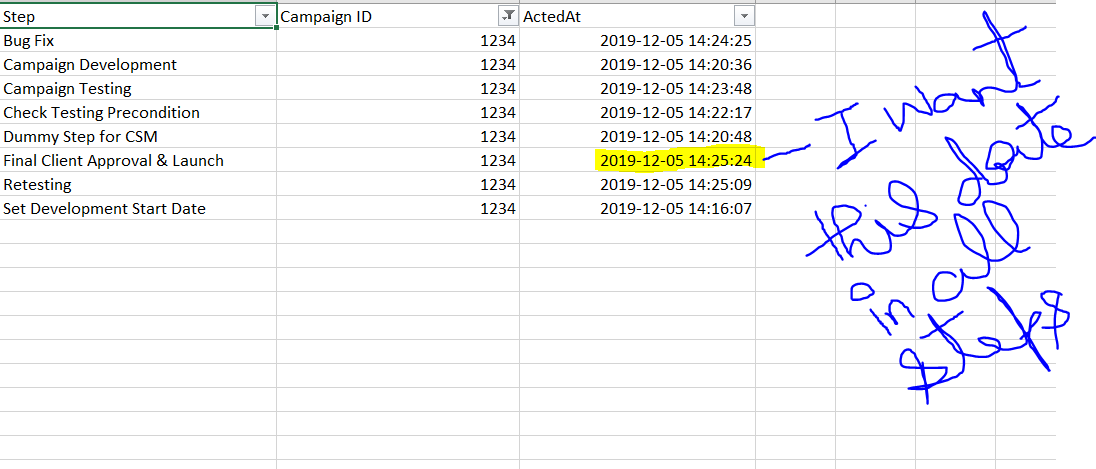
I would recommend using a group by node by CampaignID giving you the maximum “ActedAt” date and then use a joiner node to join this maximum dateTime back to your original data.
If you want to convert your date to a KNIME datetime there is a recent blog article dealing with data and time formats:
Hi @vishalpat13 , I’m in agreement with @mlauber71 in terms of the mechanics of how to pick up the max date and then apply that to each row.
I am however confused about where you said you want to “add three columns to the same file”. Your example appears to show 3 rows of 3 columns, so I don’t understand how are these are to be applied to the existing data, or maybe I’m misinterpreting what you have said.
What are you expecting your final output look like?
BR
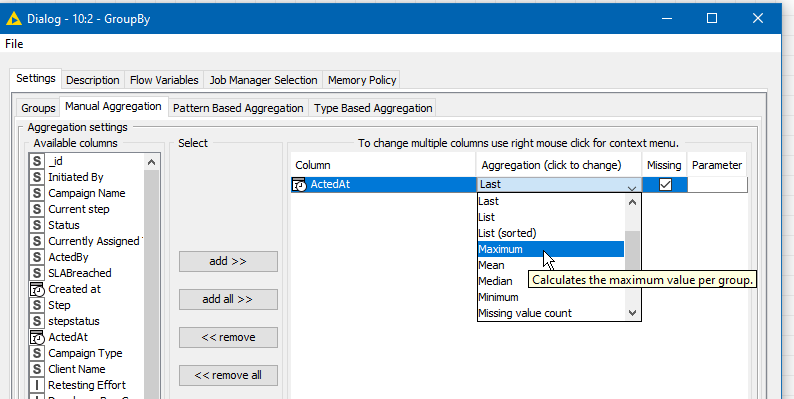
Hi @vishalpat13, there wasn’t any data included with your workflow, so I cannot run it (you need to run it and then uncheck the “reset workflow” button when you export it) but what you will need to do is only Group By the Campaign ID (and not the Step). You can then join the output back to the original on just Campaign ID.
Oh and the other thing is that in Manual Aggregation, you need to have the aggregation as Maximum. You currently have it as “Last” which is just the last one in the list
Hi @vishalpat13, I’ll take a look when I get a chance, although it might not be until next week, but hopefully somebody else will assist if you need something sooner!
I thought I’d just mention though that within the forum you can upload workflows and excel files directly using the upload button
which will save you having to use an external file transfer service.
Also, if you save your spreadsheet within the workflow’s folder structure (you can create a “data” subfolder in your file system beneath your workflow and copy the spreadsheet into it) then the spreadsheet will upload as part of the workflow, and with the newer file handling nodes such as Excel Reader you can easily reference this spreadsheet if stored in the data folder
This is particularly useful when sharing workflows on the forum.
