@vishalpat13 you might want to take a look at this example which contains all your data in a .table format and simulates your database using an H2 connection.
I still do not fully get what you want to do. If you want to select a maximum Acted Date by campaign ID I did that at the bottom using the Duplicate Row filter. Which also would take the campaign type and Acted BY from the same line (if this is what you want)
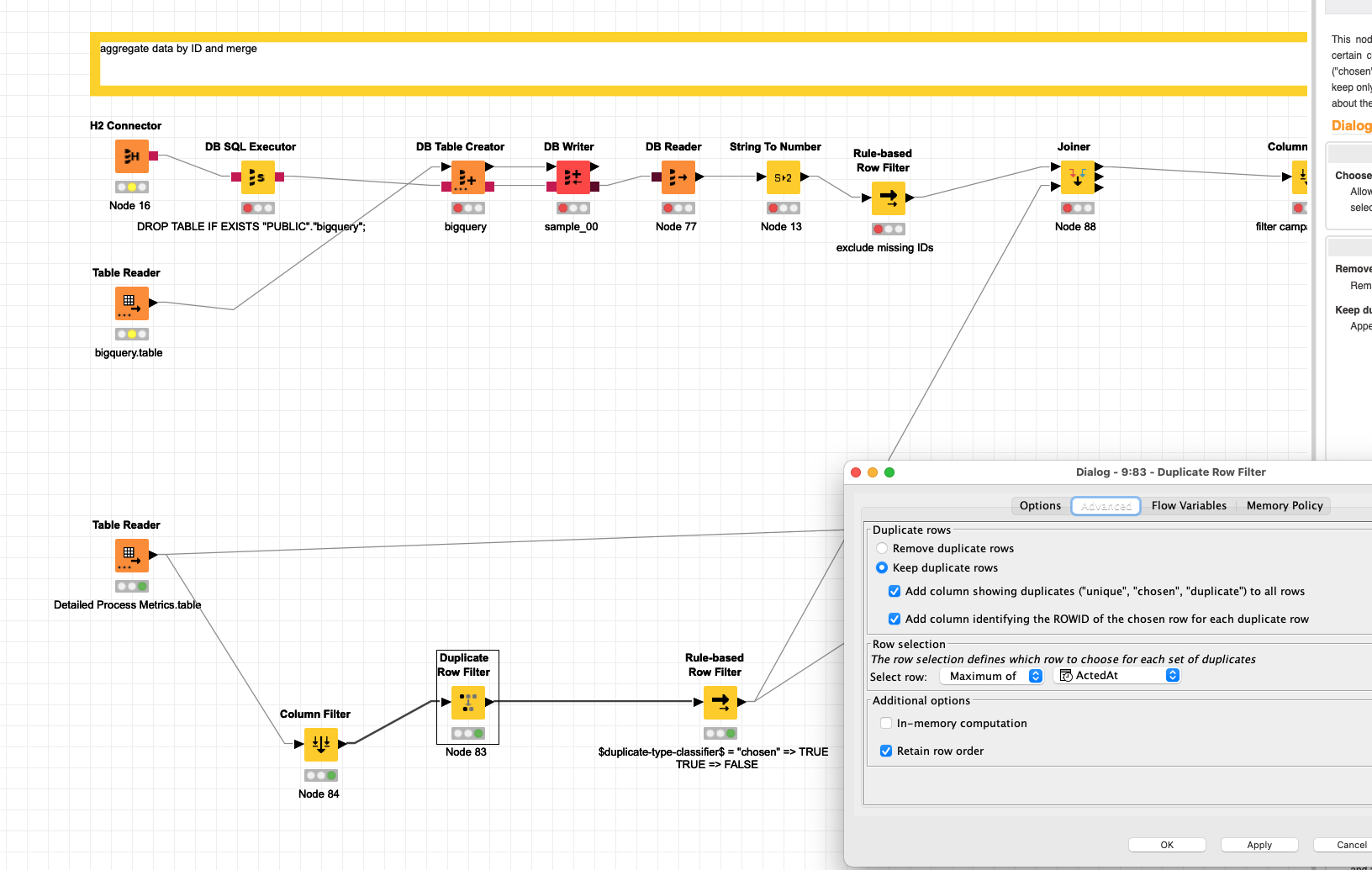
I would recommend you take a close look and decide what you want to do with your data and what implications that might have - especially regarding duplicates.