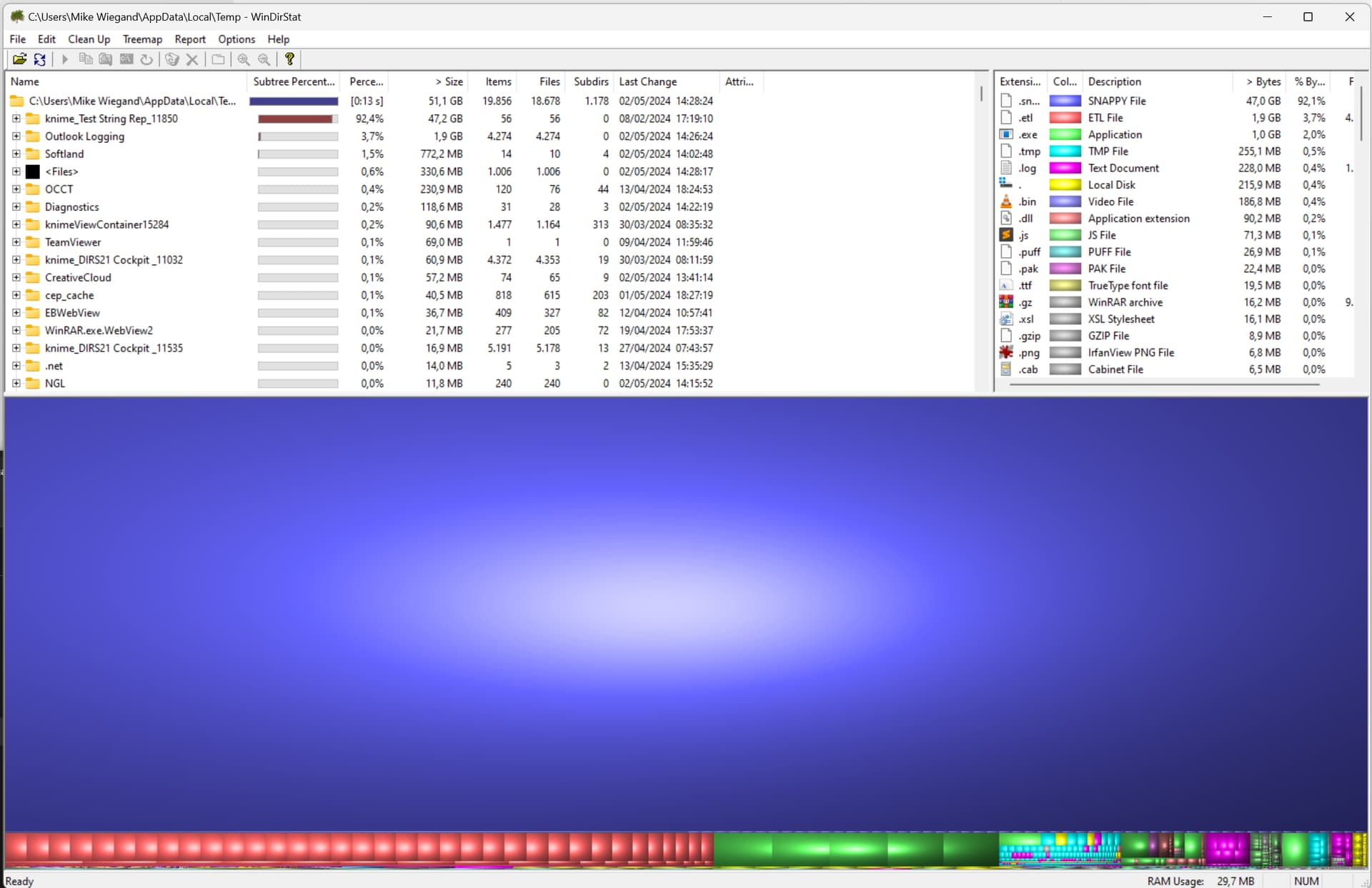
Since 8th of February 2024 Knime got updated several times but still the temp data is present. I also opened and closed the workflow, yet it persists. Shouldn’t that data get deleted after successfully saving the workflow?
It looks like the folder is a leftover of an AP crash. Each time a workflow is opened a new temp folder is created with a new random suffix (_11850 in this case), and it is removed again when the workflow is closed. In case of a hard crash, the cleanup code doesn’t run, so the folder stays behind. Opening and closing the workflow again uses a different directory name, so the old one is not affected at all.