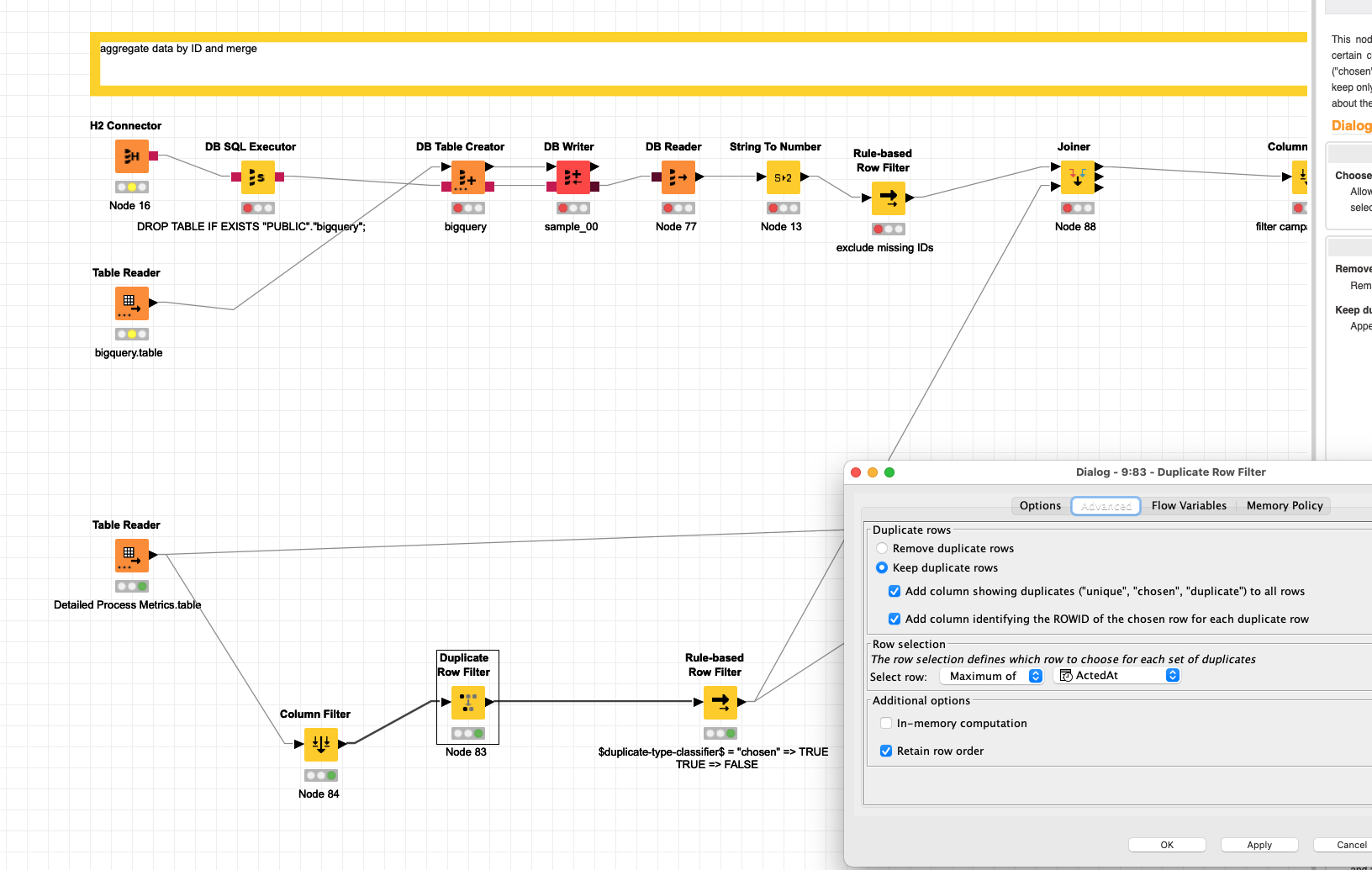
@vishalpat13 you might want to take a look at this example which contains all your data in a .table format and simulates your database using an H2 connection.
I still do not fully get what you want to do. If you want to select a maximum Acted Date by campaign ID I did that at the bottom using the Duplicate Row filter. Which also would take the campaign type and Acted BY from the same line (if this is what you want)
I would recommend you take a close look and decide what you want to do with your data and what implications that might have - especially regarding duplicates.
I’d assumed that you had what you needed but I will take a look later today (although it might be this evening UK time by the time I can take a look, as I have a few appointments today) and see if I can provide some additional assistance.
