After upgrading the server (version 4.9), we now encounter the problem that our server is almost constantly out of memory (Execute failed: No space left on device). We emptied the trash already and we set the automated removal of jobs on 7 days.
But it seems that some jobs don’t get deleted, as the amount of memory keeps high for the jobs.
Could this be related to the fact that we start flows via a JSON and Call Remote Workflow and that we can’t “see” those jobs and therefor are not able to delete them?
Does anyone know what could cause the memory problem on the server? And how we could fix it?
We didn’t have this problem with the previous version (3.7).
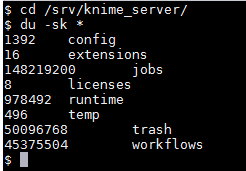
Do you have access to the server’s file system, so you could identify which location exactly takes up all that space? I’ll assume that it’s somewhere in the workflow repository, but is it actually the jobs directory, or temp, etc.? Or are there some error dump files somewhere?
Don’t think it’s because you start jobs via Call Remote - those should get discarded after execution in any case, so those shouldn’t take up space.
Seems like there is still a bit in your trash directory, but not too much. Jobs seems to hold a fair bit more. Maybe decreasing the job retention time could help? E.g., setting com.knime.server.job.max_lifetime= to 2d could help. Note that jobs are stored in executed state, including all data. Therefore, disk space could fill up rather quickly if there are many jobs running, and you keep them around for 7 days.
That being said, none of the directories in your screenshot seem overly large. What’s the overall disk space on that volume?
Thanks again for your fast reply!
The overall disk space is 250 GB.
Some other things that we encounter:
we see jobs on the server that we don’t see in KNIME itself (UI), so not able to manually delete them.
we see a job of 60 GB, which is way more than the average scoring job (around 10 GB) . This model was scored on a different table on the server. But why it is this big, we don’t know.
We can see the setting of deleting jobs after 7d, but when checking on the server, we see jobs that are older than that. Fe. the oldest job is over 3 weeks old.
Note that we scored the same way on the previous version and that since updating to 4.9 we encounter this server memory issue.
Thanks again for your help, as we don’t know what to look for
Thanks for the additional information, I think we’re slowly getting there
You will only see jobs owned by yourself, unless you are logged in as admin. Are you logged in as admin?
That is certainly large for a job. How many of those are on the server? I can surely see those jobs clogging up disk space if they are not kept in check. It would also make sense for the jobs to be larger in the new release. We replaced the old gzip compression algorithm with one that is much faster, but that also creates larger files. So might very well be that the same number of jobs now fills up the available space a lot faster
I’m currently not aware of any issues removing jobs. One thing that comes to mind is that jobs get deleted after 7d of inactivity. This means that if you open the job in the meantime (e.g. via the remote editor), the job gets reloaded into memory and the counter is reset. Can you confirm whether the jobs have been opened after they finished?
Thanks again for sharing your thoughts on this matter :).
To answer your questions:
I am not logged in as an admin, but some of us are. And it looks like some jobs are still not visible then, but we are currently not able to check that. What we do know is that jobs that are scheduled are visible for everyone.
We will get back to you with some more information tomorrow. The problem is that we don’t know how we can collect this information on the server (other than via UI). Tomorrow someone can help us with that.
There is only one large job on the server. This is a flow where we score a GradientBoosting algorithm, and I know this has been scored a couple of times (on 4,5 million customers) in the last two weeks. It may be relevant to add that we score on a created table on the server, but that is the case for all our scoring flows/jobs. Question is how we can manage this volume of data that is created in the process?
We did see jobs that had no activity within the last 7d on the server. I will get back to you on the number of jobs without activity tomorrow as well.
If there is any information that could be helpfull in solving the problem, that we should be able to collect on the server, please let me know.
Just as a quick follow-up, which exact version of KNIME Server are you using? There was a problem with “invisible” jobs which we fixed in 4.9.2, so if you’re on an older version, an update might help.