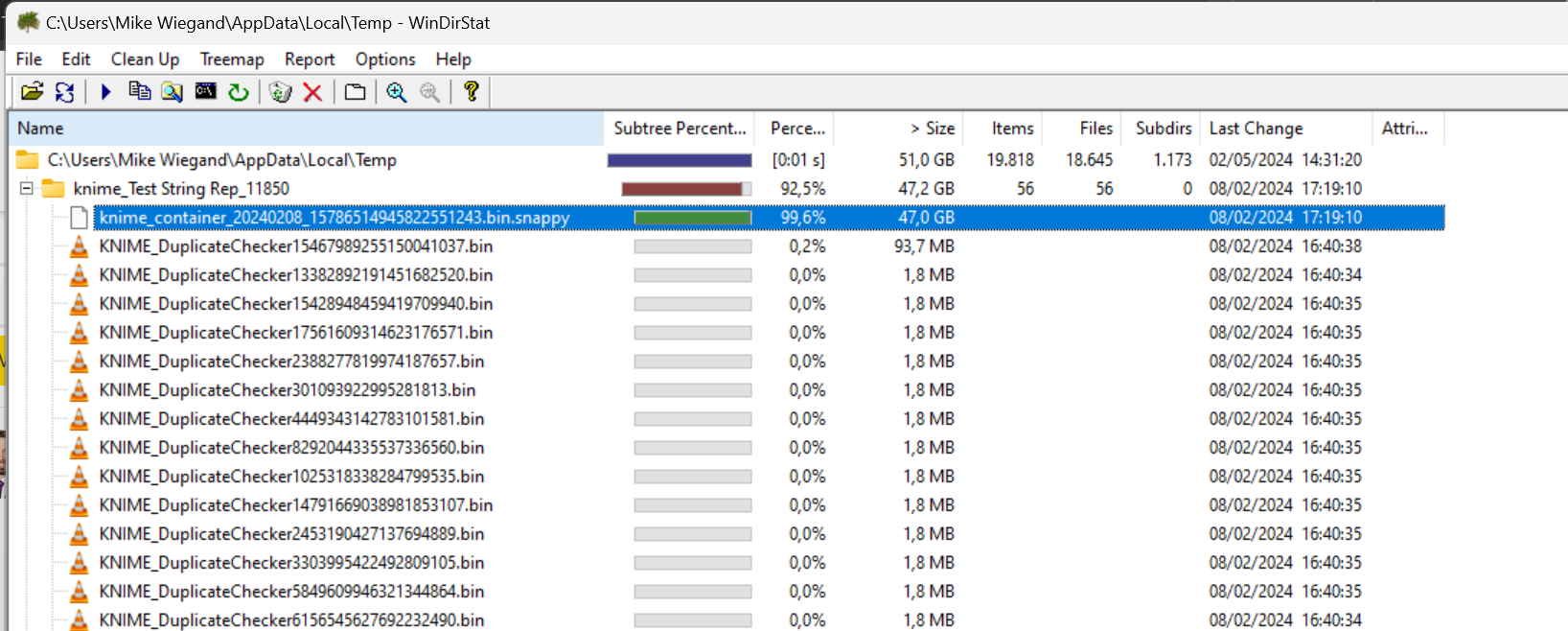
All the KNIME_DuplicateChecker*.bin are another indicator for AP being interrupted while the workflow was being executed. These files are only created while an output table is being written and then deleted right away. They only stay behind if there’s a hard crash before the table is fully written to disk.
To clear up the disk space you can just delete the whole folder. It only contains intermediate results created while the workflow is being manipulated and executed, when you save the workflow all the result tables are copied into the workflow’s folder in your workspace.
thanks for the explanation. Though, wouldn’t it be a good idea to have Knime check if there are any leftovers in the temp folder and clean them up? Maybe even programmatically after a an AP crash? Or even add an option in the preferences that keeps an eye on the Knimes temp folders to allow to manually clean similar to the garbage collection?
PS: For better control I created a single folder in temp but Knime could not create it by itself throwing an error about write rights or so. I am concerned that, by deleting all tempo data, Knime faces that issue again.