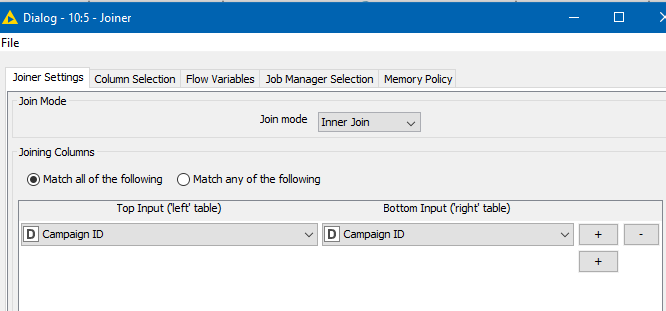
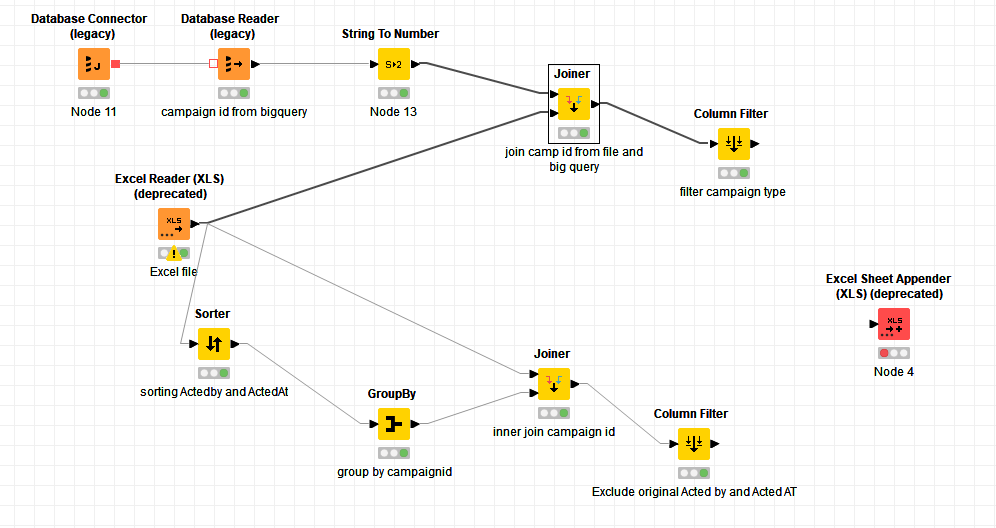
That’s currently an “inner join”, so the result of that join is it will simply return you the matches from your “Detailed Process Metrics.xlsx” spreadsheet which have Campaign IDs in common with the Big Query data set. As it stands, it does not add any additional data rows or columns. It simply has the potential to remove some rows
In the lower part of your flow, you get the Maximum ActedAt and Last ActedBy for each Campaign Id and join them back to your spreadsheet data set, so this is now spreadsheet data plus ActedAt and ActedBy columns. That much I understand.
But you say you want to then join Campaign Types onto the end using the information coming out of the Big query join? (top right of the flow). But the Campaign Types are already in your spreadsheet (that’s where they came from) , so what additional information other than ActedAt and ActedBy are your trying to append, and what is your actual intended purpose of the join with the Big Query data?
ok, so @takbb thank you for giving some time from your busy schedule to look at my problem. I know I am troubling you a lot, but the thing is this task will confirm my probation in my new job as data engineer.
so, as you know I have got acted at and acted by on lower part of workflow.
Now, I want to get campaign type for only those campaigns where campaign Id’s match in both bigquery as well as excel file.
Finally, I want to append all these three columns : actedAt, actedBy, Campaigntype to the same file at the end.
OK. Looking at your data, for a few of the Campaign ID there is both a populated Campaign Type and also a missing Campaign Type . For one Campaign ID there are two different Campaign Types . I had originally thought of just getting the distinct set of Campaign IDs and type values for those that match the big query and then using a Cell Replacer to act like an excel vlookup to populate them back into a new column in your spreadsheet. But with duplicates, that doesn’t work perfectly.
An alternative then is to first ensure there is a unique key on the spreadsheet (creating one with a counter generator if there isn’t) and then join back from the big query matches to the original sheet using that unique key. If you do this as a left outer join, with your spreadsheet connected to the left port of the joiner node, and collect only the Campaign Type column of the data from the big query part of the flow, then this should append Campaign Types only for the matching rows.
The end result is that for a given Campaign ID , there could be different Campaign Type , because that is what you have on the input data.
