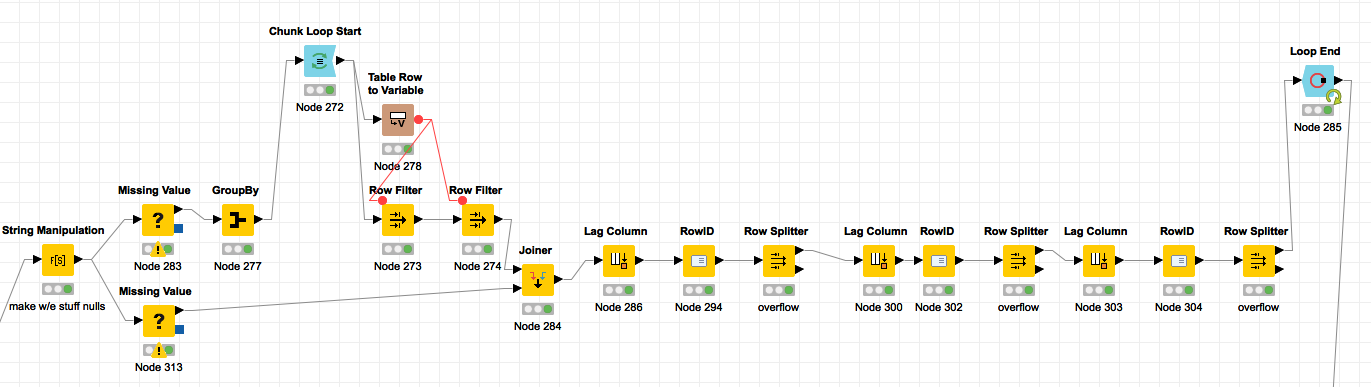
Here’s how I handled dealing w/ the ‘lag’ and based on @Geo 's response, I was able to come up with this little thingy and i have no idea if it’s what “group loop construct” means but it was enough to push me a direction…
need; repeating the lag in the next column over… and restarting it, otherwise it’s always breaking the lag on new “groups”… (if there’s a lag on that iteration)
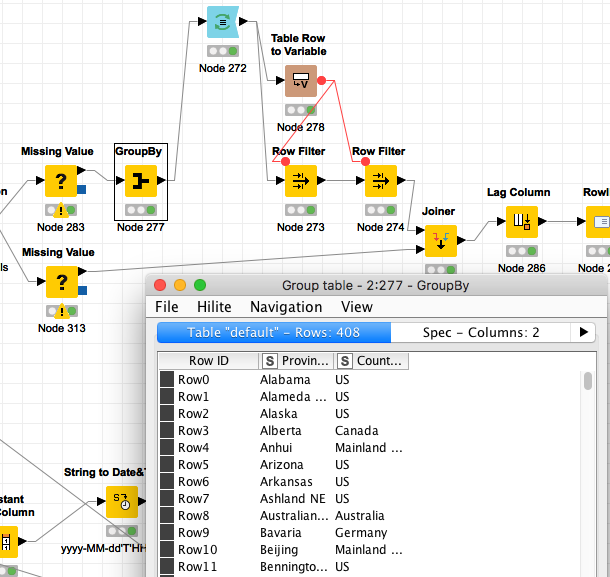
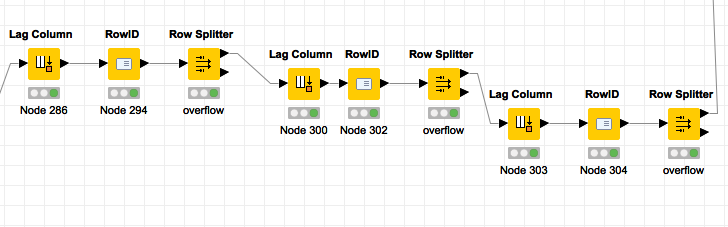
building two streams, the top stream is a group by on what I need to “lag by”…
start the loop in front of the group by, the table row to variable lets me grab these columns, per loop, and insert them into the “row filters” per column…
lag column (choose your column), 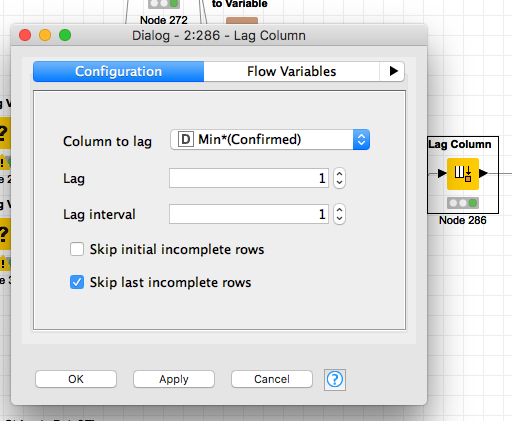
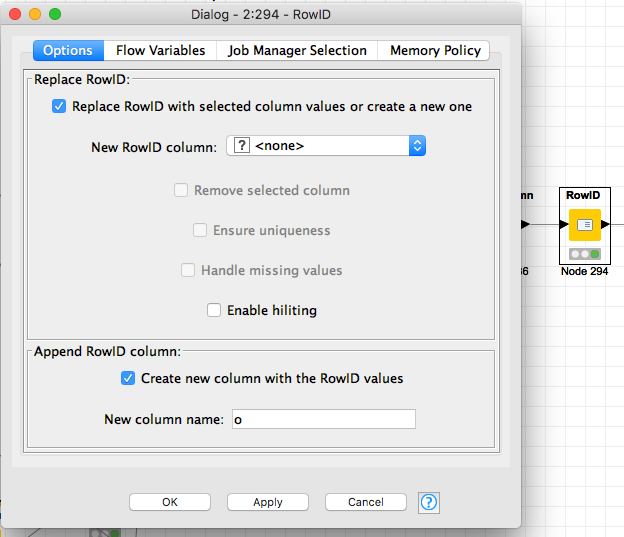
row id (helps remove the overflow),
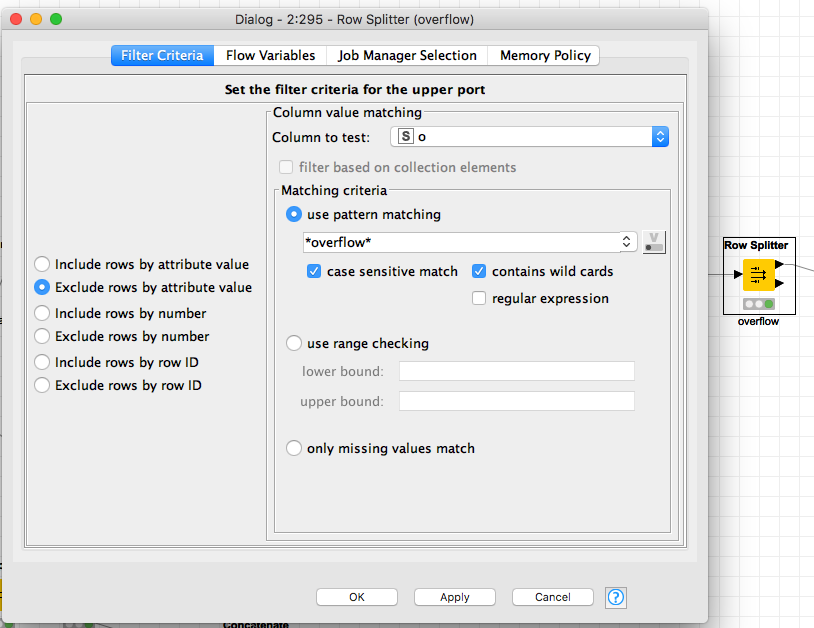
row splitter = overflow*
MORE on rowid in 3 steps above… When there’s an overflow by the lag, knime accounts for this and makes a NEW row of data, it adds the text “overflow” to your rowid, rowid node effectively PUSHES that ‘string’ to a column and builds a nice juice’y RowId column for you again, then we filter.
Sometimes there’s NO overflow, that means your lag math cancels out, this stream takes that into account. I needed to do 3 iterations of the lag column for deaths, recovery, and confirmed coronavirus cases.
thoughts;… assuming concat() these two columns, and same with the stream, would simplify the ask, to 1 red line, one filter column… However i don’t think optimization is necessary on this stream, and i maybe over complicating by even placing this bit of information here… but if you’re like me, you want to optimize this too.
conclusion, the 3 lag
processes feel identical and could be looped with some crafty knime’ing, my first pass so keeping it simple today().
best,
t
ps. feel free to share a better way of doing this process because im a noobie.