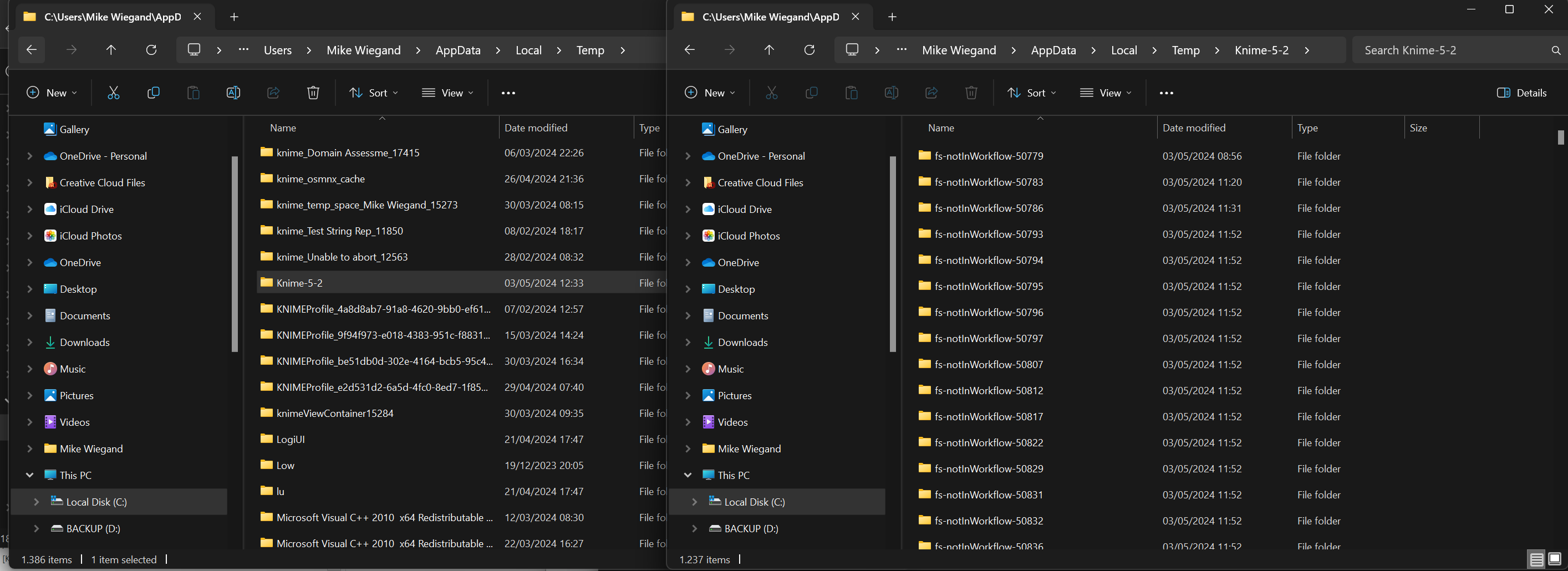
Reason for me to delete all tempo data is, as you can see below, that Knime not follows that naming scheme strictly. Also, when Windows disc cleanup ran, it could remove that folder I created too, possibly causing troubles.
Though, wouldn’t it be a good idea to have Knime check if there are any leftovers in the temp folder and clean them up? Maybe even programmatically after a an AP crash?
Since you can use any folder as AP’s temp folder and the folder names are (as you observed) not always consistent between different code paths, we would have to keep track of all temp files/folders we’ve created and not yet deleted in a way that survives a crash (potentially in the workspace’s metadata area). AP could then check during startup and delete leftovers. I’ll create a ticket for it (because that’s quite a lot of wasted disk space), but I can’t promise anything in terms of of a fixed-by date.
PS: For better control I created a single folder in temp but Knime could not create it by itself throwing an error about write rights or so. I am concerned that, by deleting all tempo data, Knime faces that issue again.
For now I would recommend that you either
use your operating system’s TEMP directory (%TEMP% on Windows, $TMPDIR on Linux) and rely on the OS’s logic for cleaning up orphaned temp files or
create a designated directory somewhere outside of the TEMP directory and delete all contents whenever it becomes too large. As long as no AP is open, it’s safe to delete all files and folders in it, they are not referenced anywhere.
Thanks for your quick response. What I meant is that Knime, by default, creates a sub-folder in the systems temp-dir to prevent that messiness I noticed which makes it difficult for me to identify the deprecated Knime temp data.
