Do we know if KNIME can be used in HDP (Hortonworks Data Platform), actually I referred link “KNIME Server Installation Guide”. I’ve successfully installed KNIME in Linux server of HDP, but when I tried to use " http://server:8080/knime/", it was not opening.
Please let me know what extra I have to do for that.
KNIME Analytics Platform is open source software that is used to develop data science solutions locally on a machine.
KNIME Server is a commercial enterprise software for team-based collaboration, automation, management, and deployment of data science workflows as analytical applications and services.
The link that you shared guides through installation of the latter, but you would need an active license for it. Is that what you are interested to install and make use of?
If so, then you would need to first start the KNIME Server (it automatically start upon installation, but if you reboot of shut down the application you would need to do it again). And then you should be able to access the WebPortal of the Server by accessing http://localhost:8080 if you run browser of the same machine or http://<ip_address_of_KNIME_Server_machine>:8080 if you access it from another machine. Note, that in order for this to work the port 8080 should not be taken/blocked by HDP.
Sorry, I should have been clarified in my post. Actually I was trying to use HDP (3.0) hadoop/Spark/Hive with KNIME. Currently I am using KNIME Analytics Platform.
Could you please let me know if this is possible.
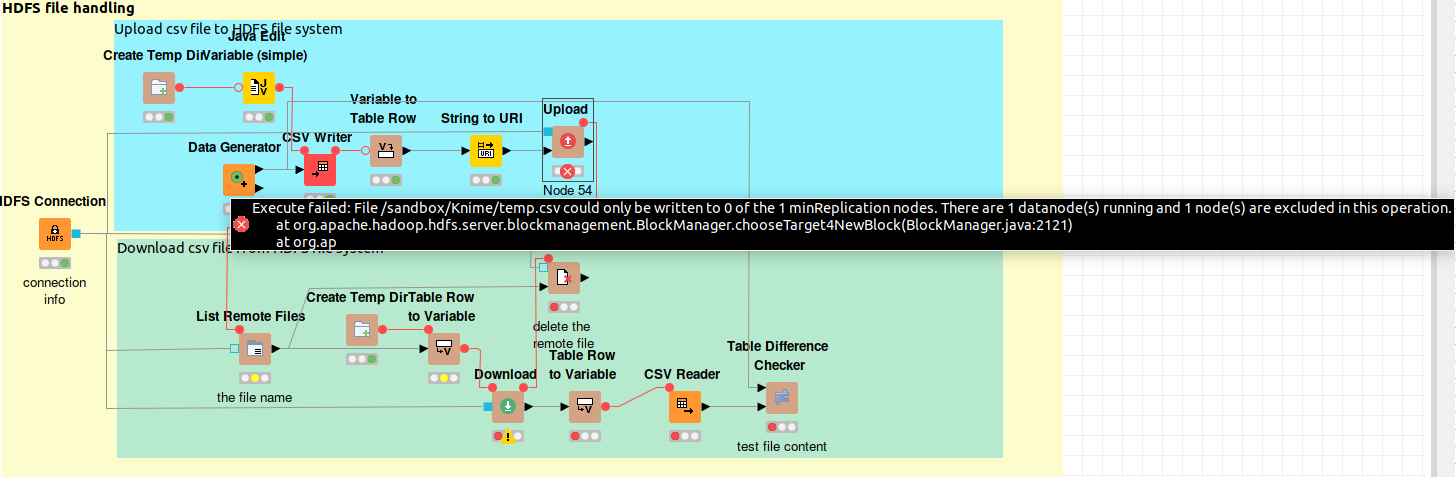
getting below issue while loading file from KNIME to HDP3.0
so what you are trying to do is to communicate with big data infrastructure from inside of KNIME. This is supported. So there should be some issue with the way things are configured. Could you please send us the knime.log? It would be useful for both issues that you have reported.
Please note, that what you describe in the second post does not relate to KNIME Server (unless you try to execute in on KNIME Server) and therefore the server installation page and WebPortal that you mentioned in the first post are not relevant.
Hey @shashank26s,
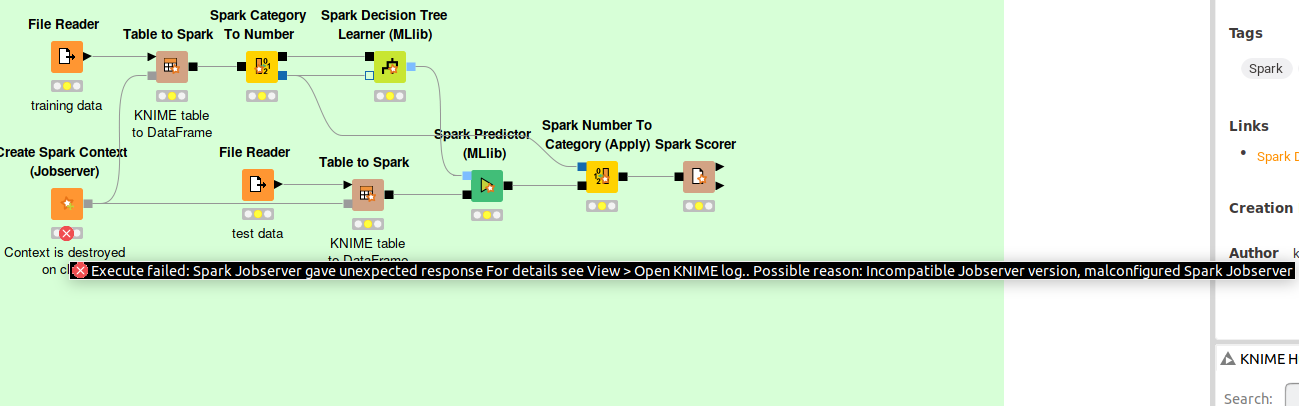
I see in your Workflow that you are trying to using Spark JobServer. We do not recommend that, with HDP3.0 I recommend to use Livy and the Create Spark Context (Livy) node. HDP already includes compatible versions of Apache Livy.
Is there a reason you want to try Spark Jobserver?
For the upload issue: This is most likely a connectivity issue, I think you are not able to connect to the cluster worker nodes. I would recommend you to try the HTTPFS node instead of the HDFS node.