Presento una base el cual presenta para el campo RUT de tipo string distintos largo o conteo de caracteres, es decir existen registros con largo 14,12,10,9,8 y 7. Se adjunta evidencia
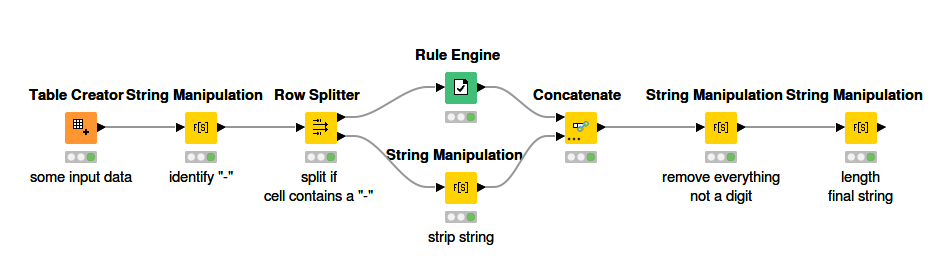
Logre realizar transformación realizando filtros y dividiendo la base mediante el nodo row splinter, con la finalidad de arreglar el campo a la estructura correcta el cual debe ser de largo 8 o 7. Se adjunta evidencia
Presento el resultado en excel de como debe quedar el campo RUT con un largo de 8 o 7 según corresponda
Como se expresa arriba realicé las transformaciones ocupando el nodo row splinter pero con una mala eficiencia en el proceso y tardando tiempo , por lo anterior consulto si existe una forma más optima de hacer lo mismo ocupando varibables o bucles?
Saludos y agradecido de la ayuda que me puedan dar
Hello @HansS thank you very much for the prompt response.
Apply what is indicated but unfortunately it does not perform an adequate cleaning and transformation since it continues to maintain lengths greater than 8 characters. The correct thing is that it is between a length of 7 to 8.
A screen print of how the data should look is attached. What is marked in yellow is the correct result for each record
Hola @Pedro87
This option worked right for me (if all your causalities are represented in your example). Otherwise @HansS option will be more flexible.
Tested ‘String Manipulation’ node with the following code:
Hello @gonhaddock and @HansS very good afternoon, first of all thank you for the help you have given me.
I tell you that I am going to attach the workflow with the most real data since I thought that with the example that I showed you my requirement could be developed correctly, I apologize for the above in case I did not explain myself well
In the attached flow, and within the metadonode, the different transformations that I made are developed and that demonstrate the different casuistry of transformation and cleaning occupying the row splinter node KNIME_project.knwf (138.6 KB)
Hola @Pedro87
Thanks for the source, now its more clear and more simpler. As the previous example didn’t represent the full picture, in fact it didn’t match the rules that you apply in the workflow.
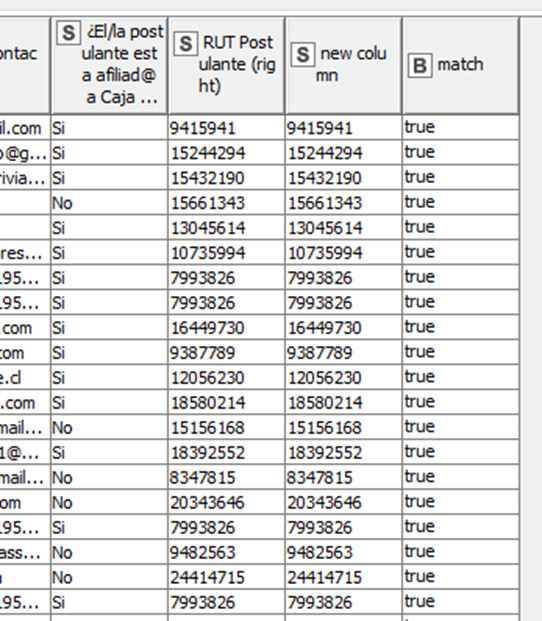
Using the following code in a ‘String Manipulation’ node, I tested a 100% match control:
The $RUT Postulante$ is your WF’s generated column in the picture, $new column$ is the regex generated one. At the right hand side is the $match$ control column.
Hello @gonhaddock, good morning, wishing you a great weekend, I want to thank you for the help you have given me.
I was reviewing the result of the formula and I only find a small problem. In the flow I shared in row 225 of node called string manipulation number 18 (screen print attached).
From the field “Rut Applicant” the data 4885633 is correct, therefore it should not be modified. With the above everything would be ok.
Finally I would like to understand if it is possible as an additional point what the formula in the string manipulation node does to be able to reuse the solution in the future.
Hola @Pedro87 , you are right
Let’s start from final including a correction for Row 225 use case:
I will split the formula in different terms. Aiming to simplify, you may take into account that; when typing regex in string manipulation node, you have to add a scape bar [ \ ] just before regex coding, i will remove them for the steps… the formula rules are split by the logical operator OR [ | ] that is represented as [ \| ] in string manipulation.
The corrected formula is one element longer so it goes from $1 to $8.
The first step [ $1 ] has been just added NEW for the Row 225 issue; and represents a string of 7 digit [ d ] characters. $1 comprehends the capturing group between brackets. From now on (all steps) [ ^ ] represents the string start and [ $ ] represents the string end, which means literality. ^(\d{7})$
The second step [ $2 ] is a string of 7 characters, being the last [ \S ] any character, in this case a non digit character as the 7 digits case was covered in first step rule. The $2 represents only the capturing group of digits. ^(\d{6})\S$
So on with the following rules for 8 and 9 string characters length. Being the last one [ \S ] deprecated. These are rules $3 and $4 (capturing groups) ^(\d{7})\S$ ^(\d{8})\S$
This rule is referred to any string starting with digits and including a dash [-] character. Being the digits included in capturing group $5, and deprecating the dash and whatever afterwards [ .* ] ^(\d+)[-].*$
This last rule capture three groups ($6, $7, $8) of digit separated by a dot character [ . ] deprecating the dots and any non non digit included in the 3rd group, and whatever afterwards (spaces, dash, other digits…) ^(\d+)\.+(\d+)\.+(\d+).*$