My primary motivation, alongside keeping thigs tidy, is to improve Knimes reliability but also find a possible explanation for the performance regression that others and I reported many times over like that recent post here where I believe to understand what is happening:
PS: Sorry for the side question but what is your take on the idea to prevent Knime from writing any temp data to disk i.e. by utilizing a ramdisk? I also tried, while investigating about the perf-regression, to disable compressions and various other args in the knime.ini but none showed any significant improvement except using the ramdisk.
PPS: Is there any way to prevent, whenever globally for Knime or individually per workflow, saving any temp data? The workflow that currently runs utilized Don’t Save Start/End nodes
I also write the results after each iteration into data in the workflow data directory. Still it writes so much data to disk that I am worried about what happens when the parallel chunk end node collects the results.
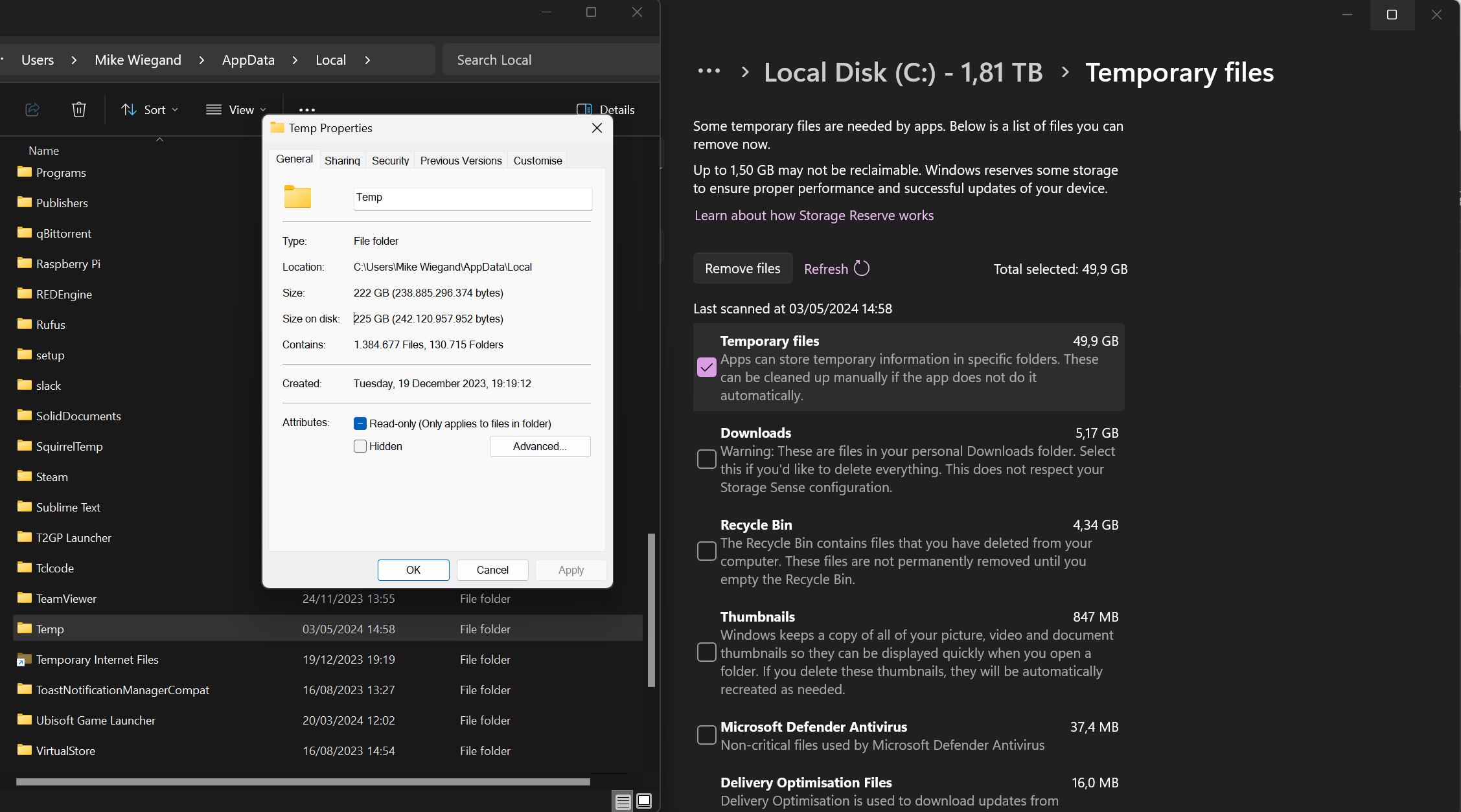
Cleaning the Temp data does not work using the Windows cleanup. The Temp folder in the summary vanished after click on remove but upon refresh it appears again with no change to the disk space.
