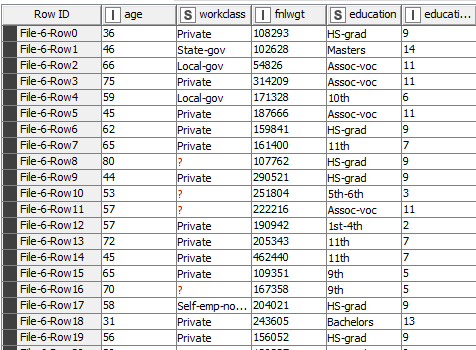
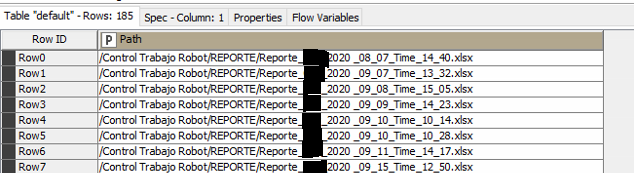
Necesito agrupar ficheros, con idéntica estructura, que tengo en una biblioteca de SHP. Esos ficheros no tienen internamente ningún campo que informe la fecha en la que se crearon. La única referencia sobre fecha está en el nombre de los ficheros, que tienen una parte común junto con la fecha de creación. (con excel reader puede tenerlos agrupados pero sin la información de fecha de creación)
He localizado en el Hub un flujo que con un nodo java realiza el proceso de lectura del nombre de cada fichero:
No me queda muy claro lo que quieres hacer. Basado en las copias de pantalla que nos has enviado, puedes por favor componer a mano el resultado esperado, por ejemplo escrito en un fichero Excel y subirlo aqui, para que te podamos ayudar ?
