The dataset from which [Linear Regression Learner] Node is taking in for training are all numeric. A number of the columns contains binary data: 0 or 1.
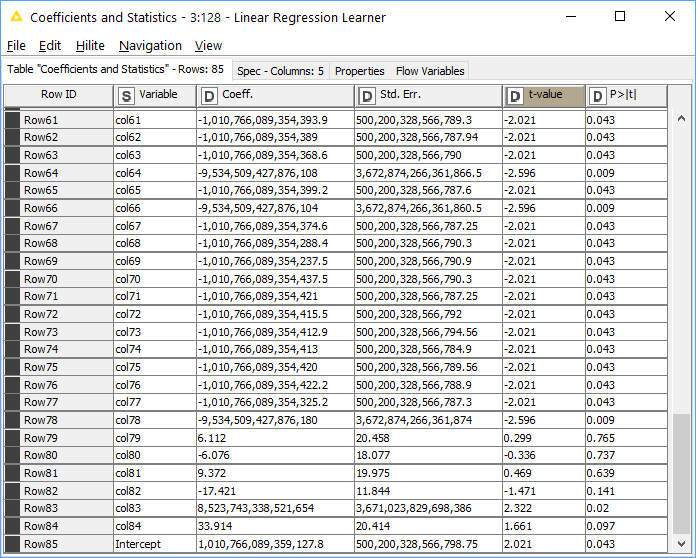
Is it normal/usual to see absolute coefficient values above 1 trillion under the column “Coeff.” ?
In the screenshot, their p-values (column “P > [t]”) are below 0.05 which means they are significant enough to be included in the linear regression formula. But I’m holding back because they are such big coefficient values.
To answer the question, yes, you guessed it correctly! This was for my first academic assignment using Knime.
Pertaining to point #1, the (many) binary-data columns in ‘Qn003.csv’ was the result of one-hot encoding of the original columns with categorical data. I was told it is possible that some learning algorithms work better with numbers than with String data type. I avoided label encoding.
Thank you for suggesting point #2 and #3.
My actual assignment workflow had more Nodes than ‘Qn003 - Large coefficient values.knar’.
The knar file posted earlier was created to find out from the community if any members have encountered large coefficient values (output by [Linear Regression Learner] Node) before and could possibly share with me what is the known cause and how they finally managed to rectify it.
I could exclude columns that resulted in large coefficient values reported by the learner node but something’s telling me that doesn’t seem to be addressing the problem.