cause you helped me a lot with my last problem, I now now hope that this amazing community can help me again with my LDA-Topic-Extractor Challange:
I now have a solid-pre-processed corpus just around 305 texts in various length.
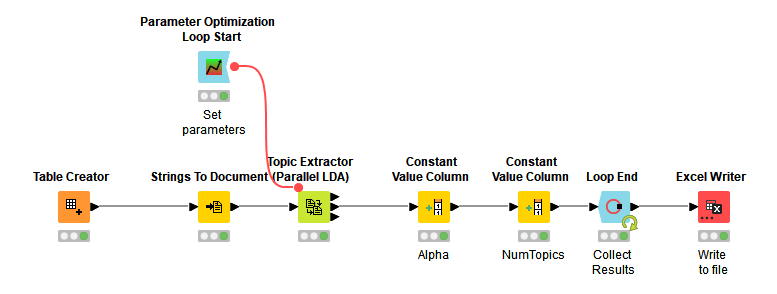
Now I want to extract some lda-topics with the Topic Extractor (parallel lda)-node. But instead of changing the parameters by hand and validating/ evaluating/ interpretating the results manually I would love to have a loop-workflow in which I:
could vary the parameter “No of topics” from 10-30
and in each iteration again could vary the alpha from 0,1 to 0,5
for the start “Beta” should be fixed at 0,01, the same for “No of words per topic” by 10, the “No of iterations” by 1000 and the “no of threads” by 10.
It would be amazing if the results could be right away written in one or more Excel files locally.
U see I have a lot of “whishes” but not really a clue where and how to start.
As you might imagine, this workflow could take a while to run, so you might want to run it with a smaller subset of parameters (as I have here) to test it first.
first of all: thank you very much for your fast answer. Actually I had that Parameter Optimization Loop Start node just in my hand, but I didn’t really knew how to handle it. But your workflow looks just as simple as it could be perfect for my needs! I will try it right away and will be back soon (hopefully)! Thank you and best regards.