When I’m back at my pc later I’ll look at building this and uploading the flow.
You need to decide whether the Campaign Type that you want appended to the spreadsheet row will always be the Campaign Type that was already on that row, or if you somehow want missing ones replaced where the Campaign Type is known on a different row.
Also if Campaign Type is missing, do you still want an indicator that shows that the Campaign ID matches the Big query data, because as it stands a “missing” appended Campaign Type can mean either that the data didn’t match the big query or that the Campaign Type is simply missing and that the data did match.
One of the challenges you’ll face in a career of data engineering is both dealing with the requirements and finding the “edge” cases that the client either hasn’t defined or simply doesn’t realise exist. You can spend more time on defining behaviour for those edge cases than you do on actually building the main data flow, so it is important to analyse your data and check things like whether keys are actually unique, and the overall data quality.
@vishalpat13 I agree with @takbb who has done a great job pointing out the questions that come with you data.
I do not want to insist too much but I still think you might benefit from my article and sample workflows about duplicates and how to deal with them, since this is a very common problem in Data engineering (ETL) and you will have to make decisions - and best you do it deliberately and consciously.
The impulse stems from Big Data environments since duplicates are a constant worry there since no primary keys would hinder them and sometimes different systems just dump data into a data lake without further checks. So there might be some parallels to what you have with ‚unregulated‘ Excel files. For practical reasons if you want to use a window function with several conditions you could do that with a local H2 database that would just live in a single file on your computer.
Also it might become necessary that you ask the person responsible for the data for definitions and decisions. What to do if an ID does not match or several do match (do we throw them away or list them or have two entries). Sometimes they are not that eager to answer because that would force decisions regarding possibly complicated or lacking business processes and now it is the data engineer / data scientist that is supposed to fix that with some ‚magic‘ (… can‘t you do something with AI or DeepLearning or so ).
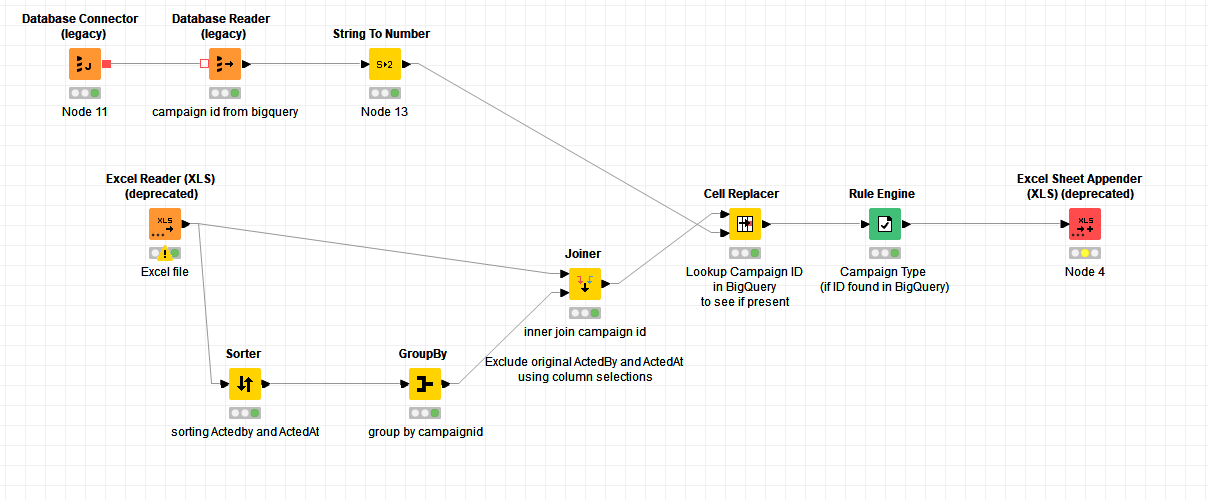
Hi @vishalpat13 , as you can see from above there are a number of questions about the data that need answering before an actual solution can be produced that is known to meet your requirements. However, in its most simple form, I think that this fulfils the need to return the Campaign Type for those that match the Big Query data. All it does is use Cell Replacer to provide a “lookup” to see if the Campaign ID is present in the Big Query data. It then uses a rule engine so that where the Cell Replacer returned a value, it transcribes the Campaign Type from the same row to a new column Big Query Campaign type.
Hi @vishalpat13 , that should be easily resolved if you edit the Joiner in the workflow I uploaded, and make that a Left Outer join instead of an inner join.