Windows Cleanup, even if it ran with admin privileges that my user has anyway, no file was deleted. I cleaned the entire temp folder manually which took about 10 minutes and shows some significant CPU utilization:
Upon ending the web driver, the folder are still present in the temp directory and running the garbage collector, just in case it triggers something, as well as saving and closing the workflow did not have any effect. Only upon closing Knime the irrelevant temp data got deleted.
doing further debugging I noticed that, even though just one browser was opened, two in size identical folder got created. That lead me to suspect the Network Dump Start and End Nodes. After removing them, no temp data got created anymore.
Apologize for the messy comment but my brain is on fire trying to get to the root of this. Two more things, I added these options --disk-cache-size=0 and --incognito.
Thank you for the nudge, mweigand. For now this is just a quick ack, as I’m currently on the way into vacation. I have it on the radar and will keep you posted. Can you describe your workflow setup? At first glance I see the “Parallel” loop - does it also happen without these?
yes, the mass of temp data was also generated without the parallel chunk nodes. I got it resolved or better know how to mitigate it. Enjoy your vacation!
PS: Wanna finally have our call we tried to arrange for god knows how long when you are back?
One “easy” fix would be to change the temp-dir logic to try to create the innermost folder if it doesn’t already exist. Then you could specify <User-Dir>/AppData/Local/Temp/KNIME or similar and nothing bad would happen if that folder got deleted manually or by the OS. Would that already solve this specific problem you have?
I don’t think that we’ll add something like a ramdisk to the Analytics Platform any time soon, because that use case is very narrow (all temp data must fit into spare memory, but we don’t control that – see third-party extensions) and can be achieved externally (as you’ve proven yourself). I still think that this is a very interesting approach if you need maximum performance and have a bunch of spare RAM!
Well, at least the result tables of nodes you’ve executed after the last save of the workflow have to live somewhere other than inside the workflow.
If you close the workflow without saving, you expect the previously saved results to still be there after reopening, so we can’t overwrite those.
The output tables can be much larger than main memory, so keeping them in memory isn’t generally possible either.
yes, that would do the trick. Storing all temp data in one folder would make identification and fix, if the issue appears, much easier too. I tried deleting all files but seen in one screenshot, one file/folder, was constantly use despite no Knime process running.
About the RAM Disk, that was less a request but more aa general question about your thoughts. I found this also quite interesting and preliminary results showed promise.
Well, at least the result tables of nodes you’ve executed after the last save of the workflow have to live somewhere other than inside the workflow.
If you close the workflow without saving, you expect the previously saved results to still be there after reopening, so we can’t overwrite those.
The output tables can be much larger than main memory, so keeping them in memory isn’t generally possible either.
Without saving, you refer to a crash, don’t you? If that’s the case, most likely the data will be irrelevant anyway I suppose, especially if a loop was partially executed. My idea was more about leveraging a systems hardware as good as possible.
I.e., knowing the OS and Knime resides on the primary SSD, with Antivirus and other running on it as well, I stored the workspace on another disk and aimed for a scenario where Knime is not running into any OS limitations like a backup software kick’n in, browsing the web etc. potentially causes aa read/write bottle neck which is the most likely to happen.
No, I’m talking about opening a workflow, playing around with it without saving, deciding that I don’t like the changes and then closing it and choosing “No” when I get asked whether I want to keep the changes. In that case I would expect all the old output tables to be intact, not overwritten by the experiments.
Gotcha, though I thought that the results present upon opening a workflow are stored in the workflow directory so only temp data calculated before saving is written in the temp data. Or do I get you totally wrong?
That’s exactly right. My only point was that we can’t overwrite the files inside the workflow folder directly whenever a node is being reset and re-executed interactively. Both old and new result must exist at the same time (in the WF folder and temp folder respectively). There is no way to keep the current way that AP interaction works without writing temporary tables.
Thanks a lot @qqilihq … I had a close look on the temp folder and are execution some extensive crawls at the moment which run in the background. Trying to invoke some exceptions or just “killing” the Knime process to simulate i.e. out of memory or any other issue.