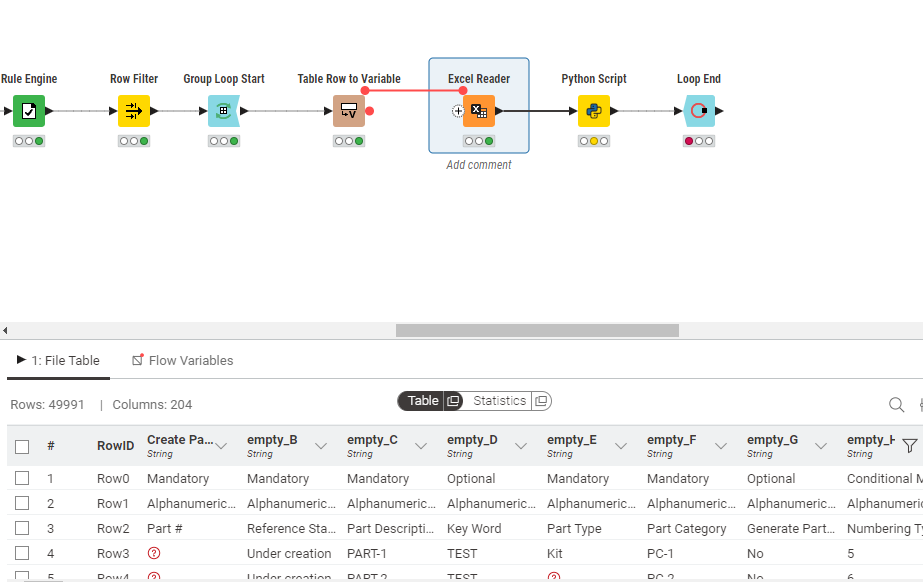
Hi @san_98, you are right that a column list loop to process a spreadsheet of 200,000 rows x 200+ columns may be slow to process but now that you have given an indication of spreadsheet dimensions, I have looked at performance and for an Excel spreadsheet of 200,000 rows by 220 columns, this was the breakdown of processing times:
| Process |
Seconds |
| Excel Reader |
81 |
| Pre-loop processing |
41 |
| Looping all columns |
128 |
| (This was for a table with no missing values, so it had to loop all columns) |
|
This shows why it is good to have information about data volumes and other factors which could influence performance, as they can affect the amount of effort expending on optimisations. There is little point optimising something that is “good enough”.
So, with this new information, there is one very easy optimisation: terminate the loop with “Variable Loop End” instead of “Loop End”.
This can be done here since we don’t actually need to collect the data from the loop itself, and doing so wastes time as it has to collect and combine data.
This one change reduced the loop time to:
| Process |
Seconds |
| Excel Reader |
81 |
| Pre-loop processing |
41 |
| Looping all columns (Variable Loop End) |
14 |
Yes really… on my system 128 seconds became 14 seconds with that one change.
Big learning from this is to use Variable Loop End unless you need to collect the data from the loop!
I have updated my original workflow on the hub with this simple modification.
It got me thinking though about how to reduce the loop requirements further.
My thinking: it would be great to not loop at all if we could know in advance whether there are any mandatory columns, and any mandatory columns containing missing values.
I have uploaded an enhanced version of the original flow onto the hub that attempts to “pre-know” by first of all filtering the “mandatory” columns and then, for each of those getting counts for all the columns of the number of non-missing values. This can be done by GroupBy quite quickly, and much faster than the Column List Loop.
The Column List loop then only acts on columns that are mandatory and contain missing values (and in this instance will of course always terminate with the java snippet “abort” on the first column encountered, so it doesn’t strictly require a loop at all, but it was more convenient to leave that part of the processing alone.
I also looked at additional optimisations in the initial processing because previously the “transpose” to determine mandatory columns was being performed on the entire (200,000 row) table. This only needs to occur on the top (non data) rows. That makes a big difference to the amount of data being shifted around, and therefore time.
For the same Excel file as above containing no missing mandatory values, the timings beyond the Excel Reader (which hasn’t changed) were:
| Process |
Seconds |
| Filtering only columns containing missing values |
2 |
| Looping all columns |
0 (didn’t need to execute) |
And how does the timing compare when there is missing data?
Running the same process on an excel file of the same dimensions with missing data in at least one column resulted in these timings:
| Process |
Seconds |
| Excel Reader |
78. No actual processing change. Just a fluctuation - still around 80 seconds |
| Filtering only columns containing missing values |
2 |
| Looping columns |
0 (always now terminates on first iteration) |
So basically, almost all of your processing time will now be on reading the Excel file, rather than finding the mandatory value validation.
Here is a link to the enhanced version. It contains more complexity up-front. The original version with the Variable Loop End modification is reasonably performant so whether you need to additional complexity depends on how many files you have to process and your overall timings. You might also choose to take some of the enhancements from the newer version (the variable loop end, and that table transpose optimisation I mentioned) and leave the rest.