Estoy seguro que no es complicado lo que quieres hacer, pero con un ejemplo del resultado será más fácil ayudarte.
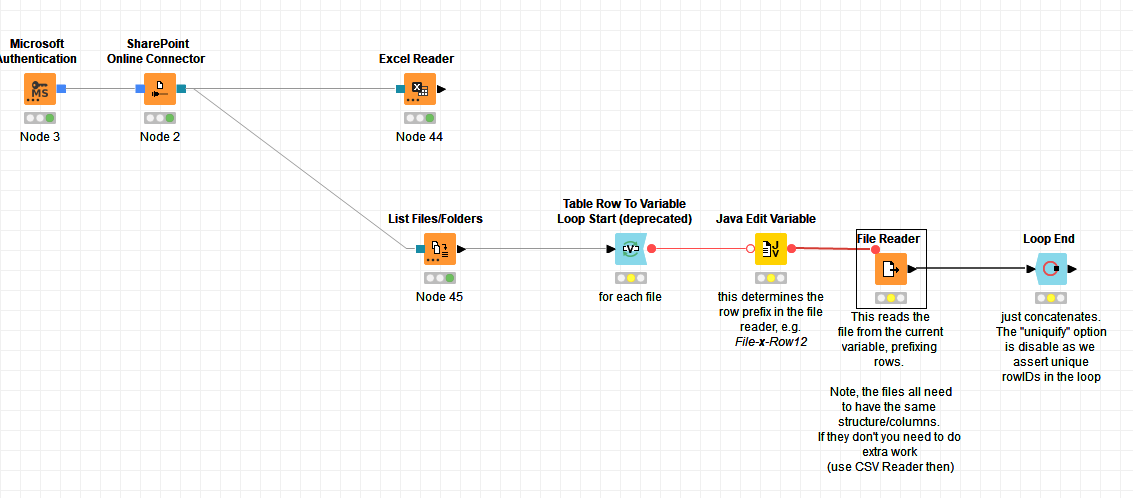
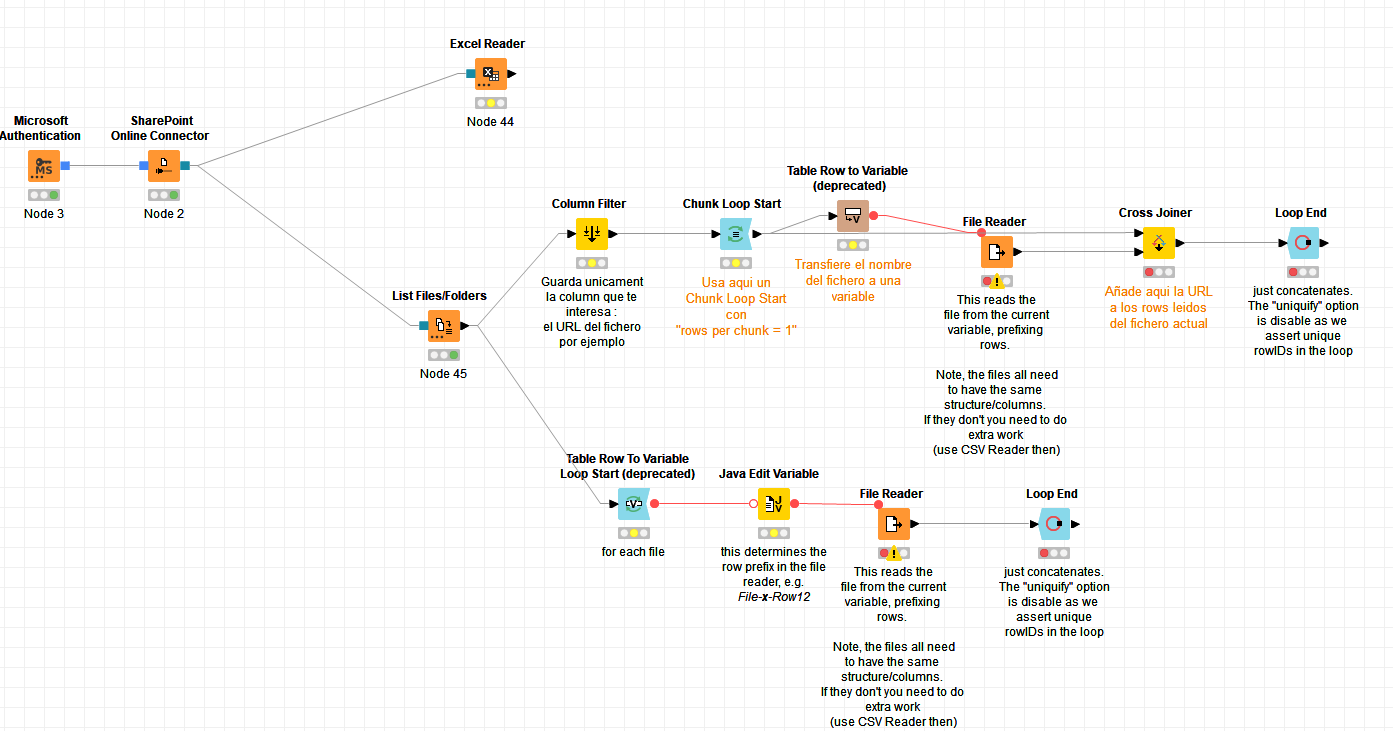
Adjunto un esquema , utilizando los datos del flujo de ejemplo que encontré en el Hub.
Básicamente lo que voy buscando es conseguir que sobre la información que obtendría leyendo la biblioteca de SHP, en donde están todos los ficheros con igual estructura y que con un excel reader obtengo en un único fichero, se pueda incluir un campo que contenga el nombre de cada fichero que contribuye a la formación de ese fichero único. ejemplo.xlsx (10.7 KB)
Muchas gracias.
