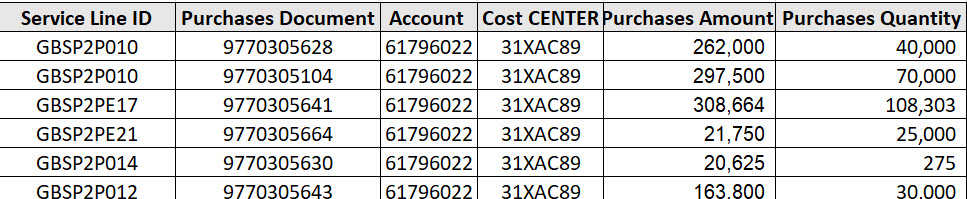
I have developed a workflow for a reconciliation process that needs to be improved. As data sources we have one file with two tabs the first PO template which contains PO’s number and the budgeted amount and second SAP download which are all the transactions recorded in each PO.
The intention is to reconcile the amount received by posting period for each PO number and also be able to see how much is left from the budgeted amount. Please see my current workflow:
The main question is there a way to optimize the workflow? Also I would like to see if the columns name in the en results only can should the number of the period as shown in the desired outcome.
Hi @Brown100,
Welcome to the KNIME Forum! Great job on the workflow! I think you can simplify it a little bit: you are using a Group Loop Start and a Loop End node, creating one iteration for each unique value in your “Purchases Document” column. Then inside the loop, you are grouping and pivoting based on the same column. You can simply leave out the loop and let the GroupBy and Pivoting nodes do the aggregations on the full data. Then, instead of a Column Appender, you can connect the two tables using a Joiner node and joining by the “Purchases Document” column. It should yield the same results and you get rid of the loop.
To change the column names in the end, you can either use a Column Rename or Table Manipulator node, or you use the Column Rename (Regex) node so you do not have to manually change every column name. The regex should be something like ([0-9]+)\+.* and the replacement should be $1 so it references the part of your regex match that is in the parentheses (i.e. the number). Using the Column Resorter node you can also bring the columns in order.
Kind regards,
