After few years of using KNIME, this is my first time expanding my knowledge to supervised machine learning models. This week, I picked the Decision Tree to begin my journey with. Would appreciate if you guys can help with my “Mr. Accuracy” and “Mrs. Cohen”. It’s weekend now - I don’t expect a lot of people online to help, so I’m appreciative of any help at all from anybody who’s viewing this thread.
Here’s how my data looks like. It’s just a simple data merely to have something to work with for my journey’s beginning:
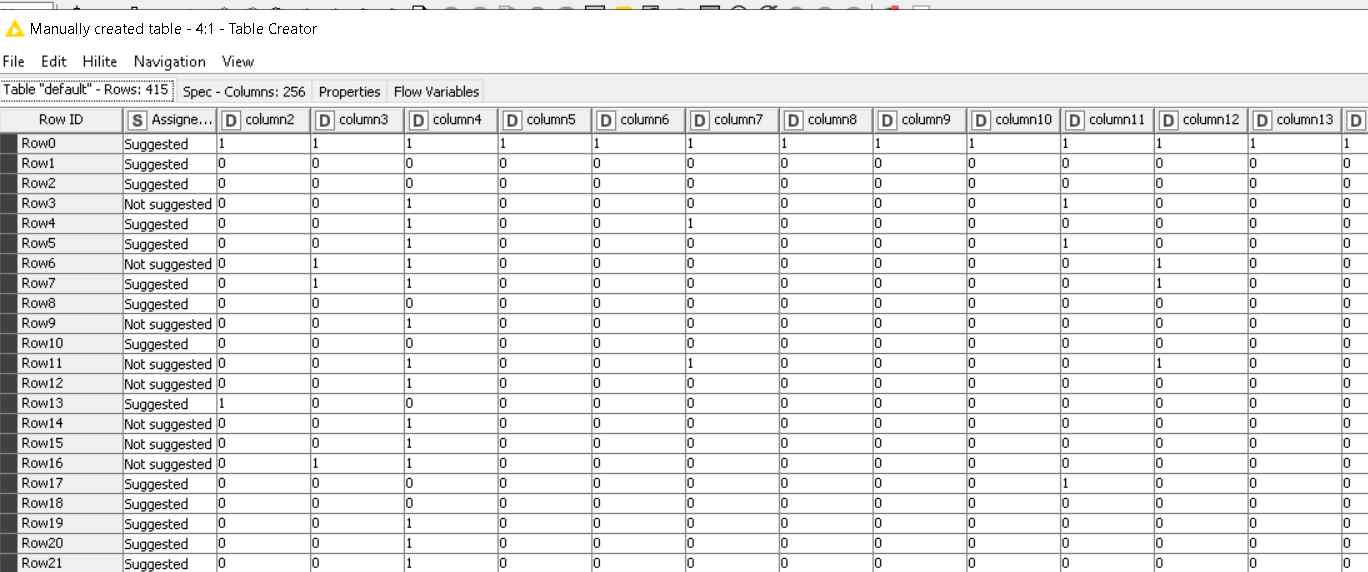
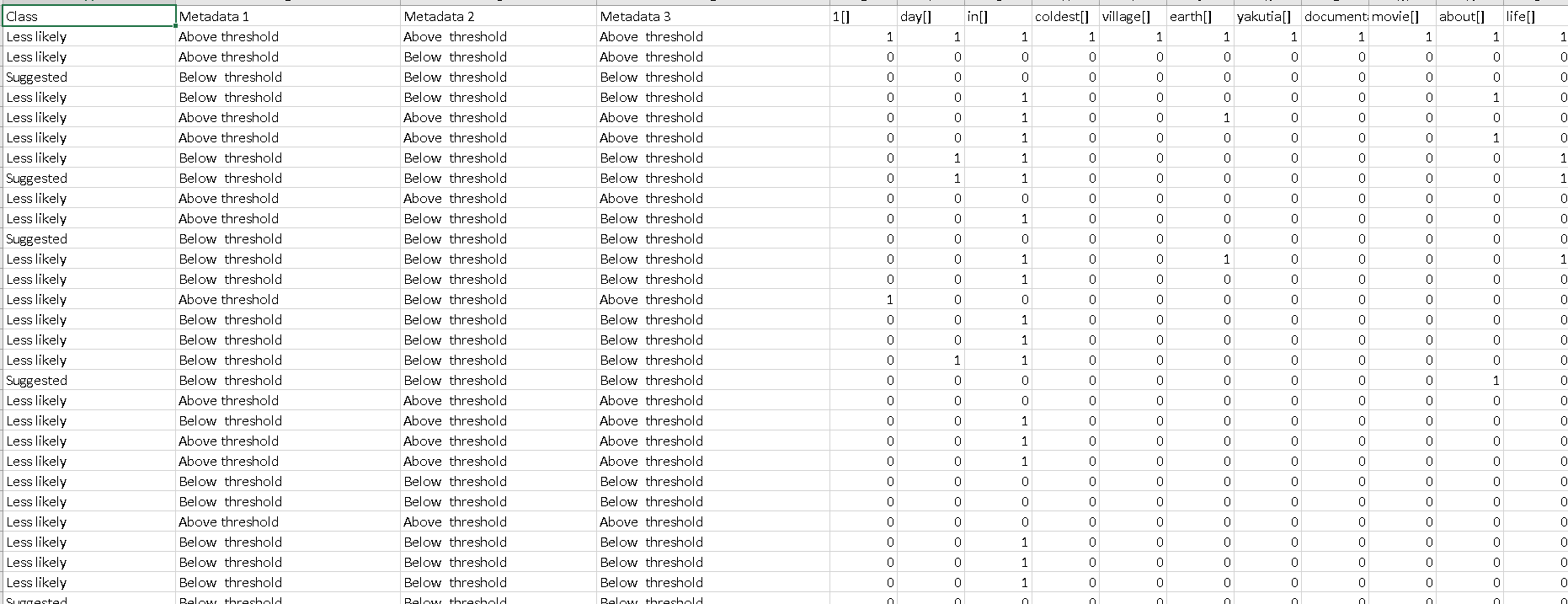
The first column is the assigned class (dependent variable), while the rest are the available terms in each document (1=available, 0=unavailable). The goal is to predict the assignment of new documents to either one of the two classes based on the term space.