A cada iteracion del lazo, el chunk loop lee un solo nombre de la lista de ficheros y el “Table Row to Variable” lo convierte en variable" para que el “Excel Reader” pueda leerlo. Adjuntar el nombre del fichero a las lineas (rows) leidas, se hace por medio de un nodo “Cross Joiner” que adjunta el nombre del fichero actual a todas las lineas del tablero leido. Al final todo se concatena por lineas. Evidentemente, otras soluciones son posibles en KNIME.
Muchas de antemano por el interés. El resultado mostrado es el que voy buscando.
Encuentro una diferencia con mi escenario, justo en el arranque. En el ejemplo, el nodo list files tiene dos campos : location y url
Desconozco qué variable alternativa a temp_path utilizar dentro del nodo list file y si como alternativa a url , que en mi caso no existe, puedo utilizar otra relativa al campo “path”.
Como verás tengo bastante lío con las variables a emplear. No sé si tiene encaje el ejemplo al venir el origen de datos de SHP
Normalmente, si tu fichero esta en el “Path” que me indicas y puedes leerlo usando ese Path con un nodo Excel Reader, entonces lo unico que tienes que hacer es usar la variable “Path”. Pero ya veo cual es el problema y es que estas leyendo tus ficheros Excel de forma remota a traves de un SharePoint.
Por otro lado, debes remplazar el nodo “File Reader” por un “Excel Reader”. Dentro del “Excel Reader” debieras normalmente poder configurar el acceso de la misma manera pero con respecto al “Mount Point” de tu “SharePoint”:
Tienes que remplazar el “File Reader” por un “Excel Reader” y dentro, configurar “Read From:” como “Mountpoint” con tu punto de montaje del Sharepoint que pienso debiera aparecer en las opciones (opcion donde pone “knime-temps-space”. Siento no poder ser mas claro ya que yo no uso SharePoint, asi que no puedo serte de mas ayuda ya que no puedo probarlo en mi instalacion. Espero que estas explicaciones te ayuden a resolverlo o que otros en el forum puedan ayudarte.
Saludos,
Ael
PS: Para este problema un poco especial, te aconsejo que formules tu pregunta en ingles ya que tendras mucha mas audiencia y respuestas. Espero sino que alguien te pueda responder en español. Suerte !
Hola @juanqui3C
Han pasado varios días pero estaba viendo posts que no parecían tener solución…
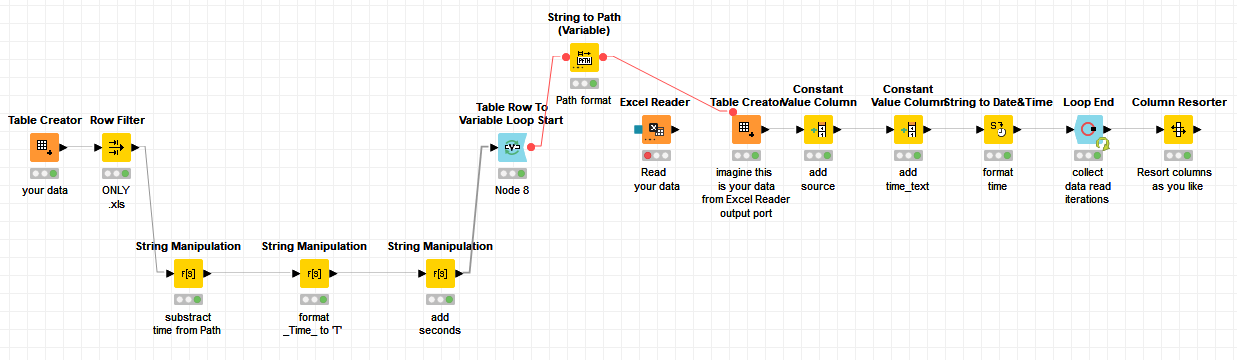
Te adjunto un workflow que puede servirte de ejemplo para lo que intentas hacer.
El tema de la lectura de Excel desde Sharepoint puede ser complejo porque el servidor rechace la conexión de lectura… si la dimensión del trabajo lo permite, intenta leer desde tu sistema local en OneDrive