Hello KNIME Support.
I have a question about memory issues with Spark to Table nodes.
I am using Spark via Livy in my current project. I want to take 10 million parquet data and convert it to Table to Spark, then Spark to Table again and convert it to csv.
However, even if I set both Spark Driver and Executor in Livy to sufficient memory (100 / 120), I get the following error message Out of memory.
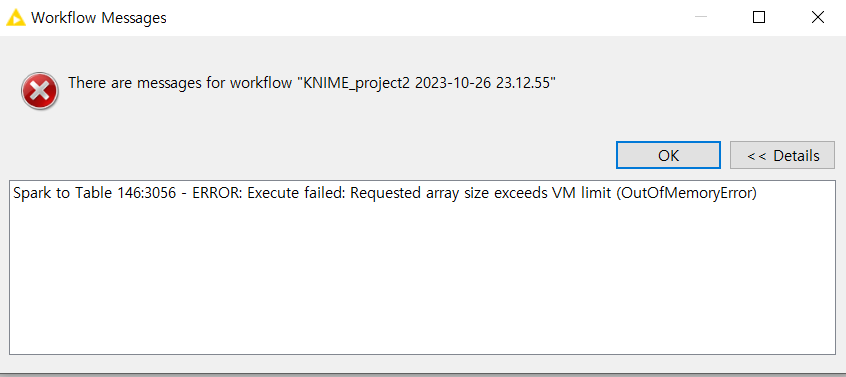
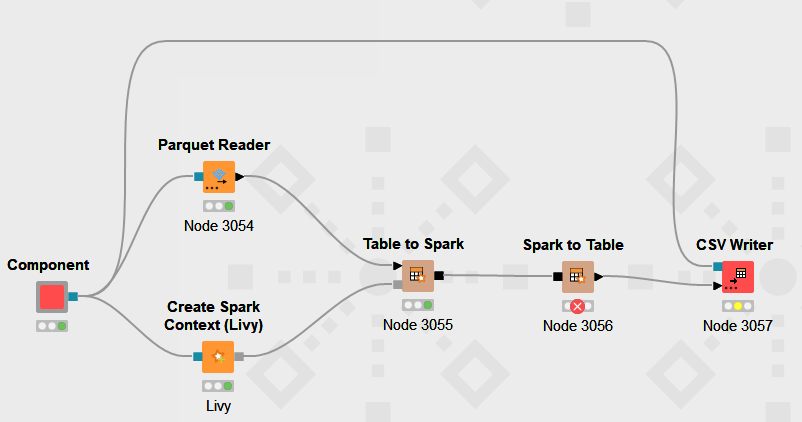
The example WF above was created for a simple error, and in reality, there are many preprocessing and analyzing nodes in between, including Pyspark Script.
The answer I’d like to hear is, does the original Table to Spark consume a ton of memory, and what method should I use to transform it within the given memory?
I need to export to CSV unconditionally. There is no other option, any help would be appreciated.