Alexander
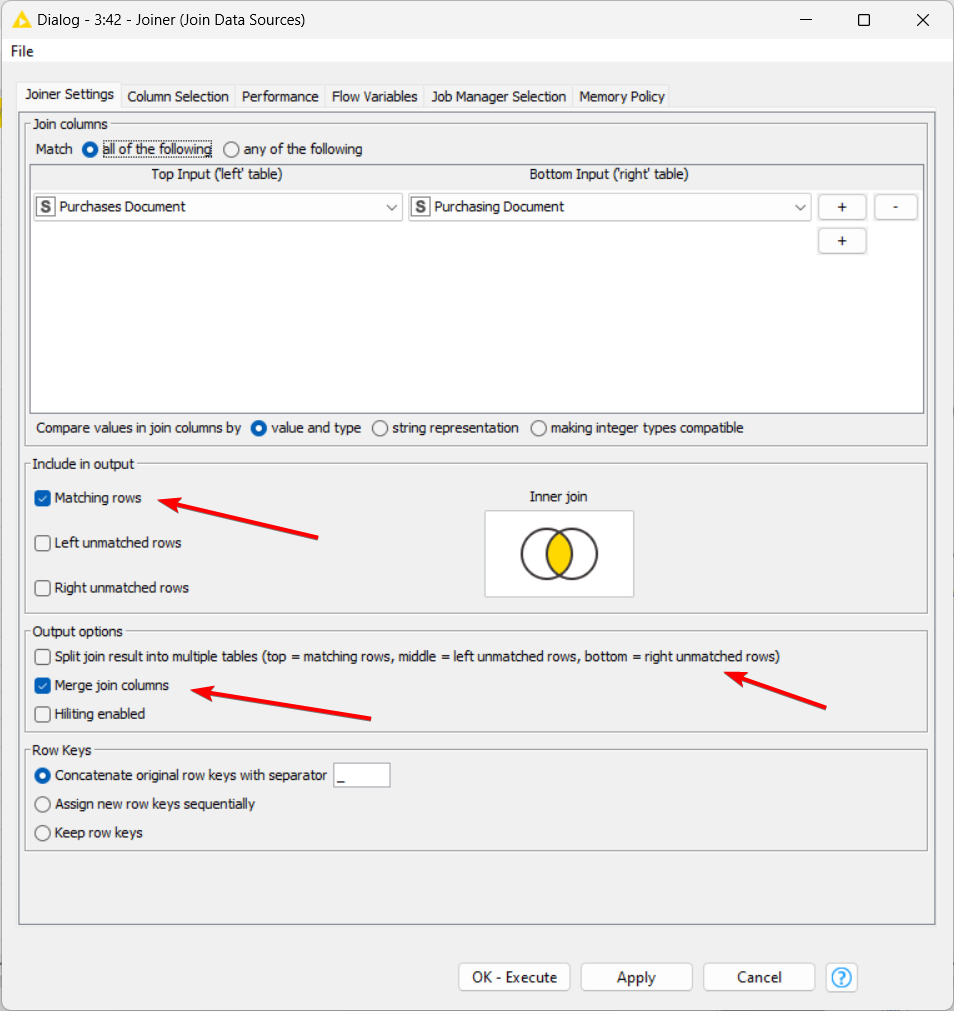
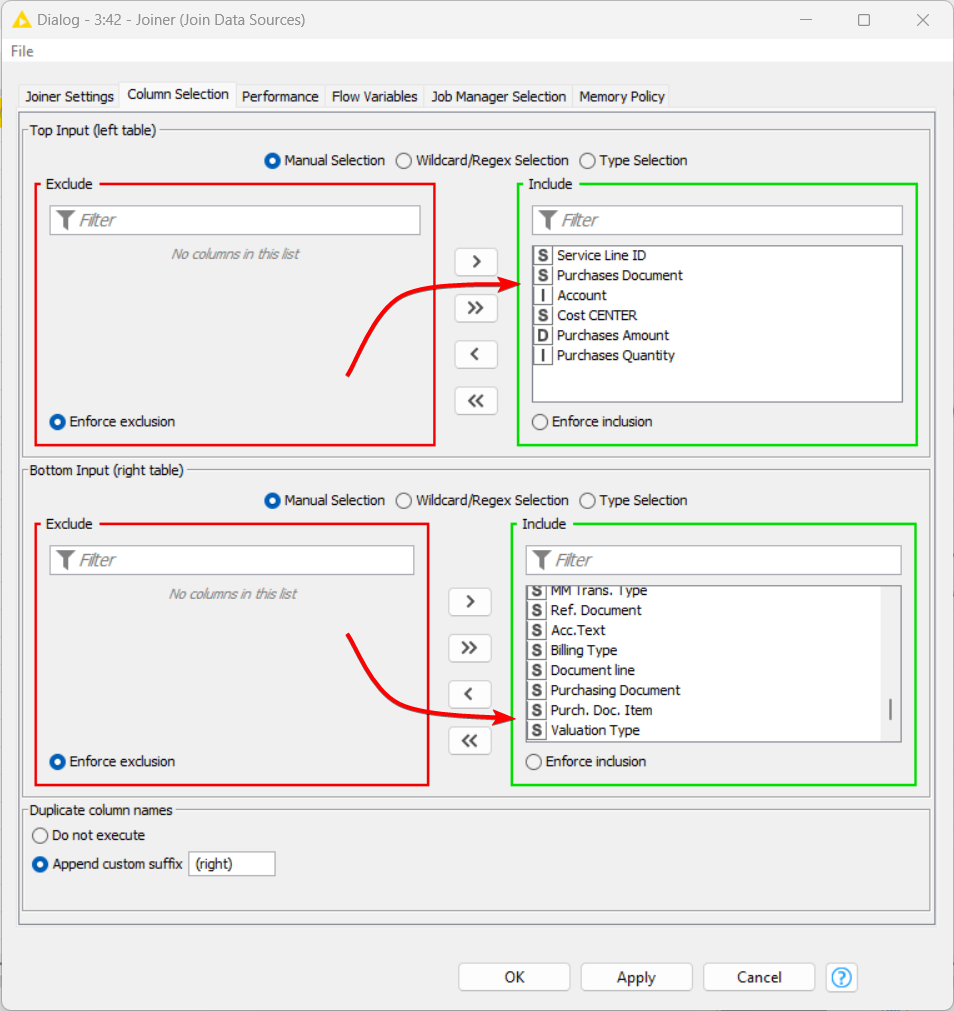
1- The top port you will bring the most and completed information that you have and the second port will complete your blank fields with information that you need. As can you see at the image below from this node configuration, the left site is your principal table and the right side is your insert data table. It’s very important to select only the fields that you need, as best practice, to clear the memory and run faster the flow too. If you need only 4 fields from a table and 6 from another to make your report, select only this fields at the columns tab and all others fields you’ll set at the exclude windows.
2- You can split it or not with the output options (top, middle, bottom), to make easier to manipulate your flow if necessary. Normally, I use the split option and after that, I concatenate the nodes to make a full list again. And then, when this process is completed, you can use renamer node to change any field that you select to make adjusts and column resort to change the position as you wish too.
3- Use “merge join columns” to avoid duplication columns. With it, you won’t need to use a column filter or renamer node.
4- You can select at the tab “columns selection”, which fields will be used to create your full table, and if you have a duplicated column, you can set to do not execute, removing duplicated columns.
After all of this, you’ll have the qualified table will a lot of information to build your report. You can use a “Pivoting” node or “Group By” node as @AlexanderFillbrunn told before to bring some numbers and results as an Excel model for you.
I just put some tips to you and the community to make some sense for someone and help with the rock paths.