OK I have a theory of what is going on with the rename node and the changed column types. It seems the rename node stores the information of which type it should assign to a column based on the originating type of the column in question. An integer would have other possibilities to be turned into than a Double.
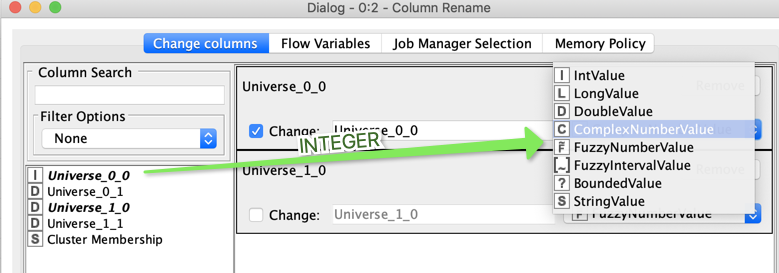
The corresponding numbers are now stored in an XML file “settings.xml”
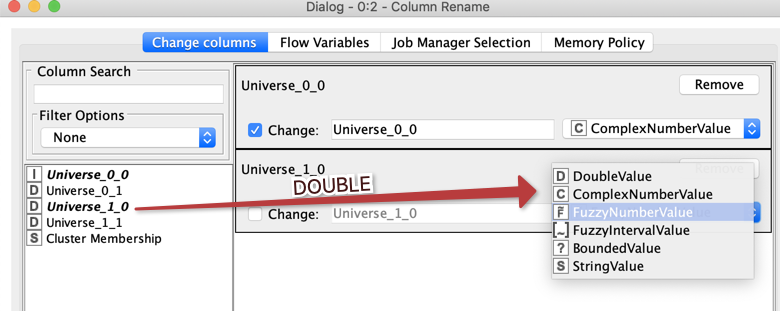
If I would now rename the integer into double and the Double into Fuzzy like this
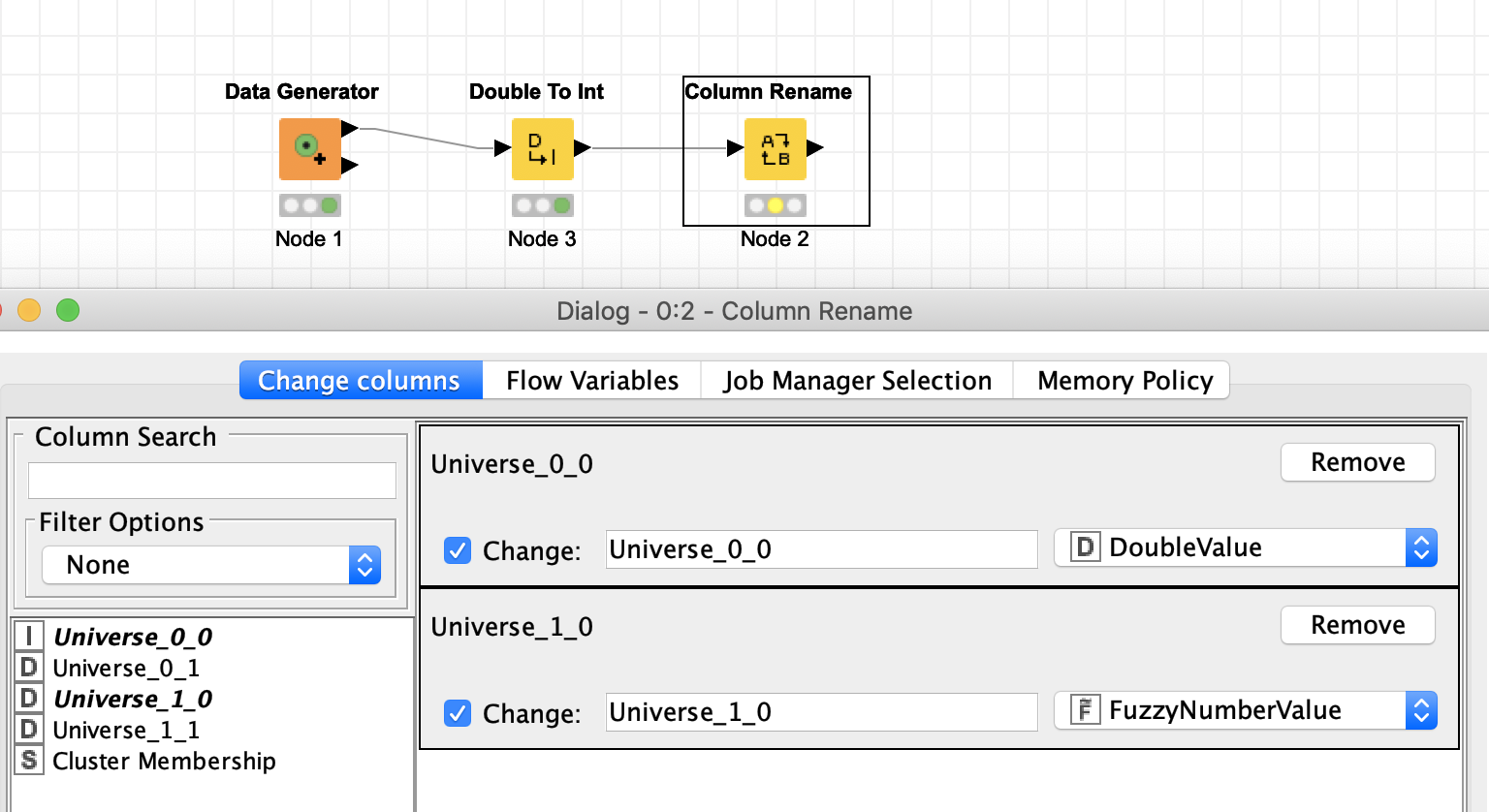
The corresponding XML file looks like this:
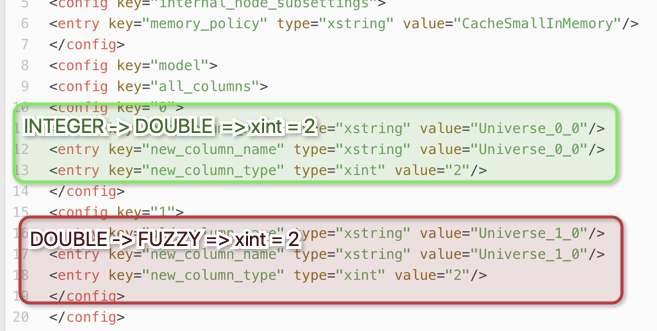
What could happen now if suddenly instead of an Integer a Double variable comes along? The settings might well turn into Fuzzy.
So the logic of stored transformations does not seem to be one list like 0 = Integer, 1 = Long, 2 = Double but the order seems to be dependent on the source of the variable. Not sure if this is a bug or a feature but one more reason not to convert variables using rename. We experienced some funny (or not so funny) things with it.
kn_problem_corrupting_workflow.knwf (180.0 KB)