.
The section highlighted in Yellow is the one that was changed from being a double value to fuzzy number value. All of the other columns remained unchanged (and interestingly, to go along with your theory, this is the only column type-casted as a double).
Can I as you to please explain further what driver would have been for this being changed form a double to an Fuzzy number?
Do you know what the boundaries are for a Double number in KNIME (versus being type-cast as a Fuzzy Number value)?
Thanks in advance for your assistance - it has been really helpful.
Following my theory the problem you described could appear under the following condition:
the time before you had the problem when you (and other people used the workflow) the Local currency amount came in as an Integer
it was converted to a double which lead to the XML=2 (if integer, convert to double)
next time the Local currency comes in as a Double (which it maybe was in the first place), but the system does not recognise it has the XML=2 from the previous integer conversion an now assumes. I have a double and XML=2 does mean do a fuzzy
That would be one theory, for example if you only had very few entries and they happen to have local currency amounts that would not have any numbers after a decimal separator (if one existed in the first place).
It is also possible that when KNIME tries to check the integrity of the whole workflow it always tries to take into account the real data it has to produce a lot of yellow traffic light saying: check complete the node might run. It could be that in this process it tries to adapt certain settings to what would be possible - although I have non insight into the inner workings of KNIME.
Question is if it may be best not to use the rename node to change the data type. Or maybe there is a problem you could reproduce; in that case you should contact the KIME support or post it here in the forum.
It is definitely not recommended, as doing this can cause some strange problems. It is best to always use a node dedicated to type changing instead (e.g. String to number).
Hi, Thanks for the advice. In this particular instance I wasn’t using the node to change the data type, I was using it to change the header text only e.g. Amount in Local Currency to Amount in Local Currency Prior - before and after the data type was a double.
Do you know if there is a node for changing header name/renaming without the risk of the the data type being included (i.e. something other than a column rename?
I’m still not sure what happen to your workflow but Column Rename node is for headers renaming and data type should not change just like that. Other possibility is to use Insert Column Header node.
One more question: does all the 5 workflow that use this Metanode use t he same data as well?
The Column Rename (Regex) might help you as this does nothing other than check each column name for a regular expression match and change the name of any column(s) matching.