My accuracy can’t reach & go above 0.6, and the Cohen’s kappa can’t reach 0.2 & above. Here’s the abridged version of the workflow showing the different attempts I made to build the model:
DT 1.knwf (2.1 MB)
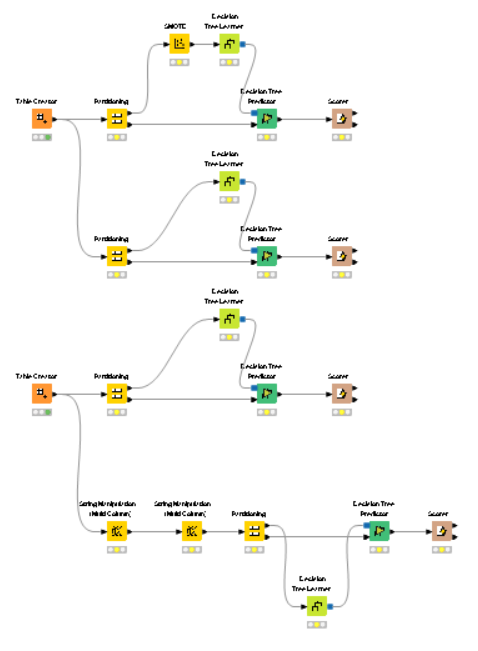
One of the attempts I did in the workflow to try to enhance Cohen’s kappa was to use SMOTE (reference: this article).
The term spaces was the result of using the Document Vector node, as used in one of the KNIME’s Example Workflows. I didn’t demonstrate the preceding tasks in this abridged workflow.
In summary, I would like to know why my accuracy and Cohen’s kappa values are too low despite these attempts I made.
Thank you in advance for your time!