We have version 4.9.2 installed, so either we have unintentionally proven that the problem isn’t entirely fixed, or something else is causing this. We see 26 jobs in KNIME (we all have admin rights by the way) and we see 82 jobs on the server… The jobs in Knime all seem to be created/opened within the last 7 days, but on the server there are still a lot of jobs that are way older (over 3 weeks) and can not have been recently opened, as we don’t see them in Knime.
Biggest question now is: where do those jobs come from and why don’t we see them in Knime UI. And how do we delete them in the best way.
Regarding the job that was 60 GB we discovered which job this was and we did see this job in Knime.
We deleted this job now and it created a fair bit of space on the server. But we have no idea how this job could get this big. Contrary to what I said before, this is a relatively small flow with a loop in it, where we check for certain values and where we trigger (with JSON) our scoring flows on the server if they meet the criteria (in this case 6 flows were triggered). This flow is executed every day but this time it created/used exceptionally large volume of data. Normally it is around 12GB.
Too bad! Let’s dig a bit further. Do you have access to the server’s file system? If yes, can you please check in ./workflow-repository/jobs if those jobs are there? Also what their size is. You can find more information in the job-state.json that is located within each job’s directory. If you have access to that, you’ll at least know where the jobs came from, which might provide some helpful information for how to proceed.
I have tried to take a look at what you suggested (workflow-repository) but I don’t know exactly where to find it. My knowledge of getting around on the server is pretty limited to be honest :). But I am able to create a list with jobs and their respective size. And I am also able to see what jobs are the big ones.
Like I mentioned in my previous post: there is a flow where we check for model scoring flows that are ready for scoring, based on their last scored date. In this flow we collect the relevant flows and trigger them with JSON, one at a time. This flow seems to be causing the memory problem, as we executed it again yesterday and it used up 44GB of memory on the server. The flow wasn’t finished (only one scoring flow has actually been executed, 5 still remained to be scored. probably because the server was already out of memory) and the respective job was nowhere to be found on knime ui this morning.
This makes it difficult to “delete” the job, other than directly on the server. But we don’t know how to do this and whether this is smart to do?
We executed this flow on the previous version of the server every day and it gave no such problems with memory usage. So I get the feeling that something changed in the way the memory is stored/used since upgrading to 4.9. And if so, how could we change this or can we make sure this particular flow doesn’t use op all the memory?
Since your jobs are very large, I can see how you can easily max out 250GB of disk space. To narrow down the issue, one thing you could do is to revert back to the compression format we used in previous versions before Analytics Platform 4.0. As I mentioned above, the new compression format is a lot faster, on the expanse of creating larger file sizes. If it worked before on the same machine without issues, I’d give that a try.
To go back to the old format, please add the following line to the end of the knime.ini file, which is found in the main directory of the executor installation (where also the executable is): -Dknime.compress.io=GZIP
Please restart the server afterwards.
I know this won’t solve the issue about jobs not showing up / not being able to delete them, but I think it makes sense to first get everything back running, and then fix those parts.
We have reverted back to the previous compression format (in the .ini file) and we will monitor in the next days if it reduces the disk space used by our scoring flows.
Next to that we have (as suggested) restarted Knime on the server and what did we see? All jobs that we couldn’t find in Knime UI, but did see on the server, were not there anymore! And also the disk space that was used by these jobs, was released. So restarting the server also helped with that issue. Although it is still not clear why these jobs were there in the first place.
We will investigate the next coming days if we can reproduce the issue with disappearing jobs or with the jobs using a lot of disk space. Hope not :).
Great to hear! Yes, restarting sometimes fixes things, but we shouldn’t end up there in the first place! Please keep an eye on this, if it pops up again, we need to investigate more.

 Let’s dig a bit further. Do you have access to the server’s file system? If yes, can you please check in ./workflow-repository/jobs if those jobs are there? Also what their size is. You can find more information in the job-state.json that is located within each job’s directory. If you have access to that, you’ll at least know where the jobs came from, which might provide some helpful information for how to proceed.
Let’s dig a bit further. Do you have access to the server’s file system? If yes, can you please check in ./workflow-repository/jobs if those jobs are there? Also what their size is. You can find more information in the job-state.json that is located within each job’s directory. If you have access to that, you’ll at least know where the jobs came from, which might provide some helpful information for how to proceed.